Deconstructing Instruction-Following: A New Benchmark for Granular Evaluation of Large Language Model Instruction Compliance Abilities
作者: Alberto Purpura, Li Wang, Sahil Badyal, Eugenio Beaufrand, Adam Faulkner
分类: cs.AI
发布日期: 2026-01-26
备注: Paper accepted to EACL 2026
💡 一句话要点
提出MOSAIC基准,用于细粒度评估大语言模型指令遵循能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 指令遵循 基准测试 细粒度评估 约束生成
📋 核心要点
- 现有基准测试无法有效区分LLM的指令遵循能力与任务完成度,难以反映真实应用场景。
- MOSAIC框架通过动态生成包含多个约束的数据集,实现对LLM指令遵循能力的细粒度评估。
- 实验表明,指令遵循能力受约束类型、数量和位置影响,并揭示了模型间的差异和指令间的相互作用。
📝 摘要(中文)
可靠地确保大型语言模型(LLM)遵循复杂指令是一个关键挑战,因为现有的基准通常无法反映真实世界的应用,或者无法将指令遵循与任务成功区分开来。我们引入了MOSAIC(MOdular Synthetic Assessment of Instruction Compliance),这是一个模块化框架,它使用动态生成的数据集,包含多达20个面向应用的生成约束,从而能够对这种能力进行细粒度和独立的分析。我们基于这个新基准对来自不同系列的五个LLM的评估表明,指令遵循不是一种单一的能力,而是随着约束类型、数量和位置的不同而显著变化。该分析揭示了特定于模型的弱点,揭示了指令之间的协同和冲突交互,并识别出不同的位置偏差,例如首因效应和近因效应。这些细粒度的见解对于诊断模型故障以及开发更可靠的LLM至关重要,这些LLM适用于需要严格遵守复杂指令的系统。
🔬 方法详解
问题定义:现有的大语言模型评估基准在评估指令遵循能力时存在局限性。它们往往难以区分模型是否真正理解并遵循了指令,还是仅仅通过其他方式完成了任务。此外,现有基准通常无法提供细粒度的评估,难以分析模型在处理不同类型、数量和位置的约束时的表现。因此,如何设计一个能够独立、细粒度地评估LLM指令遵循能力的基准是一个重要的挑战。
核心思路:MOSAIC的核心思路是通过模块化的方式生成包含多个约束的数据集,并设计相应的评估指标,从而实现对LLM指令遵循能力的细粒度分析。这种方法允许研究人员独立地评估模型在处理不同约束时的表现,并分析约束之间的相互作用。通过动态生成数据集,可以灵活地控制约束的类型、数量和位置,从而全面地评估模型的指令遵循能力。
技术框架:MOSAIC框架主要包含以下几个模块:1) 约束生成模块:用于生成各种类型的约束,例如格式约束、内容约束、风格约束等。2) 数据集生成模块:根据生成的约束,动态地生成包含多个约束的数据集。3) 模型评估模块:使用生成的数据集对LLM进行评估,并计算相应的评估指标,例如约束满足率、指令遵循准确率等。4) 结果分析模块:对评估结果进行分析,揭示模型在处理不同约束时的表现,并分析约束之间的相互作用。
关键创新:MOSAIC的关键创新在于其模块化的设计和动态数据集生成方法。通过模块化的设计,可以灵活地添加、修改和删除约束,从而适应不同的评估需求。通过动态数据集生成方法,可以灵活地控制约束的类型、数量和位置,从而全面地评估模型的指令遵循能力。此外,MOSAIC还提供了一套细粒度的评估指标,可以更准确地评估模型的指令遵循能力。
关键设计:MOSAIC框架的关键设计包括:1) 约束类型的选择:论文选择了20种面向应用的生成约束,涵盖了格式、内容、风格等多个方面。2) 数据集生成策略:论文采用了一种动态的数据集生成策略,可以根据不同的评估需求生成不同类型、数量和位置的约束。3) 评估指标的设计:论文设计了一套细粒度的评估指标,例如约束满足率、指令遵循准确率等,可以更准确地评估模型的指令遵循能力。
🖼️ 关键图片
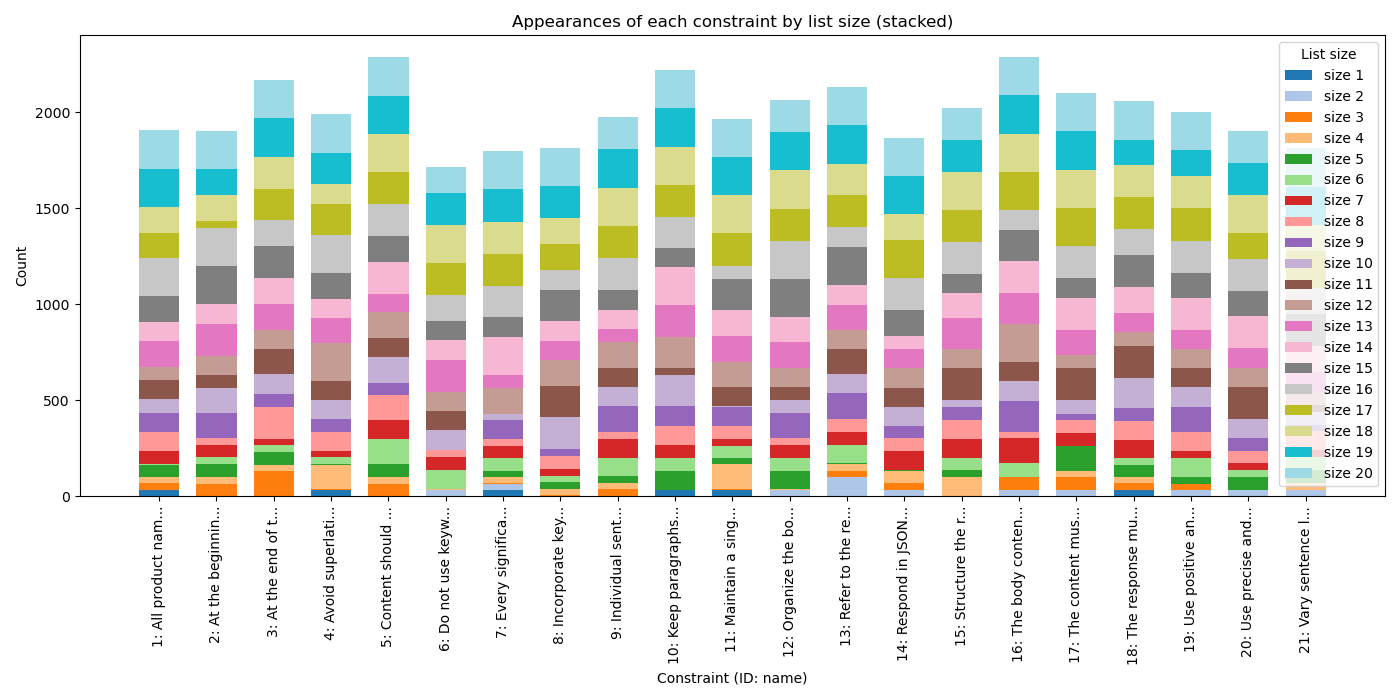
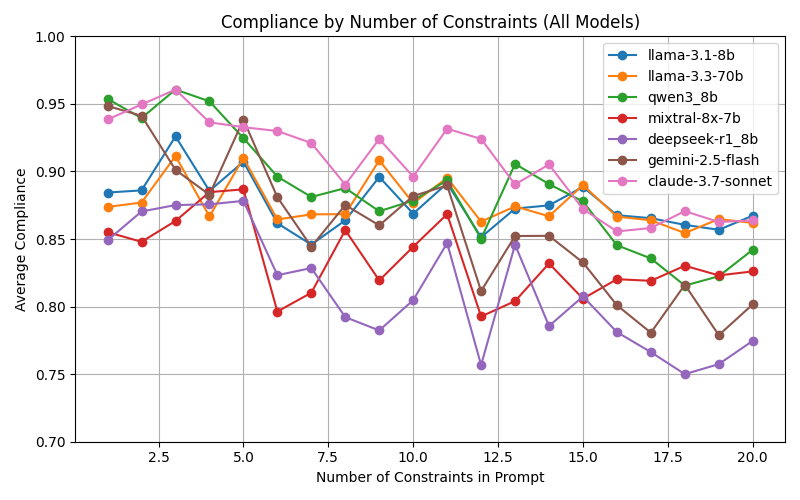
📊 实验亮点
通过MOSAIC基准对五个LLM的评估表明,指令遵循能力并非单一能力,而是随约束类型、数量和位置显著变化。研究揭示了模型特定弱点,发现了指令间的协同和冲突,并识别出首因效应和近因效应等位置偏差。例如,某些模型在处理否定约束时表现较差,而另一些模型则更容易受到首因效应的影响。
🎯 应用场景
该研究成果可应用于开发更可靠的LLM系统,尤其是在需要严格遵守复杂指令的场景中,例如自动化报告生成、代码生成、智能助手等。通过MOSAIC基准,可以诊断模型在指令遵循方面的弱点,并指导模型改进,提升LLM在实际应用中的可靠性和安全性。此外,该基准也可以用于比较不同LLM的指令遵循能力,为用户选择合适的模型提供参考。
📄 摘要(原文)
Reliably ensuring Large Language Models (LLMs) follow complex instructions is a critical challenge, as existing benchmarks often fail to reflect real-world use or isolate compliance from task success. We introduce MOSAIC (MOdular Synthetic Assessment of Instruction Compliance), a modular framework that uses a dynamically generated dataset with up to 20 application-oriented generation constraints to enable a granular and independent analysis of this capability. Our evaluation of five LLMs from different families based on this new benchmark demonstrates that compliance is not a monolithic capability but varies significantly with constraint type, quantity, and position. The analysis reveals model-specific weaknesses, uncovers synergistic and conflicting interactions between instructions, and identifies distinct positional biases such as primacy and recency effects. These granular insights are critical for diagnosing model failures and developing more reliable LLMs for systems that demand strict adherence to complex instructions.