Sawtooth Wavefront Reordering: Enhanced CuTile FlashAttention on NVIDIA GB10
作者: Yifan Zhu, Yekai Pan, Chen Ding
分类: cs.PF, cs.AI, cs.LG, cs.OS
发布日期: 2026-01-22
💡 一句话要点
提出锯齿波前重排序技术,优化NVIDIA GB10上CuTile FlashAttention的L2缓存性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: FlashAttention CuTile L2缓存优化 锯齿波前重排序 NVIDIA GB10 内存访问优化 高性能计算 大规模语言模型
📋 核心要点
- 现有基于CuTile的Flash Attention在NVIDIA GB10上存在L2缓存未命中率高的问题,限制了性能。
- 论文提出锯齿波前重排序技术,通过优化内存访问模式,减少L2缓存未命中。
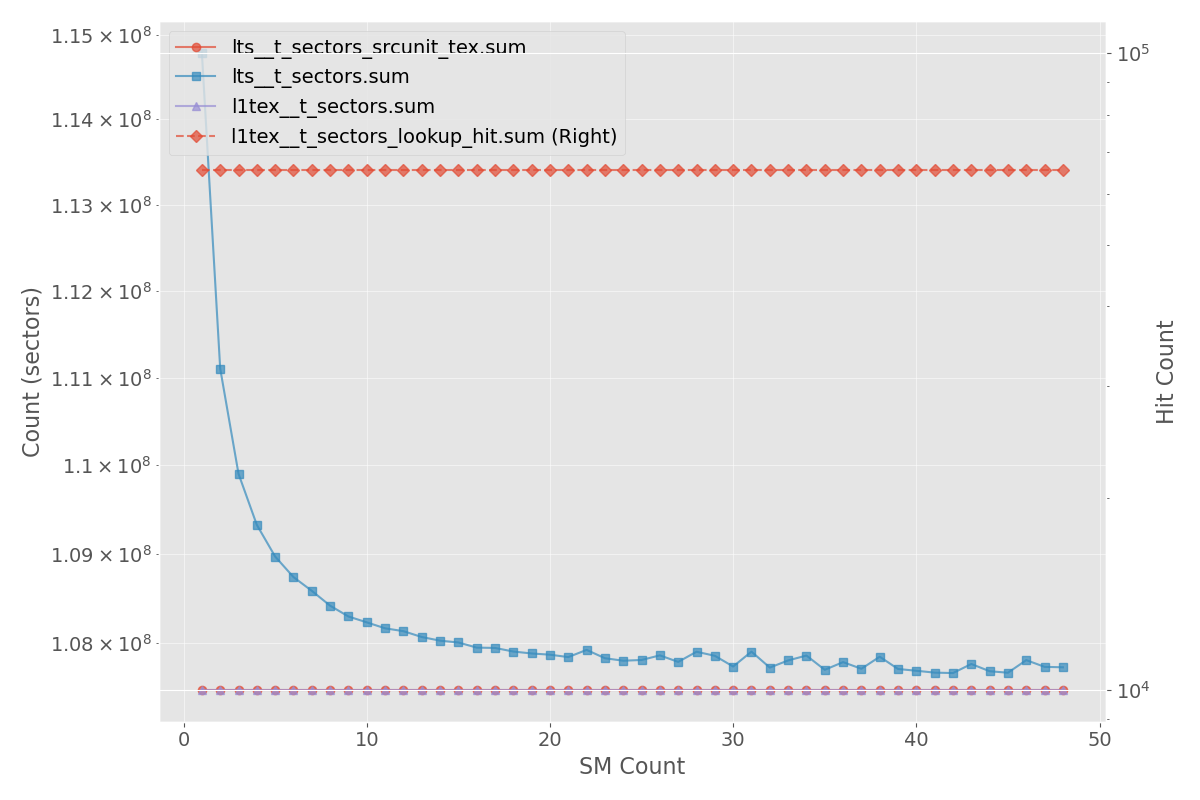
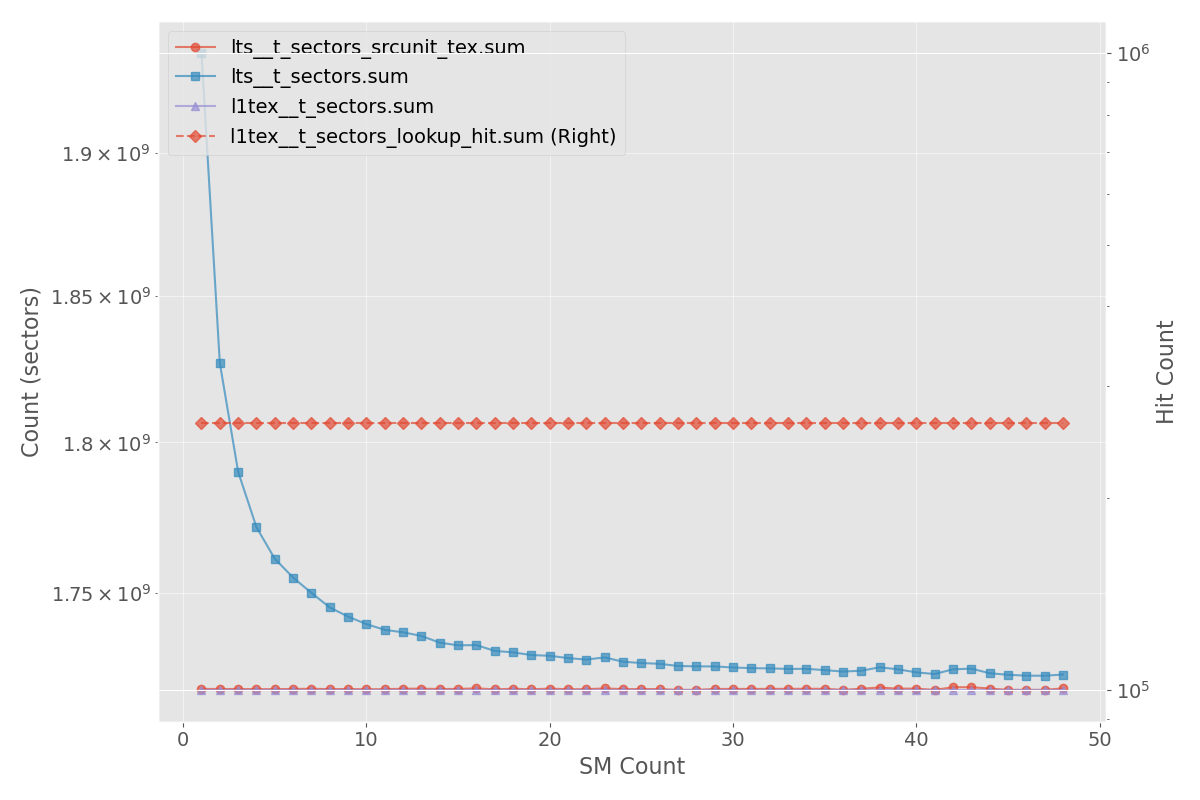
- 实验表明,该方法在GB10上显著降低了L2缓存未命中率,并提升了高达60%的吞吐量。
📝 摘要(中文)
本文针对大规模语言模型中至关重要的高性能注意力机制核函数,分析了基于CuTile的Flash Attention的内存访问行为,并提出了一种改进其缓存性能的技术。特别地,我们对NVIDIA GB10 (Grace Blackwell) 的分析揭示了L2缓存未命中的主要原因。基于此洞察,我们引入了一种名为锯齿波前重排序的新编程技术,以减少L2缓存未命中。我们在CUDA和CuTile中验证了该方法,观察到L2缓存未命中减少了50%或更多,并且在GB10上的吞吐量提高了高达60%。
🔬 方法详解
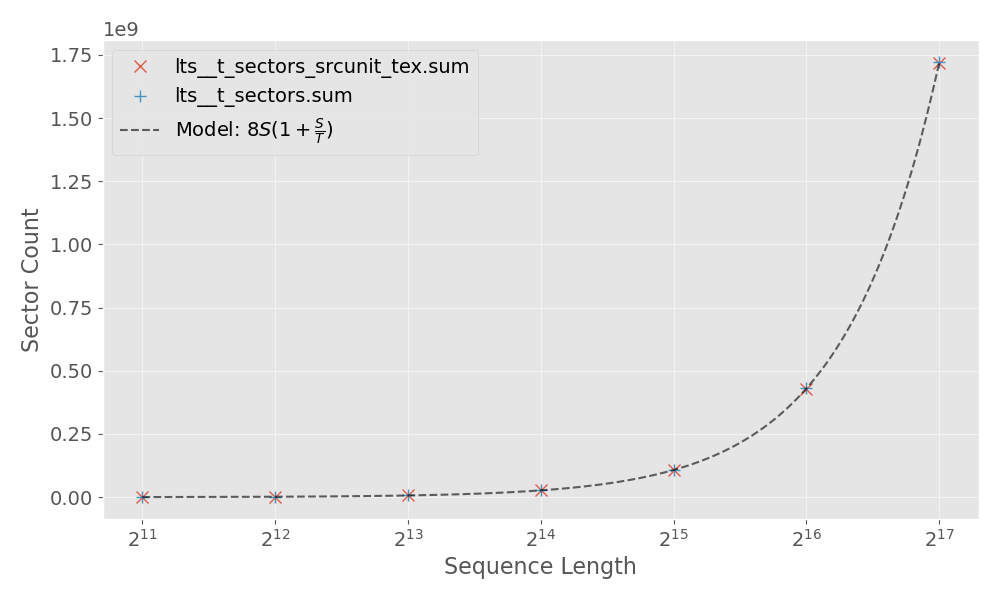
问题定义:论文旨在解决NVIDIA GB10 GPU上,基于CuTile的FlashAttention实现中L2缓存未命中率高的问题。现有方法在处理大规模注意力计算时,由于内存访问模式不佳,导致大量数据需要从主存加载,严重影响了计算效率。
核心思路:核心思路是通过重新排序计算的波前,改变内存访问模式,使得相邻的线程访问相邻的内存区域,从而提高数据局部性,减少L2缓存未命中。锯齿波前重排序旨在优化数据重用,使得数据在被逐出L2缓存之前被尽可能多地使用。
技术框架:该方法主要在CUDA和CuTile框架下实现。首先,对原始的FlashAttention的内存访问模式进行分析,找出L2缓存未命中的瓶颈。然后,设计锯齿波前重排序算法,该算法改变了线程的执行顺序,从而改变了内存访问模式。最后,在CUDA和CuTile中实现该算法,并进行性能评估。
关键创新:关键创新在于提出了锯齿波前重排序这一编程技术,它通过改变线程的执行顺序,优化了内存访问模式,从而显著降低了L2缓存未命中率。与传统的线程块划分和数据布局优化方法不同,该方法直接在计算波前层面进行优化,更加精细地控制了内存访问行为。
关键设计:锯齿波前重排序的具体实现涉及到对线程块内的线程进行重新排序,使得相邻的线程访问相邻的内存区域。具体的排序方式可以根据硬件架构和数据布局进行调整。论文中可能包含具体的线程索引计算公式,以及如何将逻辑线程ID映射到物理线程ID的细节。此外,可能还涉及到对shared memory的使用进行优化,以进一步提高数据局部性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在NVIDIA GB10 GPU上,锯齿波前重排序技术能够将L2缓存未命中率降低50%以上,并使吞吐量提升高达60%。该方法在CUDA和CuTile两种编程框架下均取得了显著的性能提升,验证了其有效性和通用性。这些结果表明,通过优化内存访问模式,可以充分发挥新型GPU架构的性能潜力。
🎯 应用场景
该研究成果可广泛应用于大规模语言模型的训练和推理加速,特别是在NVIDIA Grace Blackwell等新型GPU架构上。通过降低L2缓存未命中率,可以显著提高计算效率,降低能耗,从而加速AI模型的开发和部署。该技术也可能推广到其他计算密集型应用中,例如图像处理、科学计算等。
📄 摘要(原文)
High-performance attention kernels are essential for Large Language Models. This paper presents analysis of CuTile-based Flash Attention memory behavior and a technique to improve its cache performance. In particular, our analysis on the NVIDIA GB10 (Grace Blackwell) identifies the main cause of L2 cache miss. Leveraging this insight, we introduce a new programming technique called Sawtooth Wavefront Reordering that reduces L2 misses. We validate it in both CUDA and CuTile, observing 50\% or greater reduction in L2 misses and up to 60\% increase in throughput on GB10.