Cosmos Policy: Fine-Tuning Video Models for Visuomotor Control and Planning
作者: Moo Jin Kim, Yihuai Gao, Tsung-Yi Lin, Yen-Chen Lin, Yunhao Ge, Grace Lam, Percy Liang, Shuran Song, Ming-Yu Liu, Chelsea Finn, Jinwei Gu
分类: cs.AI, cs.RO
发布日期: 2026-01-22
💡 一句话要点
Cosmos Policy:通过微调视频模型实现视觉运动控制与规划
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人策略学习 视频模型 视觉运动控制 模型预测控制 扩散模型
📋 核心要点
- 现有方法在将视频生成模型应用于机器人策略学习时,需要多阶段后训练和新的架构组件,增加了复杂性。
- Cosmos Policy通过单阶段微调预训练视频模型,直接在潜在空间中生成动作,避免了复杂的后训练和架构修改。
- Cosmos Policy在模拟和真实机器人任务中均取得了优异的性能,超越了现有方法,并能通过经验学习进一步提升性能。
📝 摘要(中文)
本文提出了一种名为Cosmos Policy的简单方法,用于将大型预训练视频模型(Cosmos-Predict2)适配为有效的机器人策略。该方法通过在目标平台上收集的机器人演示数据上进行单阶段微调实现,无需修改模型架构。Cosmos Policy学习直接生成机器人动作,这些动作被编码为视频模型潜在扩散过程中的潜在帧,从而利用了模型预训练的先验知识和核心学习算法来捕获复杂的动作分布。此外,Cosmos Policy还生成未来的状态图像和值(预期累积奖励),它们也被类似地编码为潜在帧,从而能够在测试时规划具有更高成功概率的动作轨迹。在LIBERO和RoboCasa模拟基准测试中,Cosmos Policy取得了最先进的性能(平均成功率分别为98.5%和67.1%),并在具有挑战性的真实世界双臂操作任务中获得了最高的平均分数,优于从头开始训练的强大扩散策略、基于视频模型的策略以及在相同机器人演示数据上微调的最先进的视觉-语言-动作模型。此外,给定策略rollout数据,Cosmos Policy可以从经验中学习,以改进其世界模型和价值函数,并利用基于模型的规划来实现更具挑战性任务中更高的成功率。
🔬 方法详解
问题定义:现有基于视频模型的机器人策略学习方法通常需要复杂的后训练流程和额外的网络结构来生成动作,这增加了训练的难度和计算成本。此外,如何有效利用预训练视频模型的时空先验知识也是一个挑战。
核心思路:Cosmos Policy的核心思路是将机器人动作、未来状态和价值函数都编码为视频模型潜在空间中的潜在帧。通过在机器人演示数据上微调预训练的视频模型,Cosmos Policy可以直接生成动作,并利用模型已有的时空推理能力进行规划。
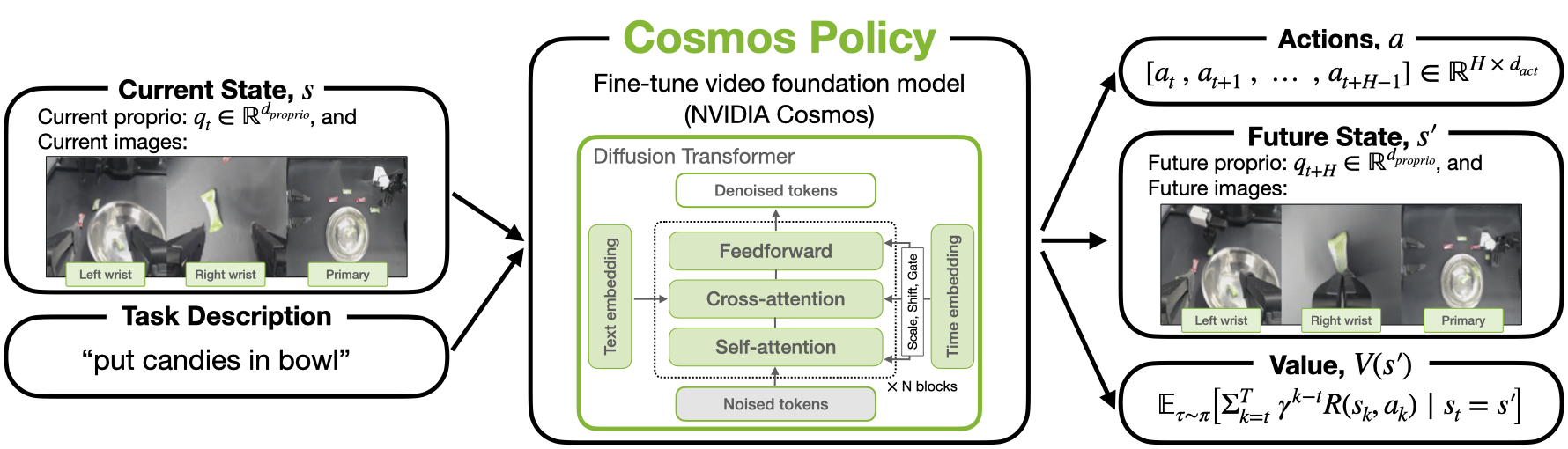
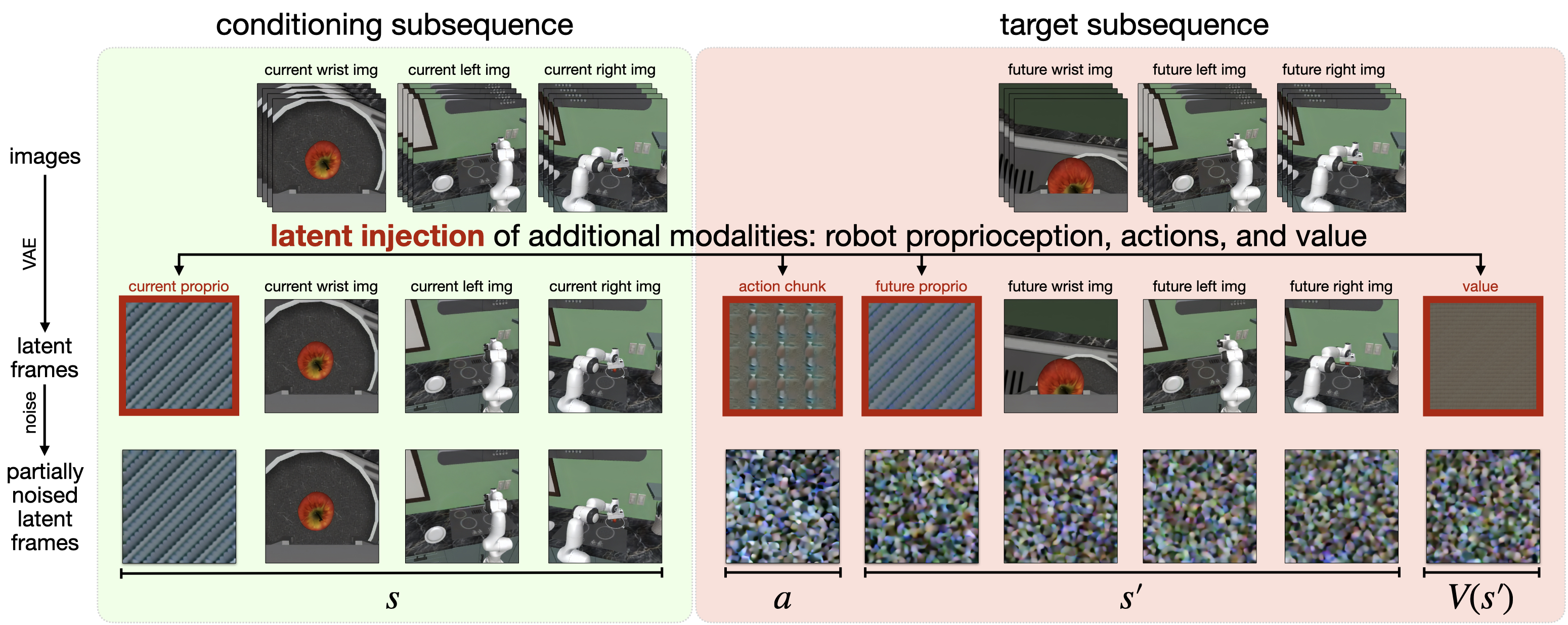
技术框架:Cosmos Policy的整体框架包括以下几个步骤:1) 使用预训练的视频模型(Cosmos-Predict2)作为基础模型。2) 将机器人动作、未来状态和价值函数编码为潜在帧,并将其输入到视频模型中。3) 在机器人演示数据上微调视频模型,使其能够生成期望的动作序列。4) 在测试时,使用微调后的模型生成动作序列,并利用模型预测的未来状态和价值函数进行规划。
关键创新:Cosmos Policy的关键创新在于:1) 将机器人动作直接编码为视频模型的潜在帧,从而避免了额外的动作生成模块。2) 利用预训练视频模型的时空先验知识,提高了策略学习的效率和性能。3) 通过预测未来状态和价值函数,实现了基于模型的规划,进一步提升了策略的鲁棒性。
关键设计:Cosmos Policy的关键设计包括:1) 使用Cosmos-Predict2作为预训练视频模型,该模型具有强大的时空推理能力。2) 使用扩散模型进行潜在帧的生成,可以生成更加多样化的动作序列。3) 使用Transformer网络对潜在帧进行编码和解码,可以有效地捕捉时序依赖关系。4) 使用行为克隆损失函数进行微调,使得模型能够模仿演示数据中的动作。
🖼️ 关键图片

📊 实验亮点
Cosmos Policy在LIBERO和RoboCasa模拟基准测试中取得了最先进的性能,平均成功率分别达到98.5%和67.1%。在真实世界的双臂操作任务中,Cosmos Policy也获得了最高的平均分数,超越了从头开始训练的扩散策略、基于视频模型的策略以及视觉-语言-动作模型。通过经验学习和基于模型的规划,Cosmos Policy的性能可以进一步提升。
🎯 应用场景
Cosmos Policy具有广泛的应用前景,可以应用于各种机器人操作任务,例如物体抓取、装配、导航等。该方法还可以应用于自动驾驶、游戏AI等领域,通过学习人类的演示数据,实现更加智能和自然的控制策略。未来,Cosmos Policy有望成为一种通用的机器人策略学习方法,推动机器人技术的进一步发展。
📄 摘要(原文)
Recent video generation models demonstrate remarkable ability to capture complex physical interactions and scene evolution over time. To leverage their spatiotemporal priors, robotics works have adapted video models for policy learning but introduce complexity by requiring multiple stages of post-training and new architectural components for action generation. In this work, we introduce Cosmos Policy, a simple approach for adapting a large pretrained video model (Cosmos-Predict2) into an effective robot policy through a single stage of post-training on the robot demonstration data collected on the target platform, with no architectural modifications. Cosmos Policy learns to directly generate robot actions encoded as latent frames within the video model's latent diffusion process, harnessing the model's pretrained priors and core learning algorithm to capture complex action distributions. Additionally, Cosmos Policy generates future state images and values (expected cumulative rewards), which are similarly encoded as latent frames, enabling test-time planning of action trajectories with higher likelihood of success. In our evaluations, Cosmos Policy achieves state-of-the-art performance on the LIBERO and RoboCasa simulation benchmarks (98.5% and 67.1% average success rates, respectively) and the highest average score in challenging real-world bimanual manipulation tasks, outperforming strong diffusion policies trained from scratch, video model-based policies, and state-of-the-art vision-language-action models fine-tuned on the same robot demonstrations. Furthermore, given policy rollout data, Cosmos Policy can learn from experience to refine its world model and value function and leverage model-based planning to achieve even higher success rates in challenging tasks. We release code, models, and training data at https://research.nvidia.com/labs/dir/cosmos-policy/