LLM is Not All You Need: A Systematic Evaluation of ML vs. Foundation Models for text and image based Medical Classification
作者: Meet Raval, Tejul Pandit, Dhvani Upadhyay
分类: cs.AI
发布日期: 2026-01-23
备注: 9 pages, 5 figures, 3 tables, paper accepted in AAIML'26 conference
💡 一句话要点
医学分类任务中,传统机器学习方法在文本和图像模态上优于微调后的LLM
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 医学分类 机器学习 大型语言模型 视觉语言模型 Transformer 参数高效微调 基准测试
📋 核心要点
- 现有方法难以确定LLM在医学分类任务中的优势,缺乏与传统机器学习的系统性对比。
- 论文通过统一的基准测试,对比了传统机器学习、Prompt-Based LLM/VLM和微调PEFT模型在医学分类任务中的表现。
- 实验结果表明,传统机器学习模型在大多数医学分类任务中表现最佳,而微调后的LLM表现最差。
📝 摘要(中文)
多模态视觉-语言模型(VLM)和大型语言模型(LLM)的结合为医学分类带来了新的可能性。本文通过使用四个公开数据集,涵盖文本和图像模态(二元和多类复杂度),对传统机器学习(ML)与现代基于Transformer的技术进行了严格的统一基准测试。我们评估了每个任务的三个模型类别:经典ML(LR、LightGBM、ResNet-50)、基于Prompt的LLM/VLM(Gemini 2.5)和微调的PEFT模型(LoRA适配的Gemma3变体)。所有实验都使用一致的数据分割和对齐的指标。结果表明,传统机器学习模型在大多数医学分类任务中始终如一地实现了最佳的整体性能,从而树立了高标准。对于结构化文本数据集尤其如此,经典模型表现出色。相比之下,LoRA调优的Gemma变体在所有文本和图像实验中始终表现最差,未能从提供的最小微调中泛化。然而,零样本LLM/VLM pipeline(Gemini 2.5)的结果好坏参半;它们在基于文本的任务中表现不佳,但在多类图像任务中表现出有竞争力的性能,与经典的ResNet-50基线相匹配。这些结果表明,在许多医学分类场景中,已建立的机器学习模型仍然是最可靠的选择。实验表明,基础模型并非普遍优越,并且参数高效微调(PEFT)的有效性高度依赖于自适应策略,因为最小的微调在本研究中被证明是有害的。
🔬 方法详解
问题定义:论文旨在评估在医学分类任务中,传统机器学习方法与基于Transformer的LLM/VLM方法的性能差异。现有方法缺乏对不同模型在文本和图像模态上的系统性对比,难以确定LLM在医学分类任务中的真正优势。
核心思路:论文的核心思路是通过构建一个统一的基准测试,在相同的数据集和评估指标下,对比传统机器学习模型、Prompt-Based LLM/VLM和微调PEFT模型的性能。通过这种方式,可以更客观地评估不同方法的优劣,并为医学分类任务选择合适的模型提供指导。
技术框架:论文的整体框架包括以下几个步骤: 1. 选择四个公开的医学数据集,涵盖文本和图像模态,以及二元和多类分类任务。 2. 选择三种模型类别:经典ML(LR、LightGBM、ResNet-50)、Prompt-Based LLM/VLMs(Gemini 2.5)和Fine-Tuned PEFT Models(LoRA-adapted Gemma3 variants)。 3. 对所有模型进行训练和评估,使用一致的数据分割和评估指标。 4. 分析实验结果,对比不同模型的性能,并得出结论。
关键创新:论文的关键创新在于构建了一个统一的基准测试,对传统机器学习方法和基于Transformer的LLM/VLM方法进行了系统性的对比。这有助于更客观地评估不同方法的优劣,并为医学分类任务选择合适的模型提供指导。此外,论文还发现,在某些情况下,传统机器学习方法在医学分类任务中优于微调后的LLM。
关键设计:论文的关键设计包括: 1. 数据集选择:选择了四个公开的医学数据集,涵盖文本和图像模态,以及二元和多类分类任务,以保证实验的全面性。 2. 模型选择:选择了三种具有代表性的模型类别,包括经典ML、Prompt-Based LLM/VLMs和Fine-Tuned PEFT Models,以保证实验的对比性。 3. 评估指标:使用了统一的评估指标,以保证实验的可比性。 4. 微调策略:使用了LoRA进行参数高效微调,并发现最小的微调在本研究中是有害的。
🖼️ 关键图片
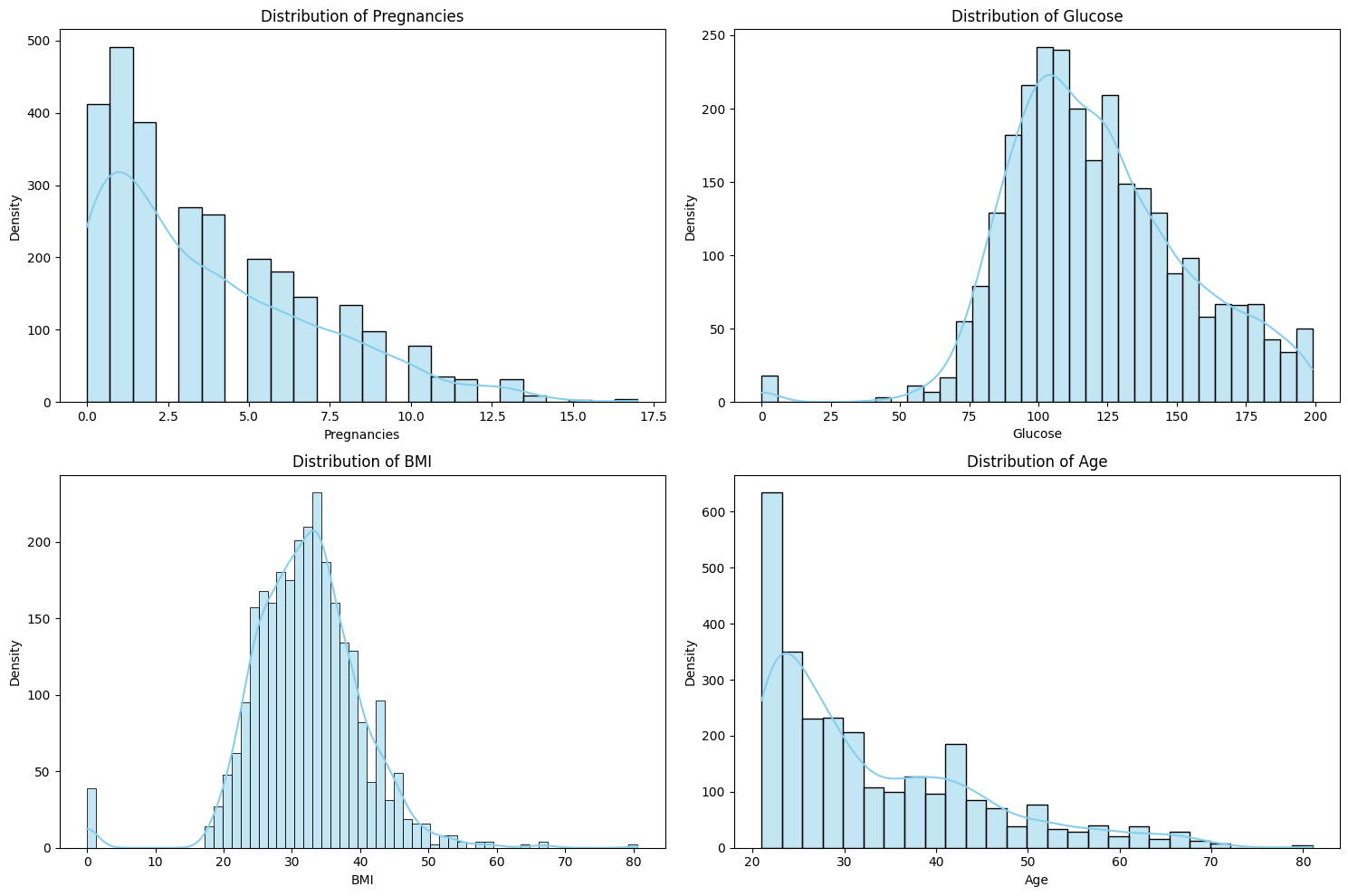
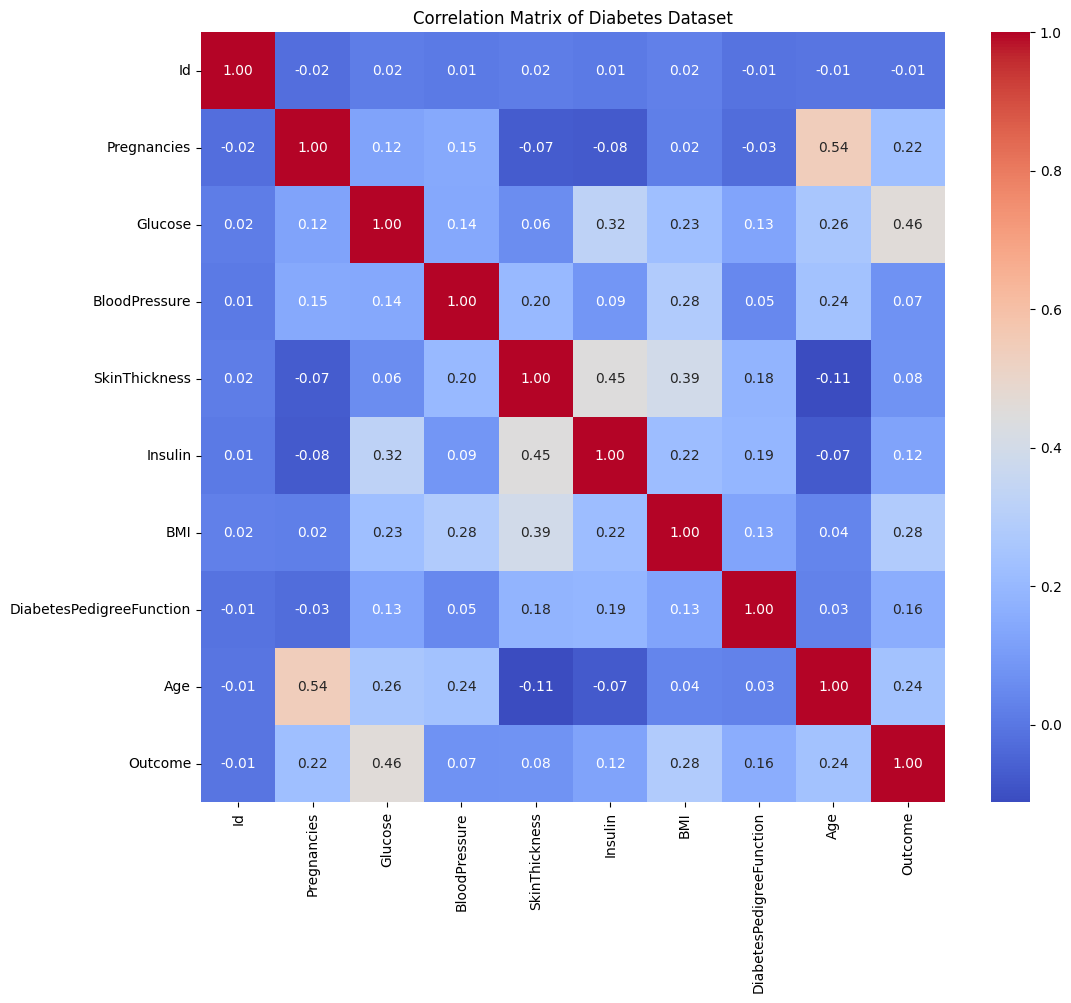
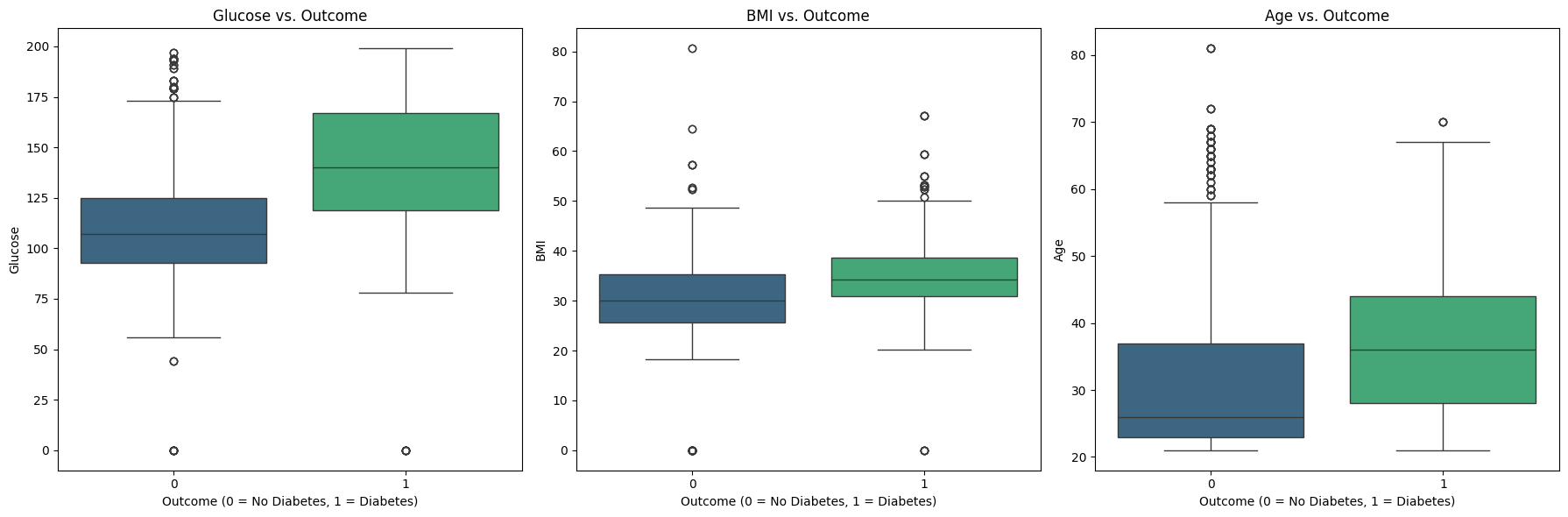
📊 实验亮点
实验结果表明,传统机器学习模型在大多数医学分类任务中表现最佳,尤其是在结构化文本数据集上。LoRA调优的Gemma变体表现最差,表明最小的微调可能导致泛化能力下降。Gemini 2.5在文本任务中表现不佳,但在多类图像任务中与ResNet-50相当。这些结果强调了在医学分类中,传统机器学习模型仍然是可靠的选择。
🎯 应用场景
该研究成果可应用于多种医学分类场景,例如疾病诊断、医学图像分析、文本报告分类等。通过选择合适的模型,可以提高医学分类的准确性和效率,从而辅助医生进行诊断和治疗,具有重要的实际应用价值。未来的研究可以探索更有效的微调策略,以提高LLM在医学分类任务中的性能。
📄 摘要(原文)
The combination of multimodal Vision-Language Models (VLMs) and Large Language Models (LLMs) opens up new possibilities for medical classification. This work offers a rigorous, unified benchmark by using four publicly available datasets covering text and image modalities (binary and multiclass complexity) that contrasts traditional Machine Learning (ML) with contemporary transformer-based techniques. We evaluated three model classes for each task: Classical ML (LR, LightGBM, ResNet-50), Prompt-Based LLMs/VLMs (Gemini 2.5), and Fine-Tuned PEFT Models (LoRA-adapted Gemma3 variants). All experiments used consistent data splits and aligned metrics. According to our results, traditional machine learning (ML) models set a high standard by consistently achieving the best overall performance across most medical categorization tasks. This was especially true for structured text-based datasets, where the classical models performed exceptionally well. In stark contrast, the LoRA-tuned Gemma variants consistently showed the worst performance across all text and image experiments, failing to generalize from the minimal fine-tuning provided. However, the zero-shot LLM/VLM pipelines (Gemini 2.5) had mixed results; they performed poorly on text-based tasks, but demonstrated competitive performance on the multiclass image task, matching the classical ResNet-50 baseline. These results demonstrate that in many medical categorization scenarios, established machine learning models continue to be the most reliable option. The experiment suggests that foundation models are not universally superior and that the effectiveness of Parameter-Efficient Fine-Tuning (PEFT) is highly dependent on the adaptation strategy, as minimal fine-tuning proved detrimental in this study.