Multimodal Climate Disinformation Detection: Integrating Vision-Language Models with External Knowledge Sources
作者: Marzieh Adeli Shamsabad, Hamed Ghodrati
分类: cs.AI
发布日期: 2026-01-22
💡 一句话要点
结合外部知识的视觉-语言模型用于多模态气候虚假信息检测
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 气候虚假信息检测 视觉-语言模型 外部知识融合 反向图像搜索 事实核查
📋 核心要点
- 现有视觉-语言模型在检测气候虚假信息时,依赖训练时知识,无法有效处理新出现的事件和信息。
- 论文提出将视觉-语言模型与外部知识源结合,包括反向图像搜索、在线事实核查和专家内容。
- 该方法旨在提升模型对气候虚假信息的识别能力,从而保护公众对气候科学的正确认知。
📝 摘要(中文)
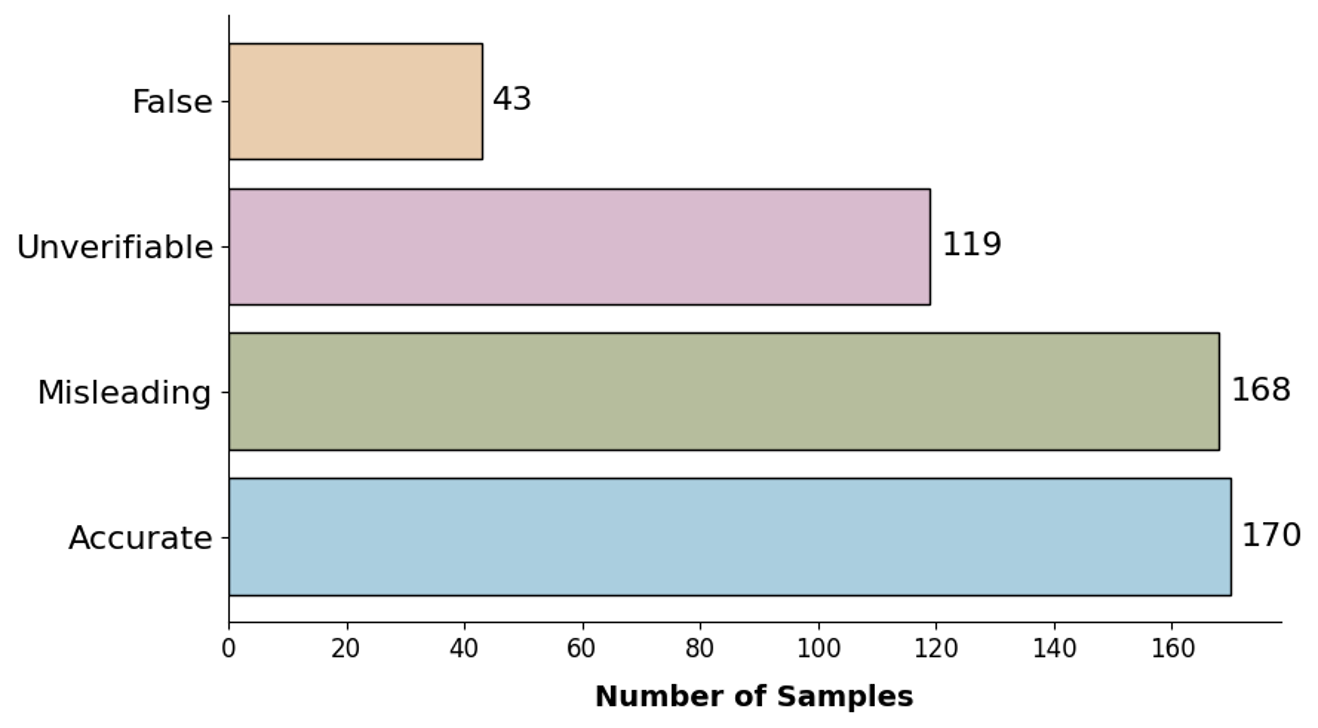
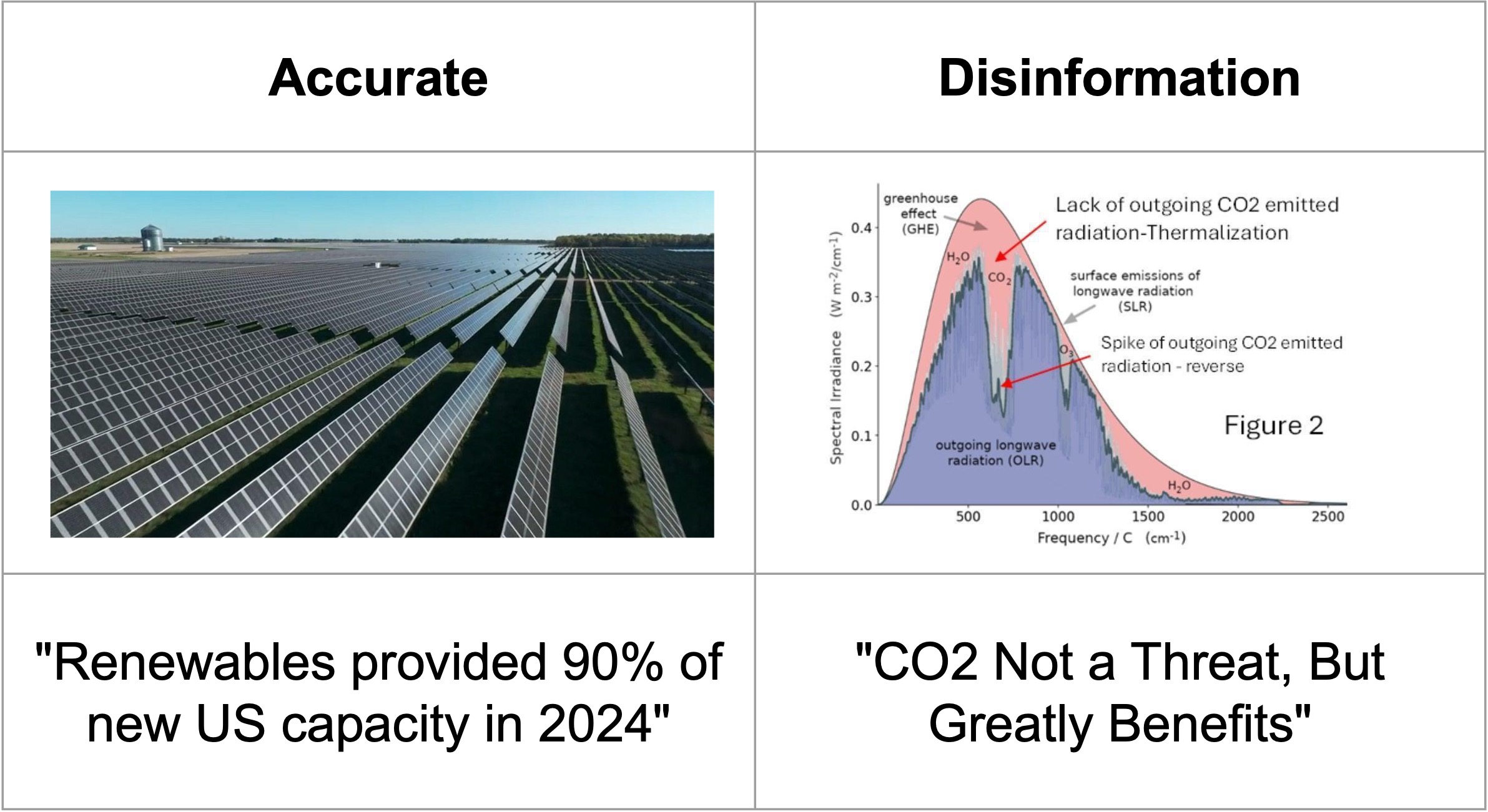
气候虚假信息已成为当今数字世界的主要挑战,尤其是在社交媒体上广泛传播的误导性图像和视频日益增多。这些虚假声明通常具有很强的迷惑性且难以检测,这可能会延缓应对气候变化的行动。虽然视觉-语言模型(VLMs)已被用于识别视觉虚假信息,但它们仅依赖于训练时可用的知识。这限制了它们对最近事件或更新进行推理的能力。本文的主要目标是通过将VLMs与外部知识相结合来克服这一限制。通过检索最新的信息,例如反向图像搜索结果、在线事实核查和可信的专家内容,该系统可以更好地评估图像及其声明是否准确、具有误导性、虚假或无法验证。这种方法提高了模型处理真实世界气候虚假信息的能力,并支持在快速变化的信息环境中保护公众对科学的理解。
🔬 方法详解
问题定义:当前的气候虚假信息检测面临的挑战是,仅仅依赖视觉-语言模型(VLMs)自身训练的知识,无法有效识别基于最新事件或信息的虚假内容。现有的VLMs缺乏对外部知识的利用,导致其在快速变化的信息环境中表现不佳。
核心思路:论文的核心思路是将VLMs与外部知识源进行融合,从而增强模型对气候虚假信息的识别能力。通过检索与图像相关的最新信息,例如反向图像搜索结果、在线事实核查报告以及可信的专家内容,模型可以获得更全面的上下文信息,从而做出更准确的判断。
技术框架:该方法的技术框架主要包括以下几个阶段:1) 输入图像和相关文本描述;2) 利用VLMs提取图像和文本的特征表示;3) 使用图像作为查询,进行反向图像搜索,并检索相关的在线事实核查报告和专家内容;4) 将检索到的外部知识与图像和文本的特征表示进行融合;5) 使用融合后的特征进行虚假信息检测。
关键创新:该方法最重要的技术创新点在于将外部知识源集成到视觉-语言模型中,从而克服了传统VLMs仅依赖于训练时知识的局限性。这种方法使得模型能够利用最新的信息来判断气候虚假信息,提高了模型的鲁棒性和泛化能力。
关键设计:论文的关键设计包括:如何有效地检索相关的外部知识,如何将检索到的知识与图像和文本的特征表示进行融合,以及如何设计合适的损失函数来训练模型。具体的参数设置、损失函数和网络结构等技术细节在论文中可能有所描述,但此处无法得知。
🖼️ 关键图片

📊 实验亮点
由于论文摘要中未提供具体的实验结果和性能数据,因此无法总结实验亮点。需要查阅论文全文才能获取相关信息。但可以推测,实验部分应该会对比集成外部知识的VLM与传统VLM在气候虚假信息检测任务上的性能差异,并给出具体的性能指标提升。
🎯 应用场景
该研究成果可应用于社交媒体平台、新闻媒体和在线信息平台,用于自动检测和标记气候虚假信息。通过提高公众对气候变化的认知,减少虚假信息的影响,从而促进更明智的决策和行动,应对气候变化带来的挑战。该研究还有助于提升信息安全和公众科学素养。
📄 摘要(原文)
Climate disinformation has become a major challenge in today digital world, especially with the rise of misleading images and videos shared widely on social media. These false claims are often convincing and difficult to detect, which can delay actions on climate change. While vision-language models (VLMs) have been used to identify visual disinformation, they rely only on the knowledge available at the time of training. This limits their ability to reason about recent events or updates. The main goal of this paper is to overcome that limitation by combining VLMs with external knowledge. By retrieving up-to-date information such as reverse image results, online fact-checks, and trusted expert content, the system can better assess whether an image and its claim are accurate, misleading, false, or unverifiable. This approach improves the model ability to handle real-world climate disinformation and supports efforts to protect public understanding of science in a rapidly changing information landscape.