CogToM: A Comprehensive Theory of Mind Benchmark inspired by Human Cognition for Large Language Models
作者: Haibo Tong, Zeyang Yue, Feifei Zhao, Erliang Lin, Lu Jia, Ruolin Chen, Yinqian Sun, Qian Zhang, Yi Zeng
分类: cs.AI
发布日期: 2026-01-22
💡 一句话要点
CogToM:一个受人类认知启发的大语言模型心智理论综合基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 心智理论 大语言模型 认知基准 人类认知 智能评估
📋 核心要点
- 现有心智理论(ToM)基准主要集中于错误信念等任务,无法全面评估大语言模型(LLM)的认知能力。
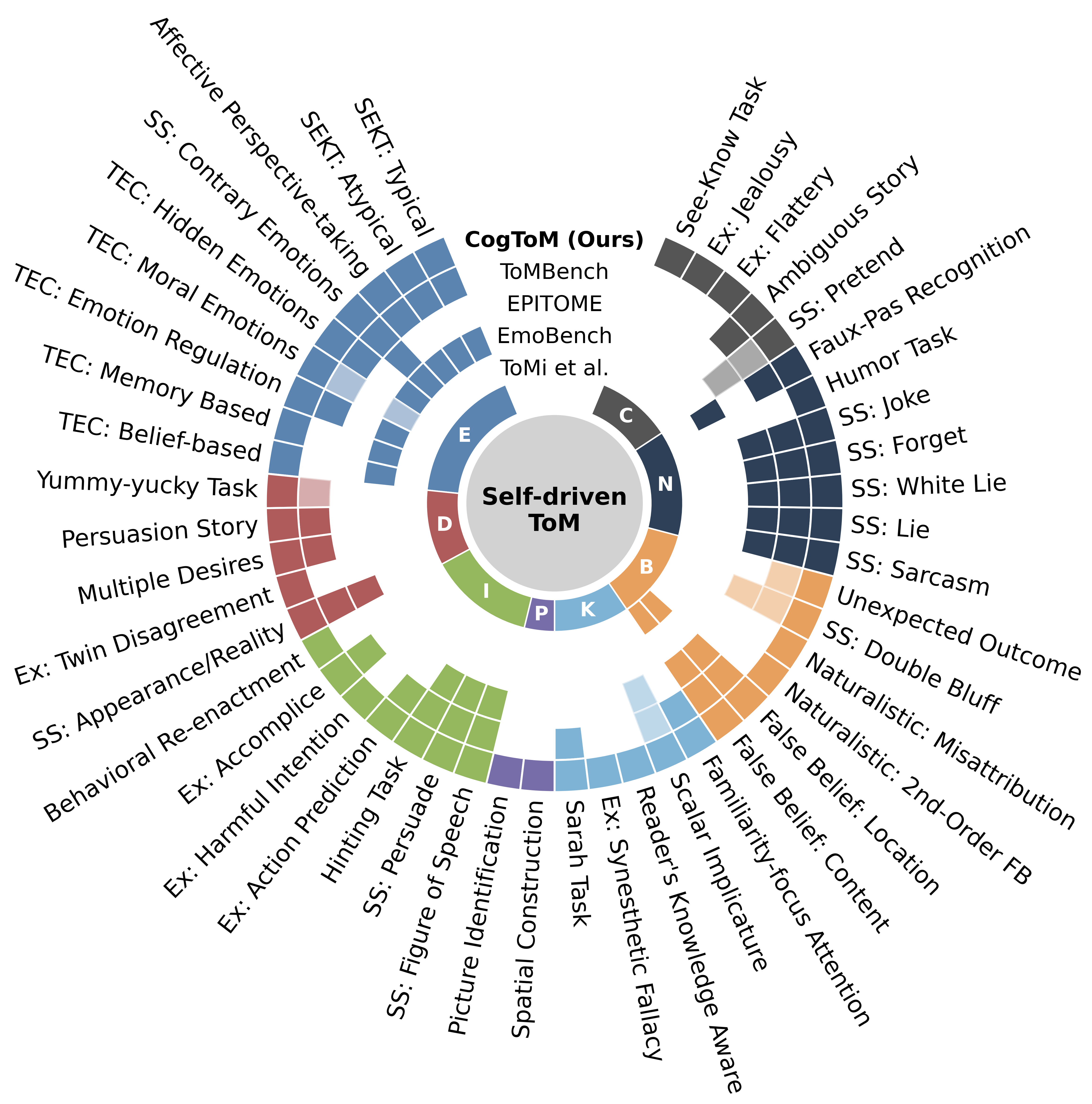
- CogToM基准通过模拟人类认知过程,构建包含46种范式的综合数据集,以更全面地评估LLM的ToM能力。
- 实验结果表明,LLM在不同ToM维度上表现出显著差异,且与人类认知模式存在潜在差异,揭示了LLM的认知局限性。
📝 摘要(中文)
本文提出了CogToM,一个受人类认知启发的心智理论(ToM)综合基准,旨在更全面地评估大型语言模型(LLM)是否真正具备类似人类的ToM能力。现有基准主要局限于错误信念任务等狭窄范式,无法捕捉人类认知机制的完整范围。CogToM包含超过8000个双语实例,涵盖46种范式,并经过49位人工标注者的验证。对包括GPT-5.1和Qwen3-Max等前沿模型在内的22个代表性模型进行的系统评估,揭示了显著的性能异质性,并突出了特定维度上的持续瓶颈。基于人类认知模式的进一步分析表明,LLM和人类认知结构之间可能存在差异。CogToM为研究LLM不断发展的认知边界提供了一个强大的工具和视角。
🔬 方法详解
问题定义:现有的大语言模型心智理论(ToM)评估基准主要集中在少数几种任务类型上,例如经典的错误信念任务。这些基准无法全面覆盖人类认知中ToM的各种维度,难以准确评估LLM是否真正具备类似人类的ToM能力。现有方法的痛点在于缺乏一个综合性的、理论驱动的评估框架,无法深入了解LLM在不同认知场景下的表现。
核心思路:CogToM的核心思路是构建一个受人类认知启发的综合性ToM基准,该基准包含多种不同的认知范式,能够更全面地评估LLM的ToM能力。通过模拟人类在不同认知场景下的推理过程,CogToM旨在揭示LLM在ToM方面的优势和不足,并为未来的研究提供指导。
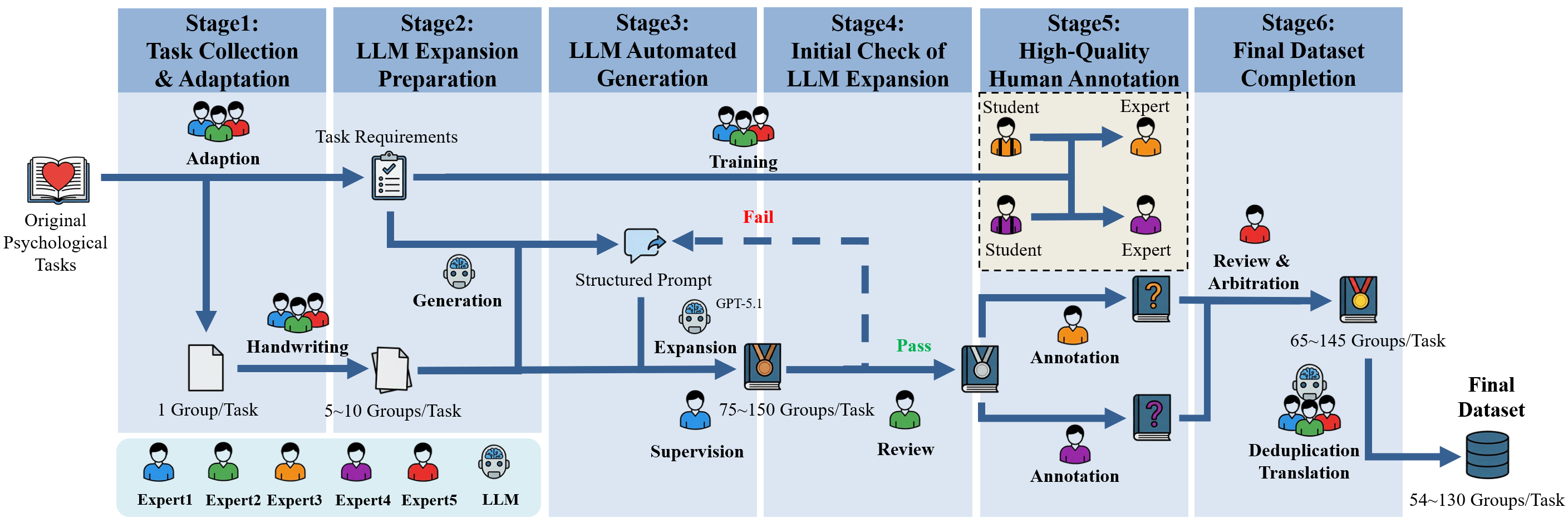
技术框架:CogToM基准包含超过8000个双语实例,涵盖46种不同的认知范式。这些范式的设计灵感来源于人类认知心理学和发展心理学中的经典实验。数据集的构建过程包括任务设计、数据收集、人工标注和质量控制等环节。为了保证数据的质量,论文使用了49位人工标注者对数据进行验证。
关键创新:CogToM的关键创新在于其综合性和理论驱动性。与以往的基准相比,CogToM覆盖了更广泛的认知范式,能够更全面地评估LLM的ToM能力。此外,CogToM的设计灵感来源于人类认知心理学和发展心理学,能够更好地反映人类的认知过程。这使得CogToM能够更准确地评估LLM是否真正具备类似人类的ToM能力。
关键设计:CogToM基准中的46种认知范式涵盖了ToM的不同维度,例如信念推理、意图识别、情感理解等。每个范式都包含多个实例,每个实例都包含一个情景描述和一个问题。LLM需要根据情景描述回答问题,以评估其在该范式下的ToM能力。论文还设计了一套评估指标,用于衡量LLM在不同范式下的表现。
🖼️ 关键图片

📊 实验亮点
对22个代表性模型(包括GPT-5.1和Qwen3-Max)的评估显示,LLM在不同ToM维度上表现出显著的性能异质性。例如,某些模型在错误信念任务上表现良好,但在情感理解任务上表现较差。此外,研究发现LLM的认知模式与人类认知模式存在潜在差异,表明LLM在ToM方面仍存在局限性。
🎯 应用场景
CogToM基准可用于评估和提升大语言模型在人机交互、智能体设计、教育和心理健康等领域的应用。通过更准确地评估LLM的心智理论能力,可以开发出更自然、更智能、更具同理心的人工智能系统,从而改善人机协作,并为心理疾病的诊断和治疗提供新的工具。
📄 摘要(原文)
Whether Large Language Models (LLMs) truly possess human-like Theory of Mind (ToM) capabilities has garnered increasing attention. However, existing benchmarks remain largely restricted to narrow paradigms like false belief tasks, failing to capture the full spectrum of human cognitive mechanisms. We introduce CogToM, a comprehensive, theoretically grounded benchmark comprising over 8000 bilingual instances across 46 paradigms, validated by 49 human annotator.A systematic evaluation of 22 representative models, including frontier models like GPT-5.1 and Qwen3-Max, reveals significant performance heterogeneities and highlights persistent bottlenecks in specific dimensions. Further analysis based on human cognitive patterns suggests potential divergences between LLM and human cognitive structures. CogToM offers a robust instrument and perspective for investigating the evolving cognitive boundaries of LLMs.