ShopSimulator: Evaluating and Exploring RL-Driven LLM Agent for Shopping Assistants
作者: Pei Wang, Yanan Wu, Xiaoshuai Song, Weixun Wang, Gengru Chen, Zhongwen Li, Kezhong Yan, Ken Deng, Qi Liu, Shuaibing Zhao, Shaopan Xiong, Xuepeng Liu, Xuefeng Chen, Wanxi Deng, Wenbo Su, Bo Zheng
分类: cs.AI
发布日期: 2026-01-26
🔗 代码/项目: GITHUB
💡 一句话要点
ShopSimulator:用于评估和探索强化学习驱动的LLM购物助手
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 电商购物助手 大型语言模型 强化学习 模拟环境 多轮对话
📋 核心要点
- 现有电商智能体研究缺乏统一的模拟环境,难以全面评估LLM在多轮对话、个性化推荐和产品辨析等方面的能力。
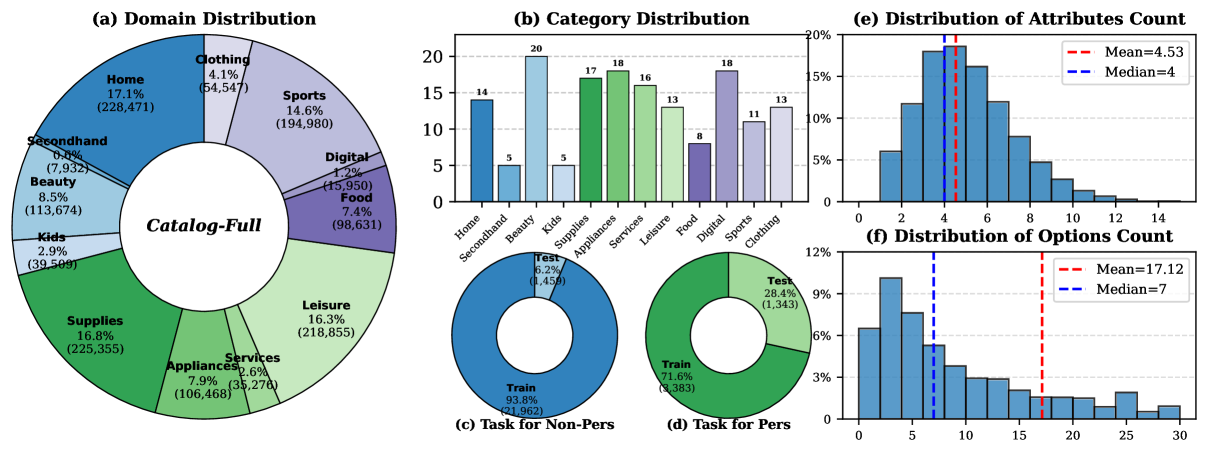
- 论文提出ShopSimulator,一个大规模中文购物环境,用于评估和训练LLM驱动的购物助手,支持多轮对话和复杂场景。
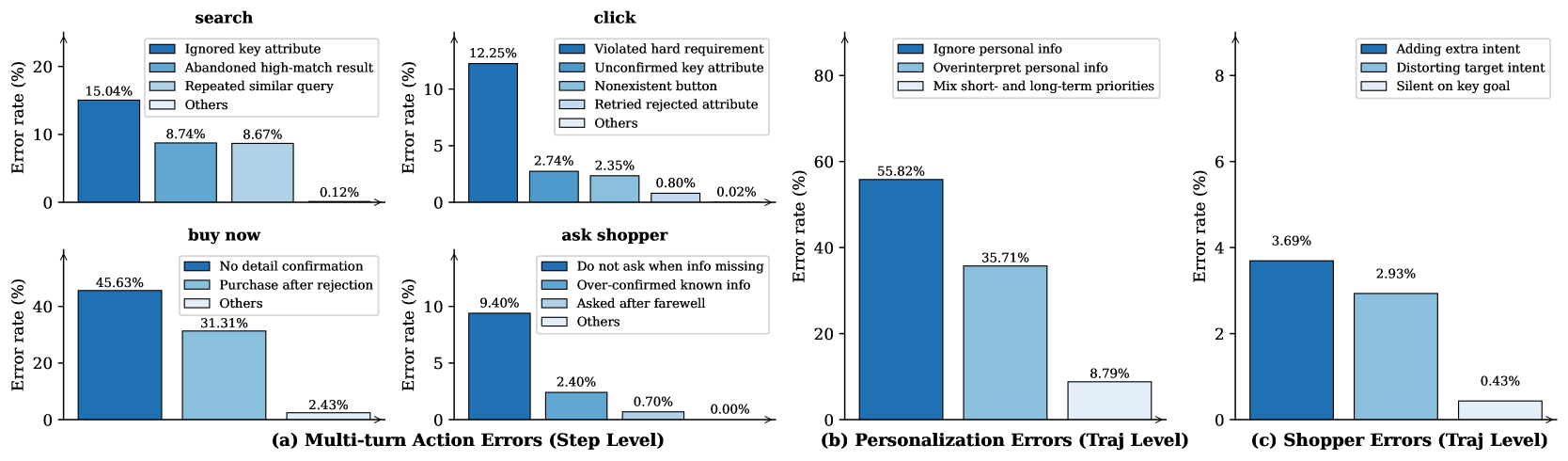
- 实验表明,现有LLM在ShopSimulator中表现不佳,通过监督微调和强化学习相结合,可以显著提升智能体的性能。
📝 摘要(中文)
基于大型语言模型(LLM)的智能体越来越多地应用于电子商务购物。为了执行彻底的、用户定制的产品搜索,智能体应该理解个人偏好,进行多轮对话,并最终检索和区分高度相似的产品。然而,现有的研究尚未提供一个统一的模拟环境来持续捕捉所有这些方面,并且总是只关注评估基准而没有训练支持。在本文中,我们介绍了ShopSimulator,一个大规模且具有挑战性的中文购物环境。利用ShopSimulator,我们评估了LLM在不同场景下的表现,发现即使是性能最好的模型也只能达到不到40%的完全成功率。错误分析表明,智能体在长轨迹中的深度搜索和产品选择方面存在困难,未能平衡个性化线索的使用,并且未能有效地与用户互动。进一步的训练探索为克服这些弱点提供了实践指导,监督微调(SFT)和强化学习(RL)的结合产生了显著的性能提升。代码和数据将在https://github.com/ShopAgent-Team/ShopSimulator上发布。
🔬 方法详解
问题定义:现有基于LLM的电商购物助手,在理解用户个性化偏好、进行多轮对话交互、以及区分相似商品方面存在不足。同时,缺乏一个统一的、大规模的模拟环境来全面评估和训练这些智能体,现有研究往往只关注评估,缺乏训练支持。
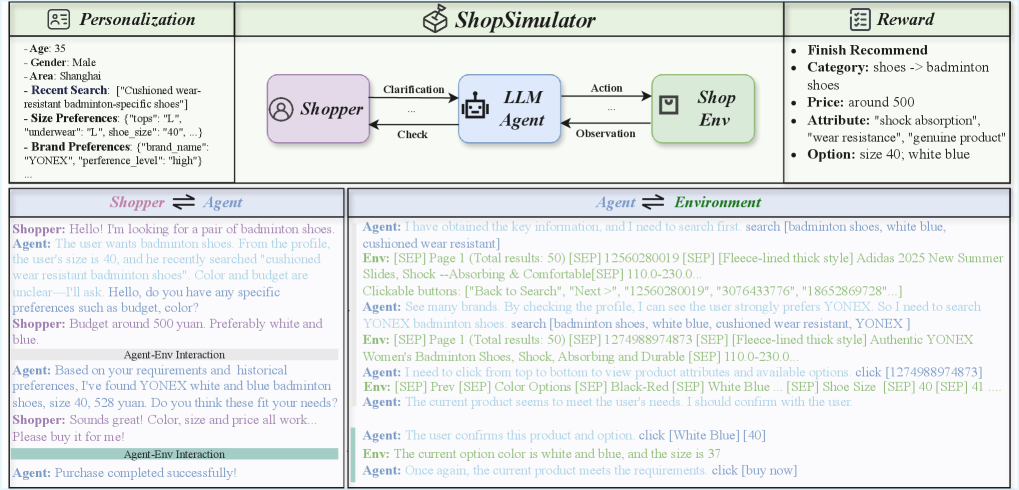
核心思路:构建一个大规模的中文购物模拟环境ShopSimulator,该环境能够模拟真实购物场景中的用户行为和商品信息,从而可以对LLM驱动的购物助手进行更全面的评估和训练。通过在该环境中进行训练,提升LLM在深度搜索、产品选择、个性化信息利用和用户交互方面的能力。
技术框架:ShopSimulator包含多个模块,用于模拟用户行为、商品信息和对话流程。具体架构细节未知,但核心在于提供一个可交互的购物环境,允许LLM智能体与模拟用户进行多轮对话,并根据用户需求进行商品搜索和推荐。该框架支持对LLM智能体进行评估和训练,通过奖励机制鼓励智能体更好地满足用户需求。
关键创新:主要创新在于构建了一个大规模、具有挑战性的中文购物模拟环境ShopSimulator,该环境能够更真实地模拟电商购物场景,从而可以更有效地评估和训练LLM驱动的购物助手。与以往研究相比,ShopSimulator不仅提供评估基准,还支持智能体的训练,为提升LLM在电商领域的应用能力提供了新的途径。
关键设计:论文采用了监督微调(SFT)和强化学习(RL)相结合的训练方法。首先,使用SFT对LLM进行预训练,使其具备基本的购物助手能力。然后,使用RL对LLM进行进一步的优化,使其能够更好地与用户进行交互,并根据用户需求进行商品推荐。具体的参数设置、损失函数和网络结构等技术细节未知。
🖼️ 关键图片
📊 实验亮点
实验结果表明,即使是性能最好的LLM在ShopSimulator中也只能达到不到40%的完全成功率,表明现有模型在复杂购物场景中仍存在不足。通过监督微调(SFT)和强化学习(RL)相结合的训练方法,可以显著提升智能体的性能,具体提升幅度未知,但表明该方法具有较好的应用前景。
🎯 应用场景
该研究成果可应用于电商平台的智能购物助手开发,提升用户购物体验,提高商品转化率。通过模拟真实购物场景,可以更有效地训练和评估智能体,降低开发成本。未来,该技术还可扩展到其他领域的智能助手应用,例如旅游、教育等。
📄 摘要(原文)
Large language model (LLM)-based agents are increasingly deployed in e-commerce shopping. To perform thorough, user-tailored product searches, agents should interpret personal preferences, engage in multi-turn dialogues, and ultimately retrieve and discriminate among highly similar products. However, existing research has yet to provide a unified simulation environment that consistently captures all of these aspects, and always focuses solely on evaluation benchmarks without training support. In this paper, we introduce ShopSimulator, a large-scale and challenging Chinese shopping environment. Leveraging ShopSimulator, we evaluate LLMs across diverse scenarios, finding that even the best-performing models achieve less than 40% full-success rate. Error analysis reveals that agents struggle with deep search and product selection in long trajectories, fail to balance the use of personalization cues, and to effectively engage with users. Further training exploration provides practical guidance for overcoming these weaknesses, with the combination of supervised fine-tuning (SFT) and reinforcement learning (RL) yielding significant performance improvements. Code and data will be released at https://github.com/ShopAgent-Team/ShopSimulator.