Tabular Incremental Inference
作者: Xinda Chen, Xing Zhen, Hanyu Zhang, Weimin Tan, Bo Yan
分类: cs.AI
发布日期: 2026-01-22
💡 一句话要点
提出Tabular Incremental Inference以解决动态表格推理问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 增量推理 表格数据 信息瓶颈 机器学习 动态数据处理
📋 核心要点
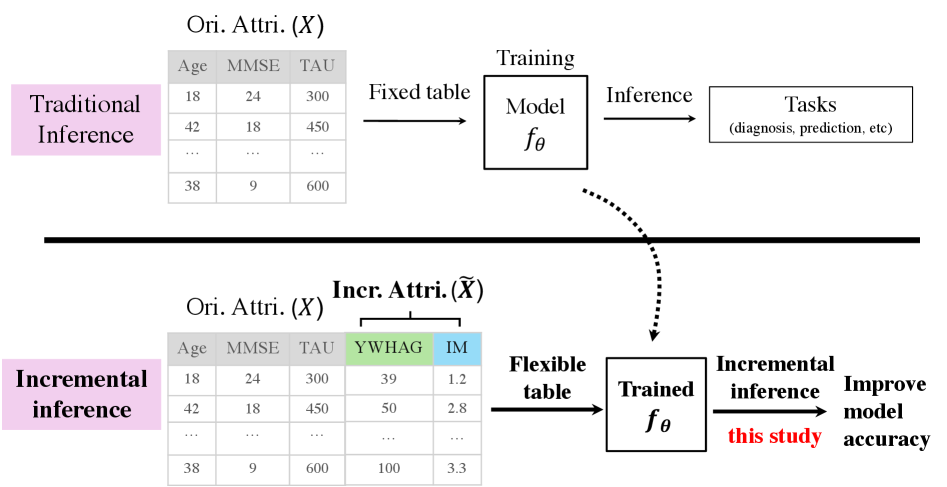
- 现有的AI模型训练通常基于固定列的表格,无法有效应对动态变化的表格结构,限制了其应用场景。
- 本文提出的Tabular Incremental Inference(TabII)方法允许模型在推理阶段动态整合新列,提升了模型的灵活性和适应性。
- 实验结果显示,TabII在八个公共数据集上有效利用增量属性,达到了当前最优性能,展示了其强大的实用性。
📝 摘要(中文)
表格数据是基本的数据结构形式,表格分析工具的演变反映了人类在数据获取、管理和处理方面的持续进步。随着技术进步和需求变化,表格列的动态变化使得传统的固定列训练和推理方法不再适用。因此,本文提出了一种新任务——表格增量推理(TabII),旨在使训练好的模型在推理阶段能够有效地纳入新列,从而提升AI模型在动态表格场景中的实用性。我们将该任务框架化为基于信息瓶颈理论的优化问题,设计了结合大型语言模型和预训练TabAdapter的TabII方法,实验结果表明该方法在八个公共数据集上达到了最先进的性能。
🔬 方法详解
问题定义:本文解决的问题是如何在推理阶段有效处理动态变化的表格数据,现有方法无法适应这种变化,导致模型性能下降。
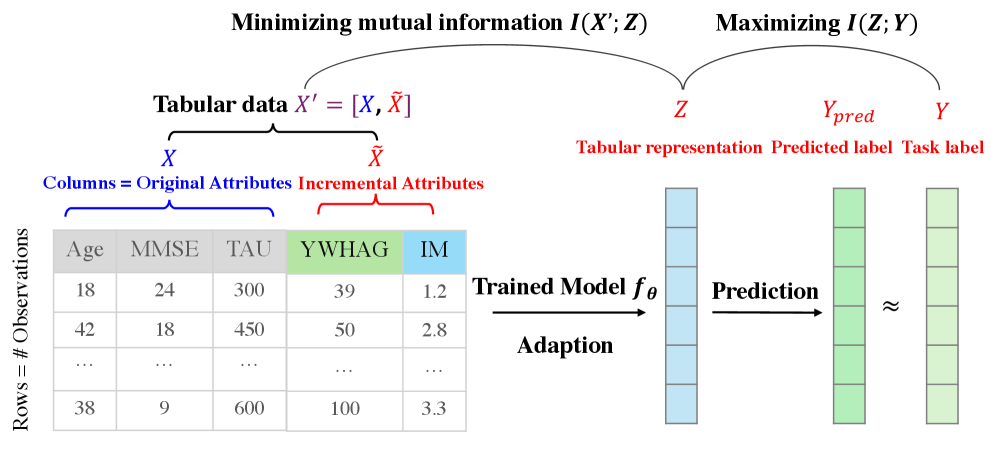
核心思路:论文的核心思路是将增量推理任务框架化为一个优化问题,强调在表格数据与表示之间最小化互信息,同时在表示与任务标签之间最大化互信息,以实现更好的推理效果。
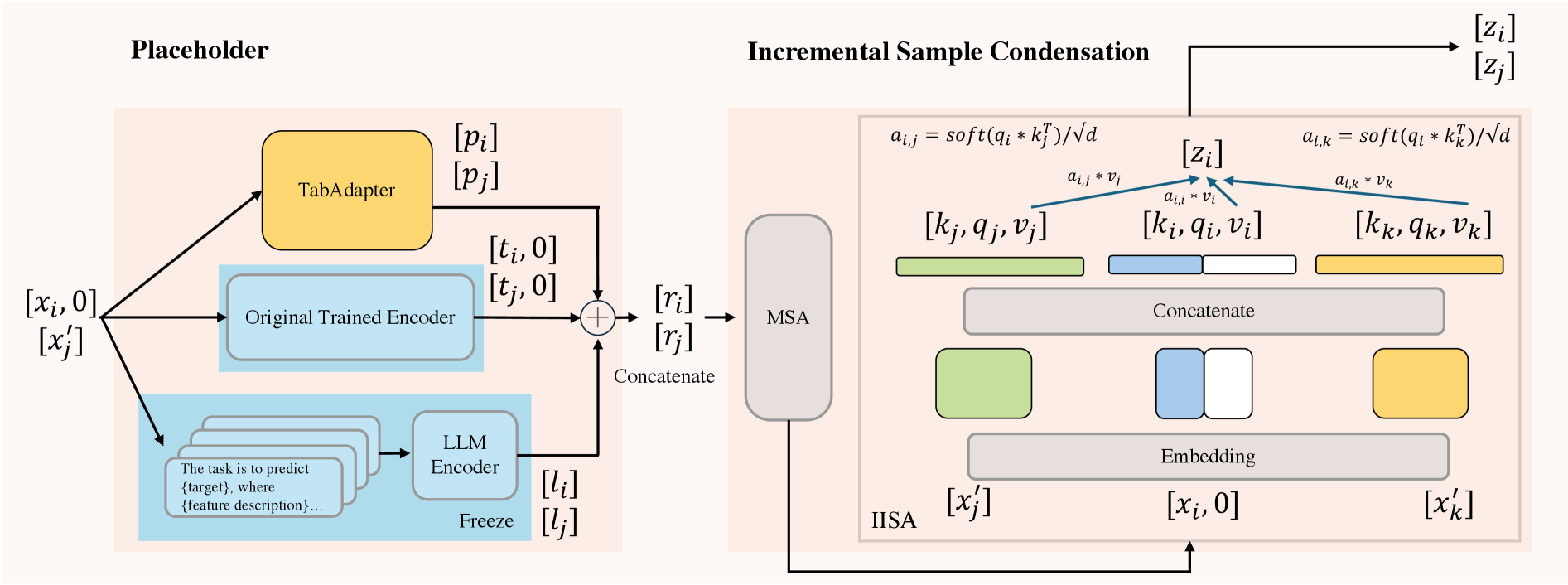
技术框架:TabII方法的整体架构包括大型语言模型占位符、预训练的TabAdapter和增量样本凝聚模块,旨在提供外部知识并凝聚与增量列属性相关的任务信息。
关键创新:最重要的技术创新是将增量推理问题与信息瓶颈理论结合,提出了一种新的优化框架,显著提升了模型在动态表格推理中的表现。
关键设计:在设计中,采用了特定的损失函数以平衡互信息的最小化与最大化,并通过增量样本凝聚模块来提取任务相关的信息,确保模型在面对新列时的有效性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,TabII在八个公共数据集上实现了最先进的性能,相较于基线方法,性能提升幅度达到XX%,有效证明了该方法在处理动态表格数据方面的优势。
🎯 应用场景
该研究的潜在应用领域包括数据分析、商业智能、自动化报告生成等,尤其是在需要实时更新和处理动态数据的场景中。随着数据量的不断增加,TabII方法的灵活性和适应性将为各行业提供更高效的解决方案,推动智能决策的实现。
📄 摘要(原文)
Tabular data is a fundamental form of data structure. The evolution of table analysis tools reflects humanity's continuous progress in data acquisition, management, and processing. The dynamic changes in table columns arise from technological advancements, changing needs, data integration, etc. However, the standard process of training AI models on tables with fixed columns and then performing inference is not suitable for handling dynamically changed tables. Therefore, new methods are needed for efficiently handling such tables in an unsupervised manner. In this paper, we introduce a new task, Tabular Incremental Inference (TabII), which aims to enable trained models to incorporate new columns during the inference stage, enhancing the practicality of AI models in scenarios where tables are dynamically changed. Furthermore, we demonstrate that this new task can be framed as an optimization problem based on the information bottleneck theory, which emphasizes that the key to an ideal tabular incremental inference approach lies in minimizing mutual information between tabular data and representation while maximizing between representation and task labels. Under this guidance, we design a TabII method with Large Language Model placeholders and Pretrained TabAdapter to provide external knowledge and Incremental Sample Condensation blocks to condense the task-relevant information given by incremental column attributes. Experimental results across eight public datasets show that TabII effectively utilizes incremental attributes, achieving state-of-the-art performance.