AgentDrive: An Open Benchmark Dataset for Agentic AI Reasoning with LLM-Generated Scenarios in Autonomous Systems
作者: Mohamed Amine Ferrag, Abderrahmane Lakas, Merouane Debbah
分类: cs.AI
发布日期: 2026-01-23
备注: 16 pages
🔗 代码/项目: GITHUB
💡 一句话要点
AgentDrive:用于自动驾驶系统中Agentic AI推理的LLM生成场景开放基准数据集
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动驾驶 大型语言模型 基准数据集 Agentic AI 场景生成 推理评估 仿真 安全指标
📋 核心要点
- 现有自动驾驶Agentic AI模型缺乏大规模、结构化和安全关键的基准数据集,限制了其评估和训练。
- AgentDrive通过LLM生成30万个驾驶场景,并形式化分解场景空间,提供了一个全面的训练和评估平台。
- AgentDrive-MCQ基准测试涵盖五个推理维度,评估了50个LLM,揭示了专有模型和开放模型在不同推理能力上的差距。
📝 摘要(中文)
大型语言模型(LLMs)的快速发展激发了人们对其集成到自主系统中,以进行推理驱动的感知、规划和决策的兴趣。然而,由于缺乏大规模、结构化和安全关键的基准,评估和训练此类agentic AI模型仍然具有挑战性。本文介绍了AgentDrive,一个包含30万个LLM生成的驾驶场景的开放基准数据集,旨在用于在各种条件下训练、微调和评估自动驾驶agent。AgentDrive在七个正交轴上形式化了一个分解的场景空间:场景类型、驾驶员行为、环境、道路布局、目标、难度和交通密度。一个LLM驱动的prompt-to-JSON管道生成语义丰富、可用于仿真的规范,并针对物理和模式约束进行验证。每个场景都经过仿真rollout、替代安全指标计算和基于规则的结果标记。为了补充基于仿真的评估,我们引入了AgentDrive-MCQ,一个包含10万个问题的多项选择基准,涵盖五个推理维度:物理、策略、混合、场景和比较推理。我们对AgentDrive-MCQ上的五十个领先的LLM进行了大规模评估。结果表明,虽然专有的前沿模型在上下文和策略推理方面表现最佳,但先进的开放模型正在迅速缩小在结构化和物理基础推理方面的差距。我们在https://github.com/maferrag/AgentDrive发布了AgentDrive数据集、AgentDrive-MCQ基准、评估代码和相关材料。
🔬 方法详解
问题定义:现有自动驾驶系统中,Agentic AI模型的训练和评估面临缺乏大规模、结构化和安全关键基准数据集的挑战。这使得难以有效地训练和评估模型在各种复杂和真实的驾驶场景下的推理、规划和决策能力。现有方法难以覆盖足够广泛的场景类型、驾驶员行为和环境条件,从而限制了模型的泛化能力和安全性。
核心思路:AgentDrive的核心思路是利用大型语言模型(LLMs)生成大规模、多样化且结构化的驾驶场景,并将其形式化为一个分解的场景空间。通过LLM的强大生成能力,可以高效地创建大量具有语义信息的场景描述,并将其转化为可用于仿真的规范。这种方法能够克服手动创建场景的局限性,并提供一个更全面和可控的评估环境。
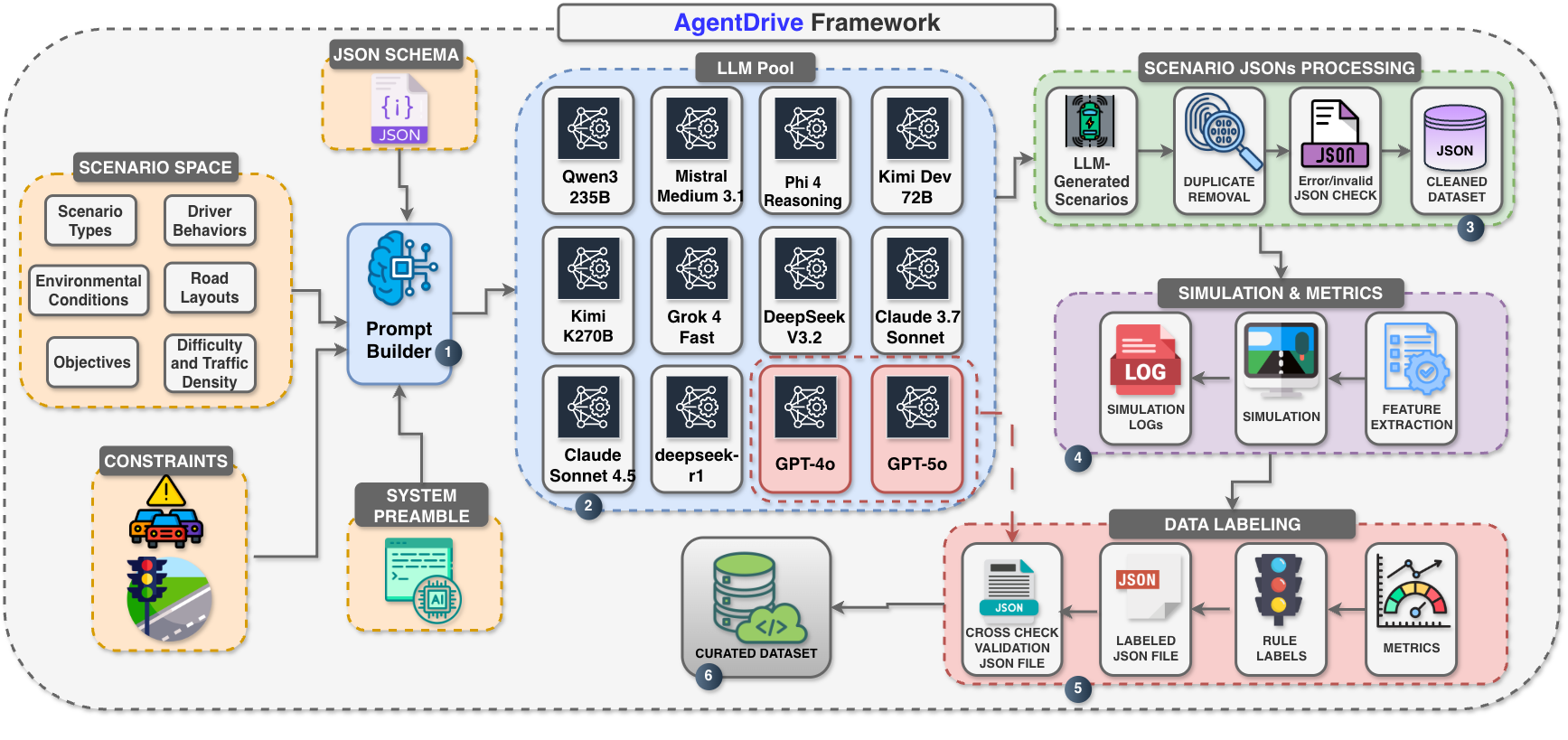
技术框架:AgentDrive的技术框架主要包括以下几个模块:1) LLM驱动的prompt-to-JSON管道,用于生成场景规范;2) 场景空间形式化,定义了七个正交轴(场景类型、驾驶员行为、环境、道路布局、目标、难度和交通密度);3) 仿真rollout和安全指标计算,用于评估agent在生成场景中的表现;4) AgentDrive-MCQ基准测试,用于评估LLM在不同推理维度上的能力。整个流程从LLM生成场景描述开始,经过验证和仿真,最终生成可用于训练和评估的数据集。
关键创新:AgentDrive的关键创新在于利用LLM生成大规模、结构化的驾驶场景,并将其形式化为一个可控的场景空间。这种方法不仅提高了场景生成的效率,还保证了场景的多样性和语义一致性。此外,AgentDrive-MCQ基准测试提供了一个评估LLM在自动驾驶相关推理能力上的平台,有助于推动LLM在自动驾驶领域的应用。
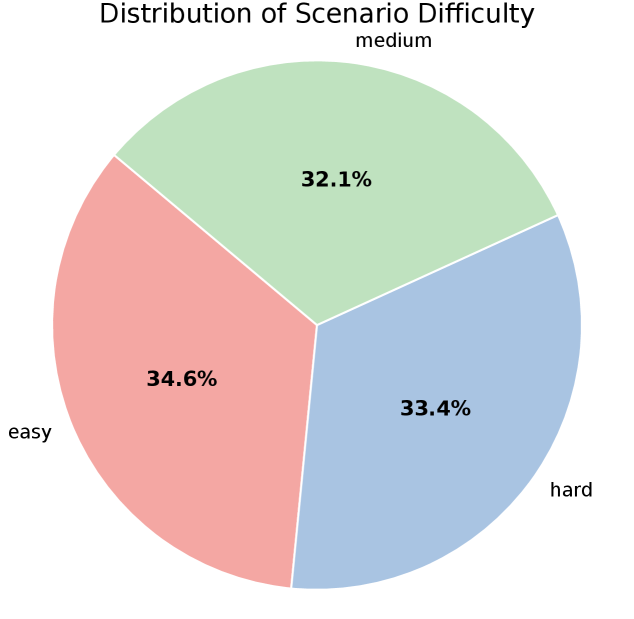
关键设计:AgentDrive的关键设计包括:1) 使用prompt-to-JSON管道,将自然语言描述转化为结构化的场景规范;2) 定义七个正交轴,以确保场景空间的多样性和可控性;3) 使用替代安全指标,如时间到碰撞(TTC)和最小间距(HD),来评估agent的安全性;4) AgentDrive-MCQ基准测试包含五个推理维度,每个维度包含不同难度级别的问题。
🖼️ 关键图片

📊 实验亮点
AgentDrive-MCQ基准测试结果显示,专有的前沿模型在上下文和策略推理方面表现最佳,但先进的开放模型正在迅速缩小在结构化和物理基础推理方面的差距。例如,在策略推理方面,专有模型的准确率平均高于开放模型10-15%。然而,在物理推理方面,一些先进的开放模型已经能够达到与专有模型相当的水平。
🎯 应用场景
AgentDrive数据集可广泛应用于自动驾驶系统的开发和评估,包括感知、规划、决策等模块。它能够帮助研究人员训练更鲁棒、更安全的自动驾驶agent,并评估LLM在自动驾驶推理方面的能力。此外,该数据集还可以用于开发新的安全指标和评估方法,推动自动驾驶技术的进步。
📄 摘要(原文)
The rapid advancement of large language models (LLMs) has sparked growing interest in their integration into autonomous systems for reasoning-driven perception, planning, and decision-making. However, evaluating and training such agentic AI models remains challenging due to the lack of large-scale, structured, and safety-critical benchmarks. This paper introduces AgentDrive, an open benchmark dataset containing 300,000 LLM-generated driving scenarios designed for training, fine-tuning, and evaluating autonomous agents under diverse conditions. AgentDrive formalizes a factorized scenario space across seven orthogonal axes: scenario type, driver behavior, environment, road layout, objective, difficulty, and traffic density. An LLM-driven prompt-to-JSON pipeline generates semantically rich, simulation-ready specifications that are validated against physical and schema constraints. Each scenario undergoes simulation rollouts, surrogate safety metric computation, and rule-based outcome labeling. To complement simulation-based evaluation, we introduce AgentDrive-MCQ, a 100,000-question multiple-choice benchmark spanning five reasoning dimensions: physics, policy, hybrid, scenario, and comparative reasoning. We conduct a large-scale evaluation of fifty leading LLMs on AgentDrive-MCQ. Results show that while proprietary frontier models perform best in contextual and policy reasoning, advanced open models are rapidly closing the gap in structured and physics-grounded reasoning. We release the AgentDrive dataset, AgentDrive-MCQ benchmark, evaluation code, and related materials at https://github.com/maferrag/AgentDrive