TAM-Eval: Evaluating LLMs for Automated Unit Test Maintenance
作者: Elena Bruches, Vadim Alperovich, Dari Baturova, Roman Derunets, Daniil Grebenkin, Georgy Mkrtchyan, Oleg Sedukhin, Mikhail Klementev, Ivan Bondarenko, Nikolay Bushkov, Stanislav Moiseev
分类: cs.SE, cs.AI
发布日期: 2026-01-26
备注: Accepted for publication at the 9th Workshop on Validation, Analysis and Evolution of Software Tests (VST 2026), co-located with the the 33rd IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER 2026)
🔗 代码/项目: GITHUB
💡 一句话要点
TAM-Eval:用于评估LLM在自动化单元测试维护中的性能的框架与基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动化测试 大型语言模型 软件维护 测试评估 基准测试
📋 核心要点
- 现有方法在单元测试中主要关注孤立的测试生成,忽略了测试套件维护这一更具挑战性的实际问题。
- TAM-Eval框架通过提供一个包含创建、修复和更新测试套件等场景的基准,来评估LLM在测试维护中的性能。
- 实验结果表明,现有LLM在实际测试维护任务中能力有限,对测试有效性的提升并不显著。
📝 摘要(中文)
大型语言模型(LLM)在软件工程领域展现出潜力,但其在单元测试中的应用主要局限于孤立的测试生成或oracle预测,忽略了测试套件维护这一更广泛的挑战。我们提出了TAM-Eval(测试自动化维护评估),一个旨在评估模型在创建、修复和更新测试套件这三个核心测试维护场景中性能的框架和基准。与之前仅限于函数级别任务的工作不同,TAM-Eval在测试文件级别运行,同时在隔离评估期间保持对完整存储库上下文的访问,从而更好地反映了真实的维护工作流程。我们的基准包含来自Python、Java和Go项目的1,539个自动提取和验证的场景。TAM-Eval支持对原始LLM和agentic工作流程的系统无关评估,使用基于测试套件通过率、代码覆盖率和变异测试的无参考协议。实验结果表明,最先进的LLM在实际的测试维护过程中能力有限,并且仅在测试有效性方面产生边际改进。我们将TAM-Eval作为开源框架发布,以支持未来在自动化软件测试方面的研究。我们的数据和代码可在https://github.com/trndcenter/TAM-Eval公开获取。
🔬 方法详解
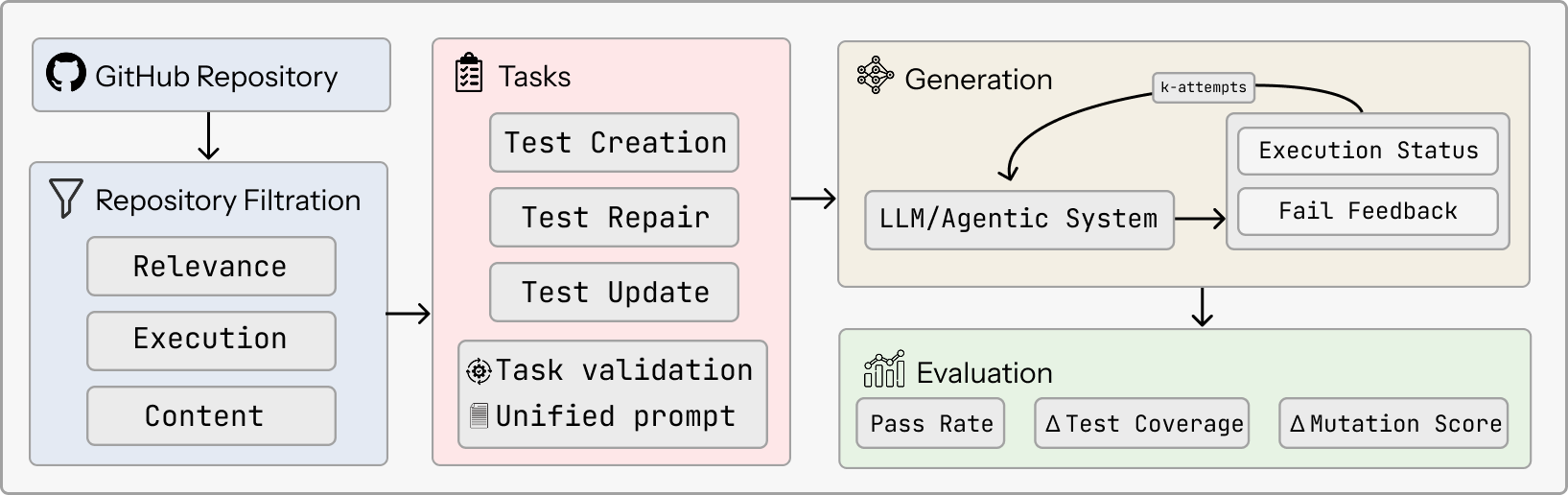
问题定义:论文旨在解决大型语言模型(LLM)在自动化单元测试维护中的评估问题。现有方法主要集中在孤立的测试用例生成或oracle预测,缺乏对整个测试套件维护流程的全面评估,无法反映真实软件开发场景的需求。现有方法忽略了测试套件的创建、修复和更新等关键维护环节,导致LLM在实际应用中的效果不佳。
核心思路:论文的核心思路是构建一个更贴近实际软件开发流程的评估框架,即TAM-Eval。该框架通过提供包含多种测试维护场景(创建、修复、更新)的基准数据集,并采用无参考评估协议,来全面评估LLM在测试套件维护中的能力。TAM-Eval的设计目标是弥合现有评估方法与实际应用之间的差距,从而推动LLM在自动化软件测试领域的更有效应用。
技术框架:TAM-Eval框架主要包含以下几个核心组成部分:1) 基准数据集:包含来自Python、Java和Go项目的1539个自动提取和验证的测试维护场景,覆盖创建、修复和更新测试套件等任务。2) 评估协议:采用无参考评估协议,基于测试套件通过率、代码覆盖率和变异测试等指标来评估LLM的性能。3) 系统无关性:支持对原始LLM和agentic工作流程的评估,具有良好的通用性。4) 开源实现:提供开源代码和数据,方便研究人员进行扩展和改进。
关键创新:TAM-Eval的关键创新在于其评估的全面性和真实性。与现有方法相比,TAM-Eval在测试文件级别进行评估,并保持对完整代码仓库上下文的访问,从而更真实地反映了实际的软件维护工作流程。此外,TAM-Eval采用无参考评估协议,避免了对人工标注的依赖,提高了评估的效率和可扩展性。
关键设计:TAM-Eval的关键设计包括:1) 测试场景的自动提取和验证方法,确保基准数据集的质量和规模。2) 无参考评估协议的设计,包括测试套件通过率、代码覆盖率和变异测试等指标的选取和计算方法。3) 框架的模块化设计,方便研究人员进行扩展和定制,例如添加新的测试维护场景或评估指标。
🖼️ 关键图片
📊 实验亮点
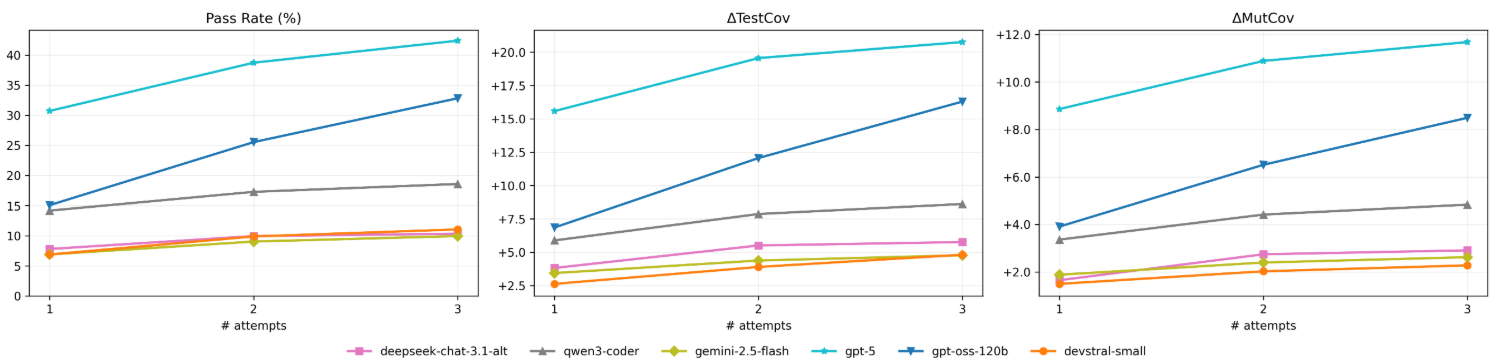
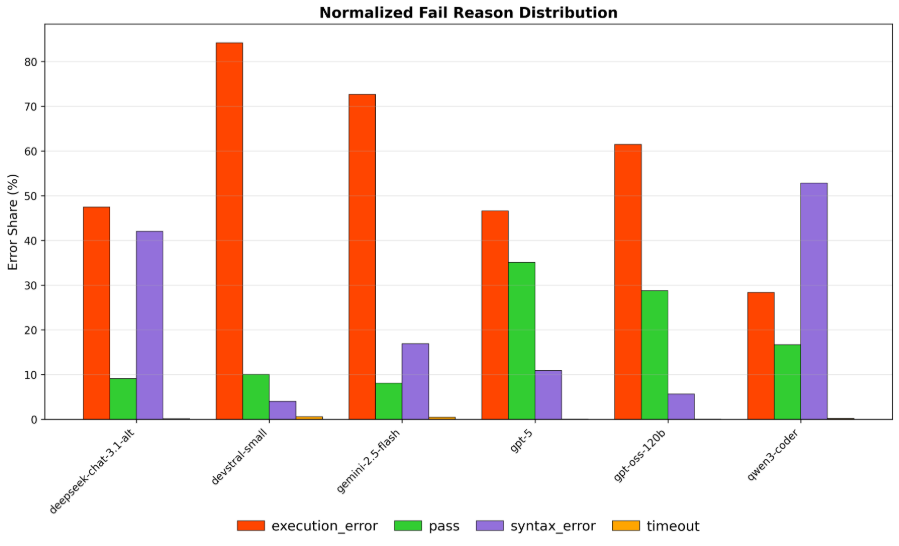
实验结果表明,当前最先进的LLM在实际的测试维护过程中能力有限,仅在测试有效性方面产生边际改进。例如,在某些测试维护任务中,LLM的性能提升幅度仅为几个百分点,远低于预期。这些结果表明,LLM在自动化软件测试领域仍有很大的提升空间,需要进一步的研究和改进。
🎯 应用场景
TAM-Eval的研究成果可应用于自动化软件测试、持续集成/持续交付(CI/CD)流程以及软件质量保证等领域。通过使用TAM-Eval评估LLM在测试维护中的能力,可以帮助开发人员选择更合适的模型,并优化测试流程,从而提高软件质量和开发效率。未来,TAM-Eval可以扩展到支持更多编程语言和测试框架,并集成到实际的软件开发工具链中。
📄 摘要(原文)
While Large Language Models (LLMs) have shown promise in software engineering, their application to unit testing remains largely confined to isolated test generation or oracle prediction, neglecting the broader challenge of test suite maintenance. We introduce TAM-Eval (Test Automated Maintenance Evaluation), a framework and benchmark designed to evaluate model performance across three core test maintenance scenarios: creation, repair, and updating of test suites. Unlike prior work limited to function-level tasks, TAM-Eval operates at the test file level, while maintaining access to full repository context during isolated evaluation, better reflecting real-world maintenance workflows. Our benchmark comprises 1,539 automatically extracted and validated scenarios from Python, Java, and Go projects. TAM-Eval supports system-agnostic evaluation of both raw LLMs and agentic workflows, using a reference-free protocol based on test suite pass rate, code coverage, and mutation testing. Empirical results indicate that state-of-the-art LLMs have limited capabilities in realistic test maintenance processes and yield only marginal improvements in test effectiveness. We release TAM-Eval as an open-source framework to support future research in automated software testing. Our data and code are publicly available at https://github.com/trndcenter/TAM-Eval.