Decoupling Return-to-Go for Efficient Decision Transformer
作者: Yongyi Wang, Hanyu Liu, Lingfeng Li, Bozhou Chen, Ang Li, Qirui Zheng, Xionghui Yang, Wenxin Li
分类: cs.AI
发布日期: 2026-01-22
💡 一句话要点
提出解耦决策Transformer(DDT),提升离线强化学习效率与性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 离线强化学习 决策Transformer Return-to-Go 序列建模 解耦 Transformer 强化学习
📋 核心要点
- 决策Transformer依赖完整RTG序列,存在冗余,影响性能并增加计算负担。
- 解耦决策Transformer (DDT) 仅使用最新RTG指导动作预测,简化架构。
- 实验证明DDT在多个离线强化学习任务中超越DT,并与SOTA方法竞争。
📝 摘要(中文)
决策Transformer (DT) 是一种强大的离线强化学习序列建模方法。它通过Return-to-Go (RTG) 来调节动作预测,RTG既用于区分训练期间的轨迹质量,又用于指导推理时的动作生成。本文发现这种设计存在关键冗余:将整个RTG序列输入Transformer在理论上是不必要的,因为只有最近的RTG会影响动作预测。实验表明,这种冗余会损害DT的性能。为了解决这个问题,我们提出了解耦DT (DDT)。DDT简化了架构,仅通过Transformer处理观察和动作序列,并使用最新的RTG来指导动作预测。这种简化的方法不仅提高了性能,还降低了计算成本。实验表明,DDT显著优于DT,并在多个离线RL任务中建立了与最先进的DT变体具有竞争力的性能。
🔬 方法详解
问题定义:决策Transformer (DT) 在离线强化学习中利用Return-to-Go (RTG) 来指导动作预测。然而,DT将整个RTG序列输入Transformer,这引入了冗余信息,因为只有最近的RTG对当前动作决策有直接影响。这种冗余不仅增加了计算负担,还可能降低模型的性能。
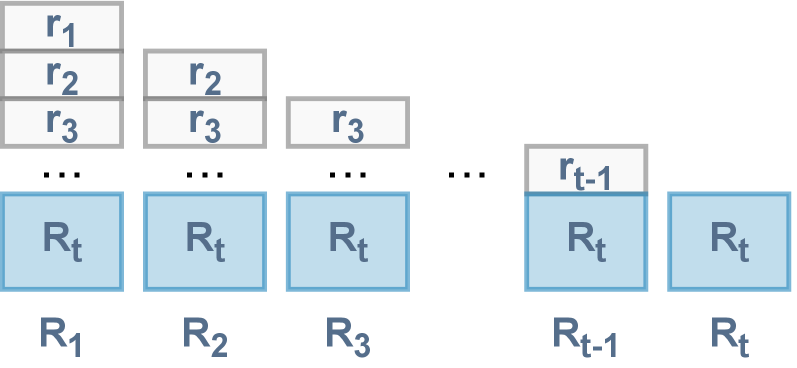
核心思路:DDT的核心思想是将RTG的使用解耦,不再将整个RTG序列输入Transformer,而是仅使用最新的RTG值来指导动作预测。这样可以避免冗余信息的干扰,提高模型的效率和准确性。这种设计基于观察:当前动作主要受当前状态和期望回报(即最新RTG)的影响。
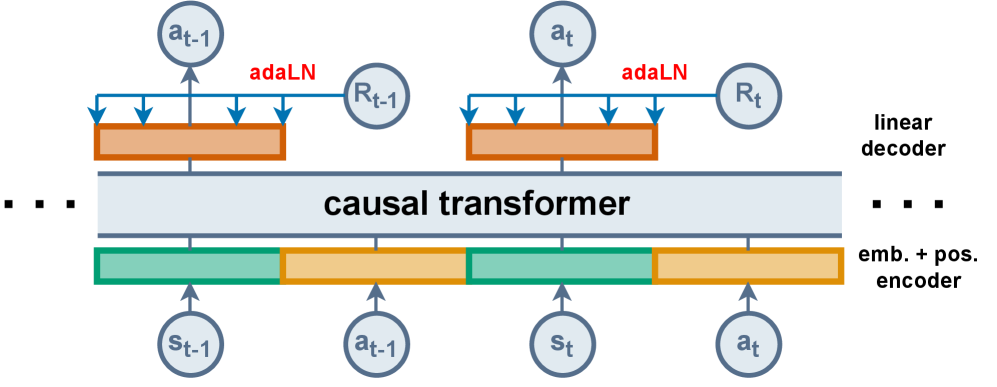
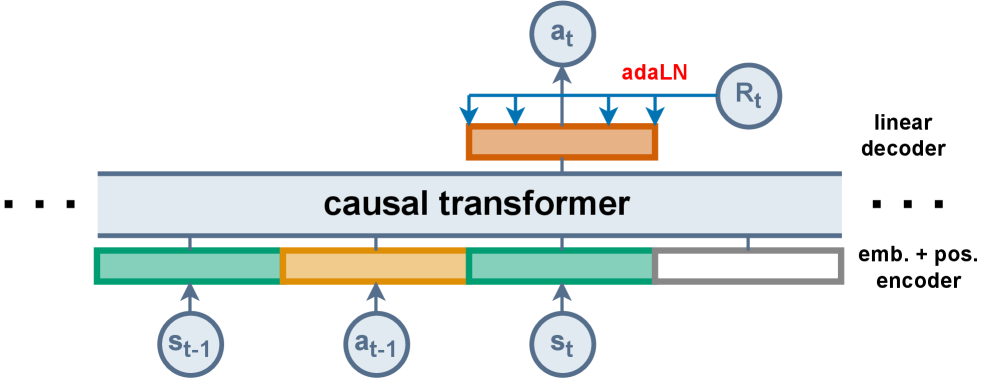
技术框架:DDT的整体架构与DT类似,仍然使用Transformer作为核心模型。主要的区别在于输入部分:DDT仅将观察序列和动作序列输入Transformer,而不再包含RTG序列。在Transformer的输出端,DDT使用最新的RTG值来调节动作预测。具体来说,可以将最新的RTG值与Transformer的输出进行某种形式的融合,例如通过加权求和或拼接等方式。
关键创新:DDT最重要的技术创新点在于解耦了RTG的使用,避免了冗余信息的干扰。与DT相比,DDT的输入更简洁,计算效率更高,并且能够更好地捕捉当前状态和期望回报之间的关系。这种解耦的设计使得模型更加专注于当前决策,从而提高了性能。
关键设计:DDT的关键设计在于如何将最新的RTG值有效地融合到Transformer的输出中。论文中可能采用了多种融合方式,例如将RTG值与Transformer的输出进行拼接,然后通过一个线性层进行映射;或者使用RTG值作为注意力机制的权重,来调节Transformer的输出。具体的损失函数与DT类似,仍然是基于序列建模的损失函数,例如交叉熵损失或均方误差损失。网络结构方面,DDT可以使用与DT相同的Transformer结构,也可以根据具体任务进行调整。
🖼️ 关键图片
📊 实验亮点
实验结果表明,DDT在多个离线强化学习任务中显著优于DT,并且与最先进的DT变体具有竞争力的性能。具体的性能提升幅度取决于具体的任务和数据集,但总体而言,DDT在性能和效率方面都取得了显著的改进。这些结果验证了DDT的有效性,并表明解耦RTG是一种有效的优化决策Transformer的方法。
🎯 应用场景
DDT可应用于各种离线强化学习场景,例如机器人控制、游戏AI、推荐系统和金融交易等。通过利用离线数据进行训练,DDT可以学习到有效的策略,并在实际应用中做出高质量的决策。DDT的效率提升使其更适用于资源受限的场景,并有望推动离线强化学习在更广泛领域的应用。
📄 摘要(原文)
The Decision Transformer (DT) has established a powerful sequence modeling approach to offline reinforcement learning. It conditions its action predictions on Return-to-Go (RTG), using it both to distinguish trajectory quality during training and to guide action generation at inference. In this work, we identify a critical redundancy in this design: feeding the entire sequence of RTGs into the Transformer is theoretically unnecessary, as only the most recent RTG affects action prediction. We show that this redundancy can impair DT's performance through experiments. To resolve this, we propose the Decoupled DT (DDT). DDT simplifies the architecture by processing only observation and action sequences through the Transformer, using the latest RTG to guide the action prediction. This streamlined approach not only improves performance but also reduces computational cost. Our experiments show that DDT significantly outperforms DT and establishes competitive performance against state-of-the-art DT variants across multiple offline RL tasks.