Data-Free Privacy-Preserving for LLMs via Model Inversion and Selective Unlearning
作者: Xinjie Zhou, Zhihui Yang, Lechao Cheng, Sai Wu, Gang Chen
分类: cs.CR, cs.AI, cs.LG
发布日期: 2026-01-22
💡 一句话要点
提出Data-Free Selective Unlearning (DFSU),解决LLM在无训练数据下的隐私保护问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 隐私保护 机器遗忘 选择性遗忘 模型反演 无数据学习
📋 核心要点
- 现有机器遗忘技术依赖于访问训练数据,这在实际应用中通常不可行,因为训练数据往往是专有的。
- DFSU通过语言模型反演生成伪PII数据,并利用token级别的隐私掩码和对比学习实现选择性遗忘。
- 实验表明,DFSU在删除目标PII的同时,能够有效保持模型的性能,具有实际应用价值。
📝 摘要(中文)
大型语言模型(LLMs)展现出强大的能力,但也存在记忆训练数据中敏感的个人身份信息(PII)的风险,从而引发严重的隐私问题。虽然机器遗忘技术旨在删除这些数据,但它们主要依赖于对训练数据的访问。这种要求通常是不切实际的,因为实际部署中的训练数据通常是专有的或无法访问的。为了解决这个限制,我们提出了一种新的隐私保护框架Data-Free Selective Unlearning (DFSU),该框架可以在不需要训练数据的情况下从LLM中删除敏感的PII。我们的方法首先通过语言模型反演合成伪PII,然后为这些合成样本构建token级别的隐私掩码,最后通过低秩适应(LoRA)子空间内的对比掩码损失执行token级别的选择性遗忘。在AI4Privacy PII-Masking数据集上使用Pythia模型进行的大量实验表明,我们的方法有效地删除了目标PII,同时保持了模型的效用。
🔬 方法详解
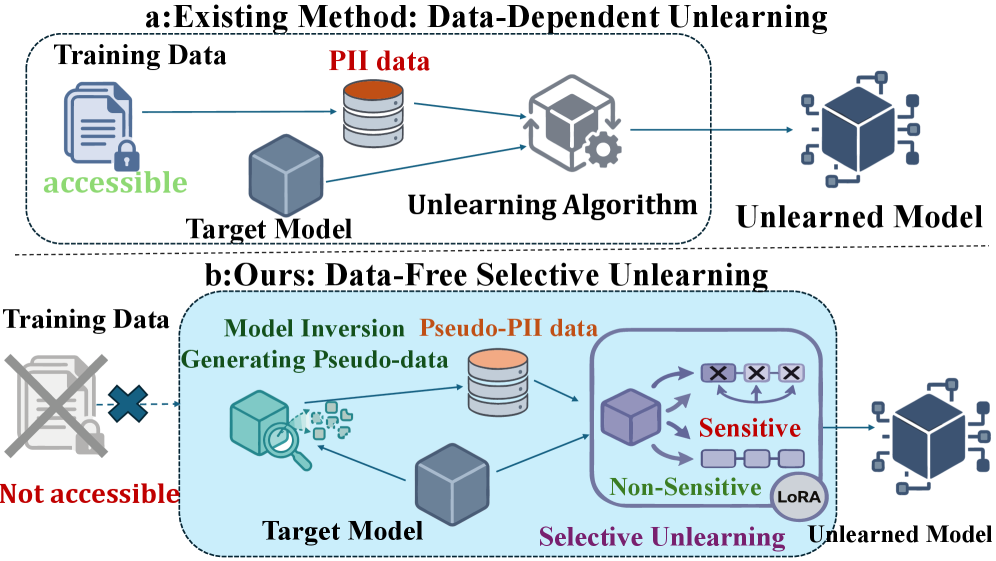
问题定义:大型语言模型容易记忆训练数据中的敏感个人信息(PII),造成隐私泄露风险。现有的机器遗忘方法通常需要访问原始训练数据,这在许多实际场景中是不可行的,因为数据通常是私有的或无法访问的。因此,如何在没有训练数据的情况下,从LLM中移除敏感信息,是一个亟待解决的问题。
核心思路:论文的核心思路是,首先通过模型反演技术生成与真实PII数据相似的伪数据,然后利用这些伪数据进行选择性遗忘训练。通过这种方式,可以在不访问原始训练数据的情况下,使模型“忘记”特定的敏感信息。这种方法的核心在于,伪数据能够有效地代表真实数据,从而实现有效的遗忘。
技术框架:DFSU框架主要包含三个阶段:1) 伪数据生成:利用语言模型反演技术,从LLM中提取可能泄露的PII信息,生成伪PII数据。2) 隐私掩码构建:为每个伪PII样本构建token级别的隐私掩码,用于标识需要遗忘的token。3) 选择性遗忘:通过对比学习,利用LoRA(Low-Rank Adaptation)技术,在LLM的低秩子空间中进行token级别的选择性遗忘训练。
关键创新:该方法最大的创新在于实现了在没有原始训练数据的情况下,对LLM进行选择性遗忘。这解决了传统机器遗忘方法对训练数据依赖的限制,使其更适用于实际应用场景。此外,利用语言模型反演技术生成伪数据,以及token级别的隐私掩码和对比学习,都为选择性遗忘提供了有效的手段。
关键设计:在伪数据生成阶段,使用了特定的prompt来引导LLM生成包含PII信息的文本。隐私掩码的构建基于token的重要性,例如使用梯度信息来确定哪些token对PII泄露的贡献最大。在选择性遗忘阶段,使用了对比损失函数,鼓励模型区分包含PII的文本和不包含PII的文本,从而实现对PII信息的遗忘。LoRA被用于在参数量较小的情况下进行高效的遗忘训练。
🖼️ 关键图片

📊 实验亮点
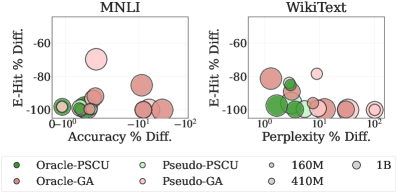
实验结果表明,DFSU能够在AI4Privacy PII-Masking数据集上有效地移除目标PII,同时保持模型的效用。具体来说,DFSU在移除PII的同时,对模型性能的影响较小,与基线方法相比,在保护隐私的同时,更好地维持了模型的生成能力。这些结果验证了DFSU在实际应用中的可行性和有效性。
🎯 应用场景
该研究成果可应用于各种需要保护用户隐私的LLM应用场景,例如智能客服、医疗诊断、金融风控等。通过DFSU,可以在不泄露原始训练数据的情况下,移除模型中可能存在的敏感信息,从而降低隐私泄露的风险,提升用户对LLM的信任度。未来,该技术还可以扩展到其他类型的机器学习模型,为更广泛的隐私保护应用提供支持。
📄 摘要(原文)
Large language models (LLMs) exhibit powerful capabilities but risk memorizing sensitive personally identifiable information (PII) from their training data, posing significant privacy concerns. While machine unlearning techniques aim to remove such data, they predominantly depend on access to the training data. This requirement is often impractical, as training data in real-world deployments is commonly proprietary or inaccessible. To address this limitation, we propose Data-Free Selective Unlearning (DFSU), a novel privacy-preserving framework that removes sensitive PII from an LLM without requiring its training data. Our approach first synthesizes pseudo-PII through language model inversion, then constructs token-level privacy masks for these synthetic samples, and finally performs token-level selective unlearning via a contrastive mask loss within a low-rank adaptation (LoRA) subspace. Extensive experiments on the AI4Privacy PII-Masking dataset using Pythia models demonstrate that our method effectively removes target PII while maintaining model utility.