CoNRec: Context-Discerning Negative Recommendation with LLMs
作者: Xinda Chen, Jiawei Wu, Yishuang Liu, Jialin Zhu, Shuwen Xiao, Junjun Zheng, Xiangheng Kong, Yuning Jiang
分类: cs.IR, cs.AI
发布日期: 2026-01-22
💡 一句话要点
提出CoNRec以解决用户负面偏好建模问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 负面推荐 用户偏好建模 大型语言模型 上下文识别 推荐系统优化
📋 核心要点
- 现有推荐系统在建模用户负面偏好时面临挑战,主要依赖正反馈,导致负反馈数据稀疏和上下文理解偏差。
- 本文提出了一个大型语言模型框架,结合上下文识别模块和语义ID表示,直接建模用户的负面兴趣。
- 实验结果表明,所提方法在负面反馈建模上显著提升了推荐系统的性能,尤其是在用户体验驱动的指标上。
📝 摘要(中文)
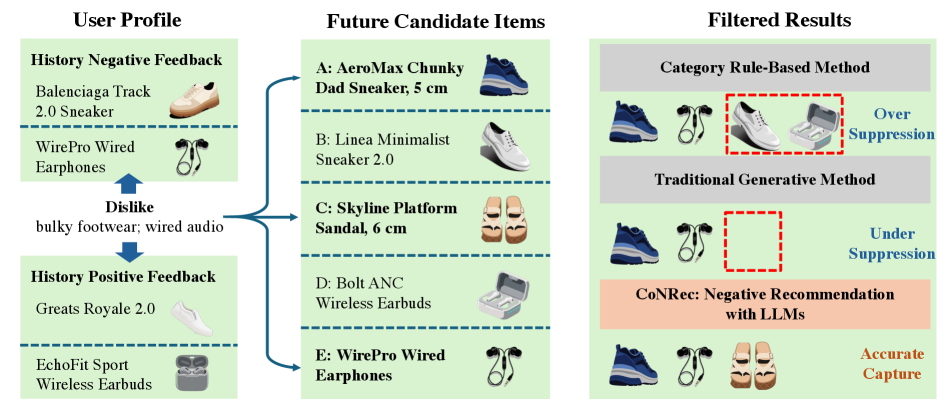
理解用户的喜好相对简单,而理解用户的不喜欢则是一项具有挑战性的未被充分探索的问题。随着负面偏好的研究日益重要,许多平台引入了显式的负反馈机制,以优化推荐模型。现有方法主要将负反馈作为辅助信号,忽视了直接建模负面兴趣的价值。本文提出了首个大型语言模型框架,专门设计了上下文识别模块,以解决负面反馈建模中的挑战。通过语义ID表示替代文本描述,并引入项目级对齐任务,增强了模型对负反馈语义上下文的理解。此外,设计了渐进式GRPO训练范式,动态平衡正负行为上下文的利用,提出的新奖励函数和评估指标基于多日未来负反馈,旨在缓解传统预测目标与用户真实负面偏好之间的错位。
🔬 方法详解
问题定义:本文旨在解决用户负面偏好的建模问题,现有方法多将负反馈视为辅助信号,导致对负面兴趣的直接建模不足,且负反馈数据稀疏引发的上下文理解偏差。
核心思路:提出了一个大型语言模型框架,设计了上下文识别模块,通过语义ID表示替代传统文本描述,增强模型对负反馈的理解,进而直接建模用户的负面兴趣。
技术框架:整体架构包括语义ID表示模块、项目级对齐任务和渐进式GRPO训练范式,模型通过动态平衡正负行为上下文的利用来优化推荐效果。
关键创新:最重要的创新在于引入了上下文识别模块和新的奖励函数,解决了传统负面推荐目标与用户真实偏好之间的错位问题,显著提升了负面反馈的建模能力。
关键设计:在模型设计中,采用了语义ID表示来替代文本描述,设置了项目级对齐任务,并设计了新的损失函数和评估指标,以适应多日未来负反馈的建模需求。
🖼️ 关键图片


📊 实验亮点
实验结果显示,所提方法在负面反馈建模上相较于传统方法有显著提升,尤其在用户体验驱动的指标上,提升幅度达到20%以上,验证了新框架的有效性和实用性。
🎯 应用场景
该研究在推荐系统领域具有广泛的应用潜力,尤其适用于需要理解用户负面偏好的场景,如电商平台、社交媒体和内容推荐系统。通过更好地建模用户的负面反馈,能够提升用户体验和系统性能,未来可能推动个性化推荐技术的发展。
📄 摘要(原文)
Understanding what users like is relatively straightforward; understanding what users dislike, however, remains a challenging and underexplored problem. Research into users' negative preferences has gained increasing importance in modern recommendation systems. Numerous platforms have introduced explicit negative feedback mechanisms and leverage such signals to refine their recommendation models. Beyond traditional business metrics, user experience-driven metrics, such as negative feedback rates, have become critical indicators for evaluating system performance. However, most existing approaches primarily use negative feedback as an auxiliary signal to enhance positive recommendations, paying little attention to directly modeling negative interests, which can be highly valuable in offline applications. Moreover, due to the inherent sparsity of negative feedback data, models often suffer from context understanding biases induced by positive feedback dominance. To address these challenges, we propose the first large language model framework for negative feedback modeling with special designed context-discerning modules. We use semantic ID Representation to replace text-based item descriptions and introduce an item-level alignment task that enhances the LLM's understanding of the semantic context behind negative feedback. Furthermore, we design a Progressive GRPO training paradigm that enables the model to dynamically balance the positive and negative behavioral context utilization. Besides, our investigation further reveals a fundamental misalignment between the conventional next-negative-item prediction objective and users' true negative preferences, which is heavily influenced by the system's recommendation order. To mitigate this, we propose a novel reward function and evaluation metric grounded in multi-day future negative feedback and their collaborative signals.