Grounding Large Language Models in Reaction Knowledge Graphs for Synthesis Retrieval
作者: Olga Bunkova, Lorenzo Di Fruscia, Sophia Rupprecht, Artur M. Schweidtmann, Marcel J. T. Reinders, Jana M. Weber
分类: cs.AI
发布日期: 2026-01-22
备注: Accepted at ML4Molecules 2025 (ELLIS UnConference workshop), Copenhagen, Denmark, December 2, 2025. Workshop page: https://moleculediscovery.github.io/workshop2025/
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于反应知识图谱的LLM合成检索方法,解决化学合成规划中LLM的幻觉问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 知识图谱 化学合成规划 Text2Cypher 反应检索
📋 核心要点
- 现有LLM在化学合成规划中易产生幻觉和过时建议,缺乏可靠的知识 grounding。
- 将反应路径检索转化为Text2Cypher生成问题,利用反应知识图谱约束LLM的输出。
- 单样本提示结合对齐范例效果最佳,检查表式自我校正循环在零样本设置中提升可执行性。
📝 摘要(中文)
大型语言模型(LLM)可以辅助化学合成规划,但标准的提示方法通常会产生幻觉或过时的建议。本文研究了LLM与反应知识图谱的交互,将反应路径检索问题转化为Text2Cypher(自然语言到图查询)生成问题,并定义了单步和多步检索任务。我们比较了零样本提示与使用静态、随机和基于嵌入的范例选择的单样本变体,并评估了基于检查表的验证器/校正器循环。为了评估我们的框架,我们考虑了查询有效性和检索准确性。我们发现,使用对齐范例的单样本提示始终表现最佳。我们的检查表式自我校正循环主要提高了零样本设置中的可执行性,并且在存在良好范例后提供的额外检索增益有限。我们提供了一个可复现的Text2Cypher评估设置,以促进进一步研究基于KG的LLM用于合成规划。代码可在https://github.com/Intelligent-molecular-systems/KG-LLM-Synthesis-Retrieval获得。
🔬 方法详解
问题定义:现有的大型语言模型在化学合成规划任务中,容易产生不准确或过时的建议,即出现“幻觉”现象。这是因为LLM缺乏对化学反应知识的有效 grounding。因此,如何利用外部知识库(如反应知识图谱)来约束LLM的生成,提高其在化学合成规划中的可靠性,是本文要解决的核心问题。
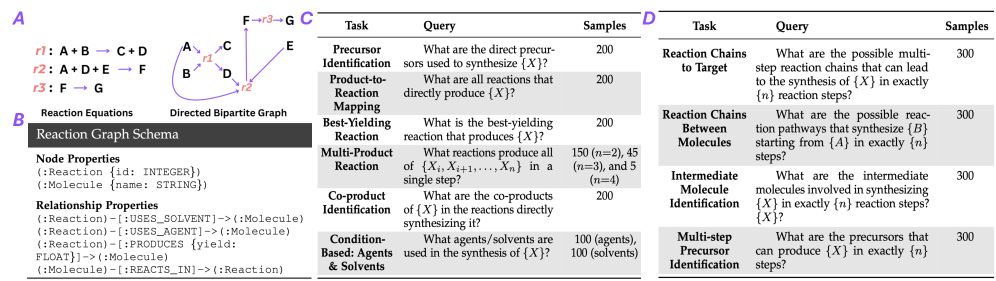
核心思路:本文的核心思路是将反应路径检索问题转化为一个Text2Cypher生成问题。也就是说,给定一个自然语言描述的合成目标,LLM需要生成相应的Cypher查询语句,该语句可以在反应知识图谱中检索出合适的反应路径。通过这种方式,LLM的生成过程被约束在知识图谱的范围内,从而减少了幻觉的产生。
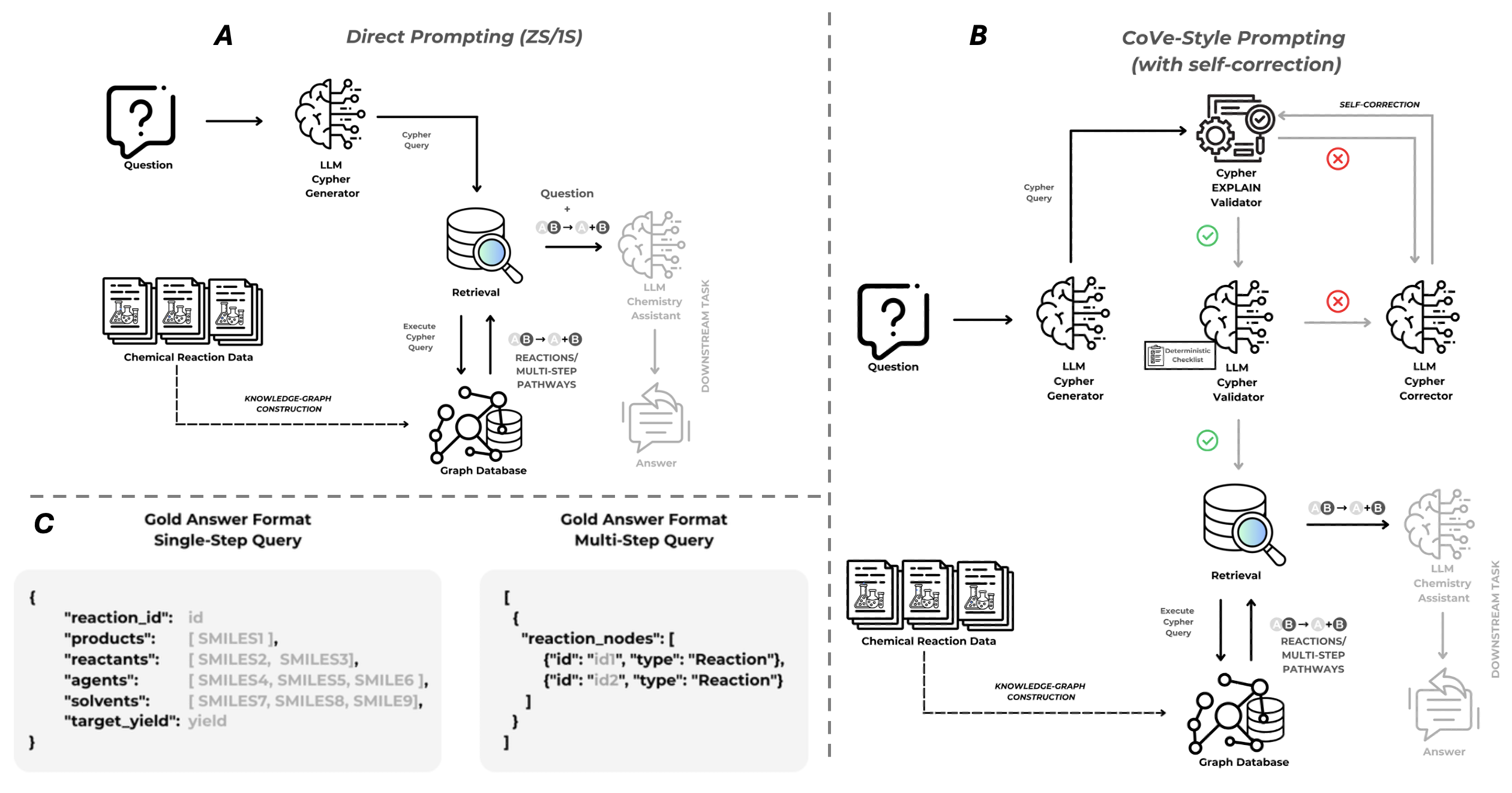
技术框架:整体框架包含以下几个主要模块:1) Text2Cypher生成模块:使用LLM(如GPT-3)将自然语言描述的合成目标转化为Cypher查询语句。2) 知识图谱检索模块:使用生成的Cypher查询语句在反应知识图谱中检索反应路径。3) 范例选择模块:在单样本提示设置中,选择合适的范例来引导LLM生成更准确的Cypher查询。范例选择策略包括静态选择、随机选择和基于嵌入的选择。4) 验证与校正模块:使用基于检查表的验证器来检查生成的Cypher查询是否有效,并进行必要的校正。
关键创新:本文的关键创新在于将反应路径检索问题转化为Text2Cypher生成问题,并利用反应知识图谱来 grounding LLM的输出。此外,本文还提出了多种范例选择策略和基于检查表的验证与校正方法,以进一步提高检索的准确性和可靠性。与现有方法相比,本文的方法更加注重利用外部知识来约束LLM的生成,从而减少了幻觉的产生。
关键设计:在范例选择方面,本文比较了静态、随机和基于嵌入的策略。基于嵌入的策略使用预训练的分子嵌入模型来计算查询和范例之间的相似度,选择最相似的范例。在验证与校正方面,本文设计了一系列检查表,用于检查生成的Cypher查询是否符合语法规则和语义约束。例如,检查查询是否包含必要的节点和关系类型,以及节点和关系之间的连接是否正确。
🖼️ 关键图片
📊 实验亮点
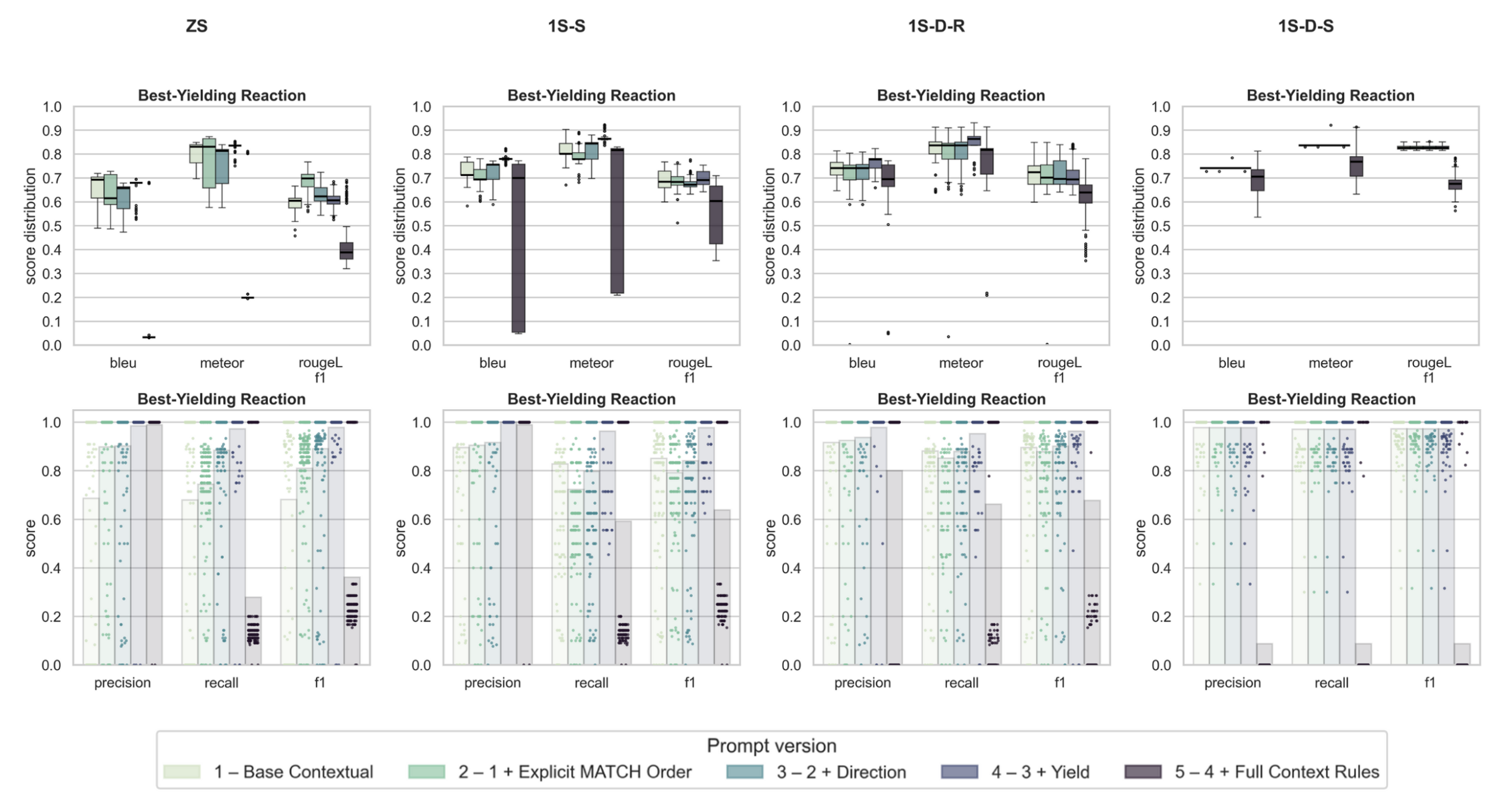
实验结果表明,单样本提示结合对齐范例(aligned exemplars)能够显著提高检索准确性。此外,检查表式自我校正循环主要在零样本设置中提高了Cypher查询的可执行性。在有良好范例的情况下,自我校正循环带来的额外检索增益有限。该研究提供了一个可复现的Text2Cypher评估设置,为后续研究KG-grounded LLM在合成规划中的应用奠定了基础。
🎯 应用场景
该研究成果可应用于化学合成规划、药物发现等领域。通过结合大型语言模型和反应知识图谱,可以帮助化学家更高效地设计合成路线,加速新药物的研发过程。未来,该方法还可以扩展到其他领域的知识图谱应用,例如材料科学、生物信息学等。
📄 摘要(原文)
Large Language Models (LLMs) can aid synthesis planning in chemistry, but standard prompting methods often yield hallucinated or outdated suggestions. We study LLM interactions with a reaction knowledge graph by casting reaction path retrieval as a Text2Cypher (natural language to graph query) generation problem, and define single- and multi-step retrieval tasks. We compare zero-shot prompting to one-shot variants using static, random, and embedding-based exemplar selection, and assess a checklist-driven validator/corrector loop. To evaluate our framework, we consider query validity and retrieval accuracy. We find that one-shot prompting with aligned exemplars consistently performs best. Our checklist-style self-correction loop mainly improves executability in zero-shot settings and offers limited additional retrieval gains once a good exemplar is present. We provide a reproducible Text2Cypher evaluation setup to facilitate further work on KG-grounded LLMs for synthesis planning. Code is available at https://github.com/Intelligent-molecular-systems/KG-LLM-Synthesis-Retrieval.