Do Models Hear Like Us? Probing the Representational Alignment of Audio LLMs and Naturalistic EEG
作者: Haoyun Yang, Xin Xiao, Jiang Zhong, Yu Tian, Dong Xiaohua, Yu Mao, Hao Wu, Kaiwen Wei
分类: cs.SD, cs.AI, eess.AS
发布日期: 2026-01-23
💡 一句话要点
通过脑电信号探究语音大模型与人类听觉神经机制的表征对齐
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语音大模型 脑电信号 表征对齐 神经机制 表征相似性分析
📋 核心要点
- 现有语音大模型缺乏对其内部表征与人类神经机制对齐程度的深入研究,难以解释其工作原理。
- 该研究通过比较语音大模型和人类脑电信号,使用多种相似性度量方法分析表征几何结构,揭示对齐模式。
- 实验发现模型排序依赖于相似性度量,且存在与N400相关的时空对齐模式,以及情感韵律对表征的影响。
📝 摘要(中文)
语音大语言模型(Audio LLMs)在整合语音感知和语言理解方面表现出强大的能力。然而,它们在自然听觉过程中产生的内部表征是否与人类神经动态对齐,在很大程度上仍未被探索。本文系统地研究了12个开源语音大模型与脑电图(EEG)信号在两个数据集上的逐层表征对齐情况。具体来说,我们采用了8种相似性度量方法,例如基于Spearman的表征相似性分析(RSA),来描述句子内的表征几何结构。我们的分析揭示了3个关键发现:(1)我们观察到一个排序依赖性分裂,即模型排名在不同的相似性度量方法中差异很大;(2)我们识别出时空对齐模式,其特征是深度相关的对齐峰值,以及在250-500毫秒时间窗口内RSA的显著增加,这与N400相关的神经动态一致;(3)我们发现了一种情感分离,即使用提出的三模态邻域一致性(TNC)标准识别出的负面韵律会降低几何相似性,同时增强基于协方差的依赖性。这些发现为语音大模型的表征机制提供了新的神经生物学见解。
🔬 方法详解
问题定义:该论文旨在探究语音大语言模型(Audio LLMs)的内部表征与人类在自然听觉过程中的神经动态是否对齐。现有方法缺乏对这种对齐关系的深入研究,无法从神经科学的角度理解Audio LLMs的工作机制。因此,需要一种方法来量化和分析Audio LLMs与人类神经活动之间的表征相似性。
核心思路:该论文的核心思路是通过比较Audio LLMs的内部表征和人类的脑电图(EEG)信号,来评估它们之间的表征对齐程度。通过使用多种相似性度量方法(如RSA)分析句子内的表征几何结构,可以揭示模型在不同层级和时间尺度上与人类神经活动的对应关系。这种方法能够提供神经生物学层面的证据,帮助理解Audio LLMs是如何处理语音信息的。
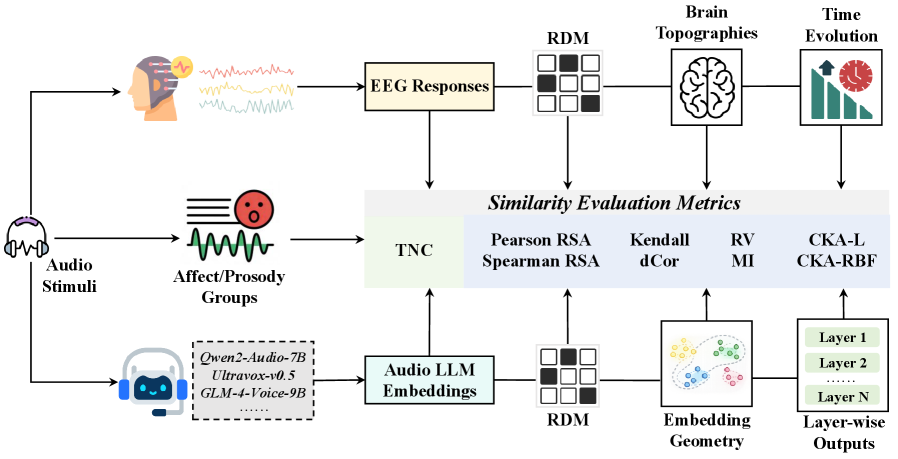
技术框架:整体框架包括以下几个主要步骤: 1. 数据收集:收集Audio LLMs的内部表征和人类的EEG信号。 2. 表征提取:从Audio LLMs的不同层级提取表征向量。 3. 相似性计算:使用多种相似性度量方法(如Spearman相关系数、RSA等)计算模型表征和EEG信号之间的相似性。 4. 时空分析:分析相似性度量在不同时间和空间上的分布模式。 5. 情感分析:使用三模态邻域一致性(TNC)标准识别情感韵律,并分析其对表征相似性的影响。
关键创新:该论文的关键创新在于: 1. 系统性地研究了多个开源Audio LLMs与人类EEG信号之间的表征对齐情况。 2. 采用了多种相似性度量方法,并分析了它们之间的差异。 3. 提出了三模态邻域一致性(TNC)标准来识别情感韵律,并分析其对表征相似性的影响。 4. 揭示了模型排序依赖于相似性度量,以及与N400相关的时空对齐模式。
关键设计: 1. 相似性度量:使用了8种相似性度量方法,包括Spearman相关系数、RSA等,以全面评估表征相似性。 2. 三模态邻域一致性(TNC):该标准用于识别情感韵律,通过分析语音、文本和视觉信息的一致性来提高识别准确率。 3. 时间窗口:重点关注250-500毫秒的时间窗口,因为该时间窗口与N400相关的神经动态密切相关。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Audio LLMs的表征与人类脑电信号存在时空对齐模式,尤其是在250-500ms时间窗口内,与N400成分相关。模型排序依赖于所使用的相似性度量。负面韵律会降低几何相似性,但增强基于协方差的依赖性。这些发现为理解Audio LLMs的内部工作机制提供了神经生物学层面的证据。
🎯 应用场景
该研究成果可应用于改进语音大模型的神经机制,提升其语音理解和情感识别能力。通过更好地理解模型与人类神经活动之间的关系,可以开发更自然、更人性化的语音交互系统,例如情感语音助手、智能客服等。此外,该研究方法也可用于评估其他类型AI模型的神经合理性。
📄 摘要(原文)
Audio Large Language Models (Audio LLMs) have demonstrated strong capabilities in integrating speech perception with language understanding. However, whether their internal representations align with human neural dynamics during naturalistic listening remains largely unexplored. In this work, we systematically examine layer-wise representational alignment between 12 open-source Audio LLMs and Electroencephalogram (EEG) signals across 2 datasets. Specifically, we employ 8 similarity metrics, such as Spearman-based Representational Similarity Analysis (RSA), to characterize within-sentence representational geometry. Our analysis reveals 3 key findings: (1) we observe a rank-dependence split, in which model rankings vary substantially across different similarity metrics; (2) we identify spatio-temporal alignment patterns characterized by depth-dependent alignment peaks and a pronounced increase in RSA within the 250-500 ms time window, consistent with N400-related neural dynamics; (3) we find an affective dissociation whereby negative prosody, identified using a proposed Tri-modal Neighborhood Consistency (TNC) criterion, reduces geometric similarity while enhancing covariance-based dependence. These findings provide new neurobiological insights into the representational mechanisms of Audio LLMs.