LUMINA: Long-horizon Understanding for Multi-turn Interactive Agents
作者: Amin Rakhsha, Thomas Hehn, Pietro Mazzaglia, Fabio Valerio Massoli, Arash Behboodi, Tribhuvanesh Orekondy
分类: cs.AI
发布日期: 2026-01-23
💡 一句话要点
LUMINA:用于多轮交互Agent的长期理解能力研究
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多轮交互Agent 长期理解 Oracle反事实框架 语言模型 规划能力
📋 核心要点
- 现有大型语言模型在多轮交互任务中,缺乏有效的规划、状态跟踪和长上下文处理能力。
- 论文提出一种Oracle反事实框架,通过引入不同能力的Oracle来评估各项技能对Agent性能的影响。
- 实验结果表明,规划能力对Agent性能提升显著,而其他技能的有效性则依赖于环境和语言模型的特性。
📝 摘要(中文)
大型语言模型在许多孤立的任务上表现良好,但在需要规划、状态跟踪和长上下文处理等多项技能的多轮、长时程Agent问题上仍然面临挑战。本文旨在更好地理解提升这些底层能力对于此类任务成功的重要性。我们开发了一个用于多轮问题的Oracle反事实框架,该框架提出:如果Agent能够利用Oracle完美地执行特定任务,它的表现会如何?Agent性能因Oracle辅助而产生的变化使我们能够衡量这种Oracle技能在未来AI Agent发展中的重要性。我们引入了一套程序生成的、具有可调复杂性的类游戏任务。这些受控环境允许我们提供精确的Oracle干预,例如完美的规划或无懈可击的状态跟踪,并能够分离每个Oracle的贡献,而不会受到真实世界基准测试中存在的混淆效应的影响。我们的结果表明,虽然某些干预(例如,规划)始终如一地提高各种设置下的性能,但其他技能的用处取决于环境和语言模型的属性。我们的工作揭示了多轮Agent环境的挑战,以指导未来在AI Agent和语言模型开发中的努力。
🔬 方法详解
问题定义:现有的大型语言模型在处理多轮交互Agent任务时,面临着长期规划、状态跟踪和长上下文理解的挑战。这些任务通常需要Agent进行复杂的推理和决策,而现有模型在这些方面表现不足,导致任务完成效果不佳。现有方法难以有效评估不同能力对Agent性能的影响,缺乏针对性的改进方向。
核心思路:论文的核心思路是利用Oracle反事实框架,通过引入具有特定能力的Oracle来辅助Agent,并观察Agent性能的变化。这种方法可以量化不同能力对Agent性能的贡献,从而确定哪些能力是提升Agent性能的关键。通过分析Oracle辅助下的Agent行为,可以深入了解Agent的不足之处,并为未来的模型改进提供指导。
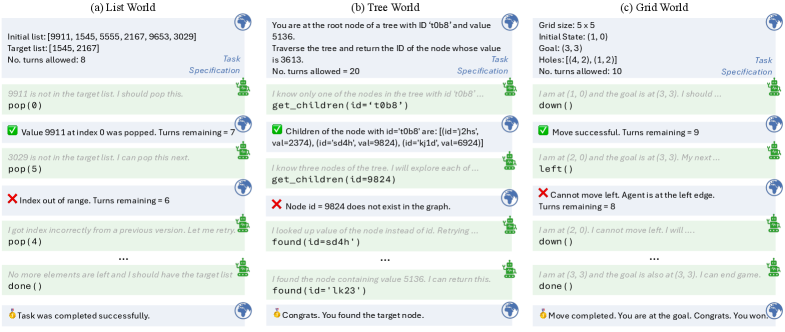
技术框架:该框架包含以下主要模块:1) 环境生成器:用于生成具有可调复杂度的类游戏任务环境。2) Agent:使用大型语言模型作为Agent,负责与环境进行交互并执行任务。3) Oracle:提供特定能力的完美辅助,例如完美的规划或状态跟踪。4) 评估模块:用于评估Agent在不同Oracle辅助下的性能。整个流程是,Agent在环境中进行多轮交互,Oracle在特定时刻提供辅助,评估模块记录Agent的性能指标。
关键创新:该论文的关键创新在于提出了Oracle反事实框架,用于评估不同能力对多轮交互Agent性能的影响。与传统的评估方法相比,该框架能够更精确地量化不同能力的贡献,并揭示Agent的不足之处。此外,论文还设计了一套程序生成的类游戏任务环境,可以灵活地调整任务的复杂度,从而更好地控制实验条件。
关键设计:环境生成器使用程序化生成方法,可以生成具有不同属性和复杂度的任务环境。Oracle的设计需要保证其提供的辅助是完美的,例如,完美的规划Oracle可以提供最优的行动序列。评估模块需要选择合适的性能指标,例如任务完成率、奖励值等,以全面评估Agent的性能。实验中,需要针对不同的任务环境和语言模型,选择合适的Oracle进行辅助,并分析Agent性能的变化。
🖼️ 关键图片

📊 实验亮点
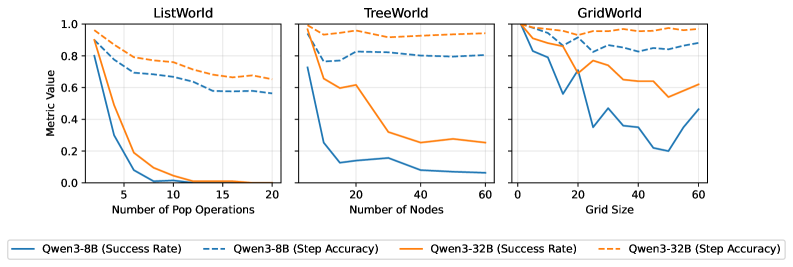
实验结果表明,规划能力对Agent性能提升最为显著,在不同设置下均能观察到性能提升。然而,状态跟踪等其他技能的有效性则依赖于环境和语言模型的特性。例如,在某些环境中,即使Agent拥有完美的状态跟踪能力,其性能也可能没有显著提升。这些结果揭示了多轮交互Agent环境的复杂性,并为未来的研究方向提供了指导。
🎯 应用场景
该研究成果可应用于开发更智能的对话Agent、游戏AI和机器人。通过了解不同能力对Agent性能的影响,可以更有针对性地改进模型,提升Agent在复杂环境中的表现。例如,可以利用该框架评估不同规划算法对机器人导航任务的影响,从而选择最优的算法。
📄 摘要(原文)
Large language models can perform well on many isolated tasks, yet they continue to struggle on multi-turn, long-horizon agentic problems that require skills such as planning, state tracking, and long context processing. In this work, we aim to better understand the relative importance of advancing these underlying capabilities for success on such tasks. We develop an oracle counterfactual framework for multi-turn problems that asks: how would an agent perform if it could leverage an oracle to perfectly perform a specific task? The change in the agent's performance due to this oracle assistance allows us to measure the criticality of such oracle skill in the future advancement of AI agents. We introduce a suite of procedurally generated, game-like tasks with tunable complexity. These controlled environments allow us to provide precise oracle interventions, such as perfect planning or flawless state tracking, and make it possible to isolate the contribution of each oracle without confounding effects present in real-world benchmarks. Our results show that while some interventions (e.g., planning) consistently improve performance across settings, the usefulness of other skills is dependent on the properties of the environment and language model. Our work sheds light on the challenges of multi-turn agentic environments to guide the future efforts in the development of AI agents and language models.