Revisiting the Role of Natural Language Code Comments in Code Translation
作者: Monika Gupta, Ajay Meena, Anamitra Roy Choudhury, Vijay Arya, Srikanta Bedathur
分类: cs.SE, cs.AI
发布日期: 2026-01-23
💡 一句话要点
研究表明代码注释显著提升代码翻译质量,并提出COMMENTRA方法。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码翻译 自然语言处理 代码注释 大型语言模型 实证研究
📋 核心要点
- 现有代码翻译基准测试缺乏对代码注释的考虑,导致无法充分评估注释对翻译质量的影响。
- 论文核心思想是利用代码注释,特别是描述代码整体目的的注释,来提升代码翻译的准确性。
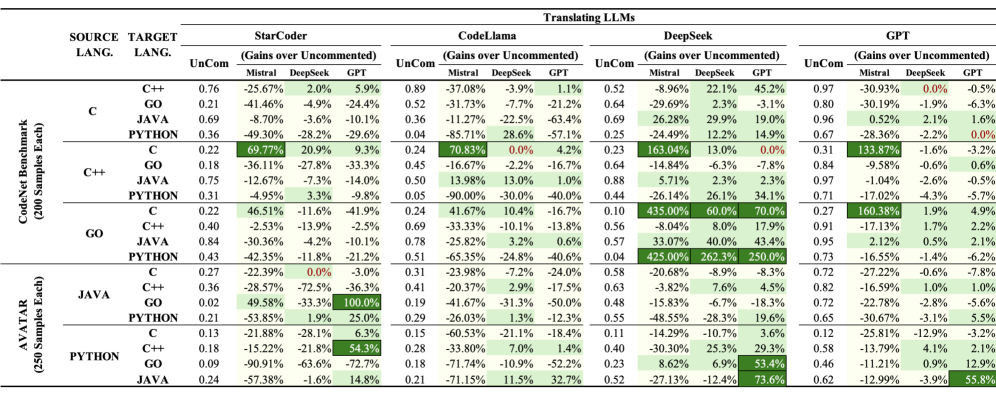
- 实验结果表明,代码注释能够显著提高翻译准确性,提出的COMMENTRA方法可以将基于LLM的代码翻译性能提高一倍。
📝 摘要(中文)
大型语言模型(LLMs)的出现为跨编程语言的自动代码翻译开辟了新纪元。由于大多数代码专用LLM都在GitHub等大型代码库中带有良好注释的代码上进行预训练,因此可以合理地假设自然语言代码注释有助于提高翻译质量。尽管注释具有潜在的相关性,但现有的代码翻译基准测试中大多缺少注释,导致其对翻译质量的影响未得到充分表征。在本文中,我们进行了一项大规模的实证研究,评估注释对翻译性能的影响。我们的分析涉及超过80,000次翻译,包括有注释和无注释的1100多个代码样本,涵盖五种不同编程语言之间的成对翻译:C、C++、Go、Java和Python。我们的结果提供了强有力的证据,表明代码注释,特别是那些描述代码整体目的而非逐行功能的注释,可以显著提高翻译准确性。基于这些发现,我们提出了一种代码翻译方法COMMENTRA,并证明它可以潜在地使基于LLM的代码翻译性能提高一倍。据我们所知,我们的研究在利用代码注释提高代码翻译准确性方面,是首个在全面性、规模和语言覆盖范围上都具有优势的研究。
🔬 方法详解
问题定义:论文旨在解决代码翻译任务中,如何有效利用代码注释来提升翻译质量的问题。现有方法在评估和利用代码注释方面存在不足,缺乏对注释类型和粒度的细致分析,导致注释的潜力未被充分挖掘。
核心思路:论文的核心思路是,并非所有注释都对代码翻译有益,描述代码整体目的的注释比逐行注释更有价值。通过分析不同类型的注释对翻译质量的影响,可以更有针对性地利用注释信息,从而提升翻译性能。
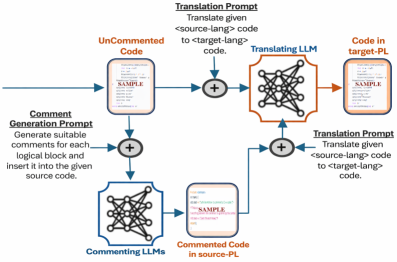
技术框架:论文提出了一种名为COMMENTRA的代码翻译方法。该方法首先分析代码中的注释,区分不同类型的注释(例如,描述代码目的的注释和描述代码实现的注释)。然后,COMMENTRA利用大型语言模型(LLM)进行代码翻译,并在翻译过程中更加关注描述代码目的的注释。最后,COMMENTRA对翻译结果进行评估和优化,以确保翻译的准确性和可读性。
关键创新:论文的关键创新在于,它首次大规模地实证研究了代码注释对代码翻译的影响,并提出了COMMENTRA方法,该方法能够有效地利用代码注释来提升翻译质量。此外,论文还对不同类型的注释进行了区分,并发现描述代码目的的注释比逐行注释更有价值。
关键设计:论文的关键设计包括:1) 构建了一个包含大量有注释和无注释代码样本的数据集,用于训练和评估代码翻译模型;2) 设计了一种注释类型分类器,用于区分不同类型的注释;3) 提出了一种基于LLM的代码翻译模型,该模型能够有效地利用代码注释信息;4) 设计了一种评估指标,用于衡量代码翻译的准确性和可读性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,代码注释能够显著提高代码翻译的准确性。具体来说,COMMENTRA方法在多个编程语言对之间的翻译任务上,可以将基于LLM的代码翻译性能提高一倍。此外,研究还发现,描述代码整体目的的注释比逐行注释更有助于提高翻译质量。
🎯 应用场景
该研究成果可应用于自动化代码迁移、跨平台软件开发、代码理解和文档生成等领域。通过提高代码翻译的准确性和效率,可以降低软件开发的成本,加速软件迭代,并促进不同编程语言之间的互操作性。未来,该研究可以进一步扩展到更多编程语言和更复杂的代码结构,为软件工程领域带来更深远的影响。
📄 摘要(原文)
The advent of large language models (LLMs) has ushered in a new era in automated code translation across programming languages. Since most code-specific LLMs are pretrained on well-commented code from large repositories like GitHub, it is reasonable to hypothesize that natural language code comments could aid in improving translation quality. Despite their potential relevance, comments are largely absent from existing code translation benchmarks, rendering their impact on translation quality inadequately characterised. In this paper, we present a large-scale empirical study evaluating the impact of comments on translation performance. Our analysis involves more than $80,000$ translations, with and without comments, of $1100+$ code samples from two distinct benchmarks covering pairwise translations between five different programming languages: C, C++, Go, Java, and Python. Our results provide strong evidence that code comments, particularly those that describe the overall purpose of the code rather than line-by-line functionality, significantly enhance translation accuracy. Based on these findings, we propose COMMENTRA, a code translation approach, and demonstrate that it can potentially double the performance of LLM-based code translation. To the best of our knowledge, our study is the first in terms of its comprehensiveness, scale, and language coverage on how to improve code translation accuracy using code comments.