Off-Policy Actor-Critic with Sigmoid-Bounded Entropy for Real-World Robot Learning
作者: Xiefeng Wu, Mingyu Hu, Shu Zhang
分类: cs.AI
发布日期: 2026-01-22
备注: 7 pages main text 2 page reference
💡 一句话要点
提出SigEnt-SAC算法,利用单条专家轨迹实现真实机器人环境中的高效强化学习。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 机器人学习 Off-Policy Actor-Critic 熵正则化 Q函数 真实世界 样本效率
📋 核心要点
- 真实世界强化学习面临样本效率低、奖励稀疏和观测噪声等挑战,现有方法依赖大量数据或预训练,成本较高。
- SigEnt-SAC通过引入sigmoid有界熵项,避免负熵驱动的优化,从而抑制Q函数振荡,提高学习稳定性。
- 实验表明,SigEnt-SAC在D4RL任务中表现优异,并在真实机器人任务中仅需少量交互即可学习到有效策略。
📝 摘要(中文)
由于样本效率低、奖励稀疏和视觉观测噪声,强化学习在真实世界中的部署仍然具有挑战性。先前的工作利用演示和人类反馈来提高学习效率和鲁棒性。然而,离线到在线的方法需要大型数据集并且可能不稳定,而VLA辅助的RL依赖于大规模的预训练和微调。因此,一种低成本、数据需求少的真实世界RL方法尚未出现。我们引入了SigEnt-SAC,一种off-policy actor-critic方法,它使用单个专家轨迹从头开始学习。我们的关键设计是一个sigmoid有界的熵项,它可以防止负熵驱动的优化朝向分布外的动作,并减少Q函数的振荡。我们在D4RL任务上针对代表性基线测试了SigEnt-SAC。实验表明,SigEnt-SAC显著减轻了Q函数的振荡,并且比先前的方法更快地达到100%的成功率。最后,我们在多个机器人上的四个真实世界机器人任务上验证了SigEnt-SAC,其中智能体从原始图像和稀疏奖励中学习;结果表明,SigEnt-SAC只需少量真实世界交互即可学习成功的策略,这为真实世界RL部署提供了一种低成本且实用的途径。
🔬 方法详解
问题定义:真实世界机器人强化学习面临样本效率低、奖励稀疏以及来自视觉输入的噪声干扰等问题。现有方法,如离线到在线学习和VLA辅助强化学习,通常需要大量数据或依赖大规模预训练,导致成本高昂且部署困难。因此,如何在数据有限的情况下,实现高效、稳定的真实世界机器人强化学习是一个亟待解决的问题。
核心思路:论文的核心思路是通过引入一个sigmoid有界的熵正则化项,来约束策略的探索空间,防止策略过度探索到分布外的动作,从而避免Q函数的剧烈振荡。这种方法旨在提高学习的稳定性和样本效率,使得智能体能够仅通过少量样本就能学习到有效的策略。
技术框架:SigEnt-SAC采用off-policy actor-critic框架,包括一个actor网络(策略网络)和一个或多个critic网络(Q函数网络)。智能体通过与环境交互收集经验数据,并利用这些数据更新actor和critic网络。Sigmoid有界熵正则化项被添加到actor网络的损失函数中,以约束策略的探索。整体流程包括:1)从单个专家轨迹初始化;2)使用off-policy数据更新actor和critic网络;3)使用sigmoid有界熵正则化项约束策略;4)重复步骤2和3直到收敛。
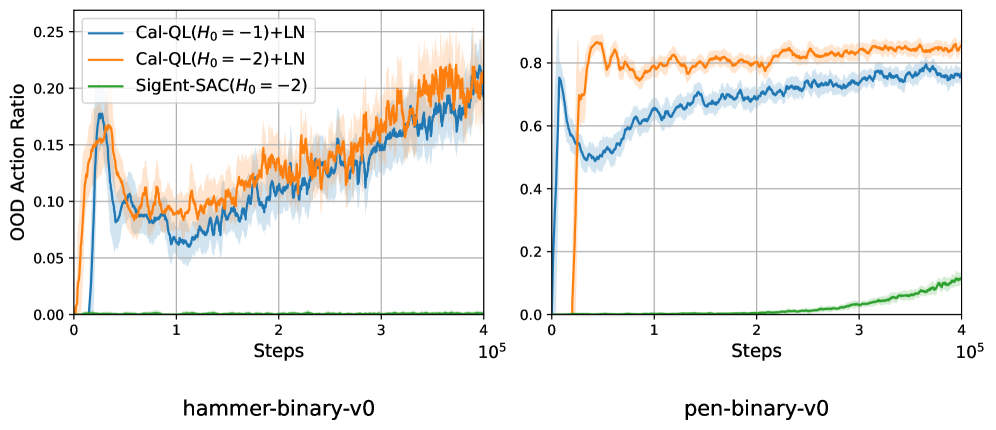
关键创新:该论文的关键创新在于提出了sigmoid有界熵正则化项。与传统的熵正则化方法不同,sigmoid有界熵正则化项能够更有效地约束策略的探索空间,防止策略过度探索到分布外的动作。这种约束能够显著减少Q函数的振荡,提高学习的稳定性和样本效率。
关键设计:Sigmoid有界熵正则化项的具体形式为:$\alpha \cdot sigmoid(H(\pi(a|s)))$,其中$\alpha$是一个可调节的超参数,用于控制熵正则化的强度,$H(\pi(a|s))$是策略$\pi(a|s)$的熵。sigmoid函数将熵的值限制在0到1之间,从而避免了负熵驱动的优化。此外,论文还采用了双Q函数结构,以减少Q函数的过估计偏差。
🖼️ 关键图片


📊 实验亮点
实验结果表明,SigEnt-SAC在D4RL benchmark上优于现有的off-policy算法,能够更快地达到100%的成功率。在真实机器人实验中,SigEnt-SAC仅需少量真实世界交互即可学习到有效的策略,证明了其在真实世界机器人控制中的实用性。例如,在四足机器人导航任务中,SigEnt-SAC能够仅通过少量尝试就学会避开障碍物并到达目标位置。
🎯 应用场景
SigEnt-SAC算法在真实机器人控制领域具有广泛的应用前景,例如:工业自动化、家庭服务机器人、自动驾驶等。该算法能够降低机器人学习的成本和时间,使其能够更快地适应新的任务和环境。此外,该算法还可以应用于其他需要高效、稳定强化学习的领域,例如:游戏AI、金融交易等。
📄 摘要(原文)
Deploying reinforcement learning in the real world remains challenging due to sample inefficiency, sparse rewards, and noisy visual observations. Prior work leverages demonstrations and human feedback to improve learning efficiency and robustness. However, offline-to-online methods need large datasets and can be unstable, while VLA-assisted RL relies on large-scale pretraining and fine-tuning. As a result, a low-cost real-world RL method with minimal data requirements has yet to emerge. We introduce \textbf{SigEnt-SAC}, an off-policy actor-critic method that learns from scratch using a single expert trajectory. Our key design is a sigmoid-bounded entropy term that prevents negative-entropy-driven optimization toward out-of-distribution actions and reduces Q-function oscillations. We benchmark SigEnt-SAC on D4RL tasks against representative baselines. Experiments show that SigEnt-SAC substantially alleviates Q-function oscillations and reaches a 100\% success rate faster than prior methods. Finally, we validate SigEnt-SAC on four real-world robotic tasks across multiple embodiments, where agents learn from raw images and sparse rewards; results demonstrate that SigEnt-SAC can learn successful policies with only a small number of real-world interactions, suggesting a low-cost and practical pathway for real-world RL deployment.