MapViT: A Two-Stage ViT-Based Framework for Real-Time Radio Quality Map Prediction in Dynamic Environments
作者: Cyril Shih-Huan Hsu, Xi Li, Lanfranco Zanzi, Zhiheng Yang, Chrysa Papagianni, Xavier Costa Pérez
分类: cs.NI, cs.AI, cs.LG, cs.RO
发布日期: 2026-01-22
备注: This paper has been accepted for publication at IEEE International Conference on Communications (ICC) 2026
💡 一句话要点
提出MapViT,一种基于ViT的两阶段框架,用于动态环境中实时预测无线电质量地图。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 无线电质量预测 Vision Transformer 自监督学习 预训练微调 机器人导航
📋 核心要点
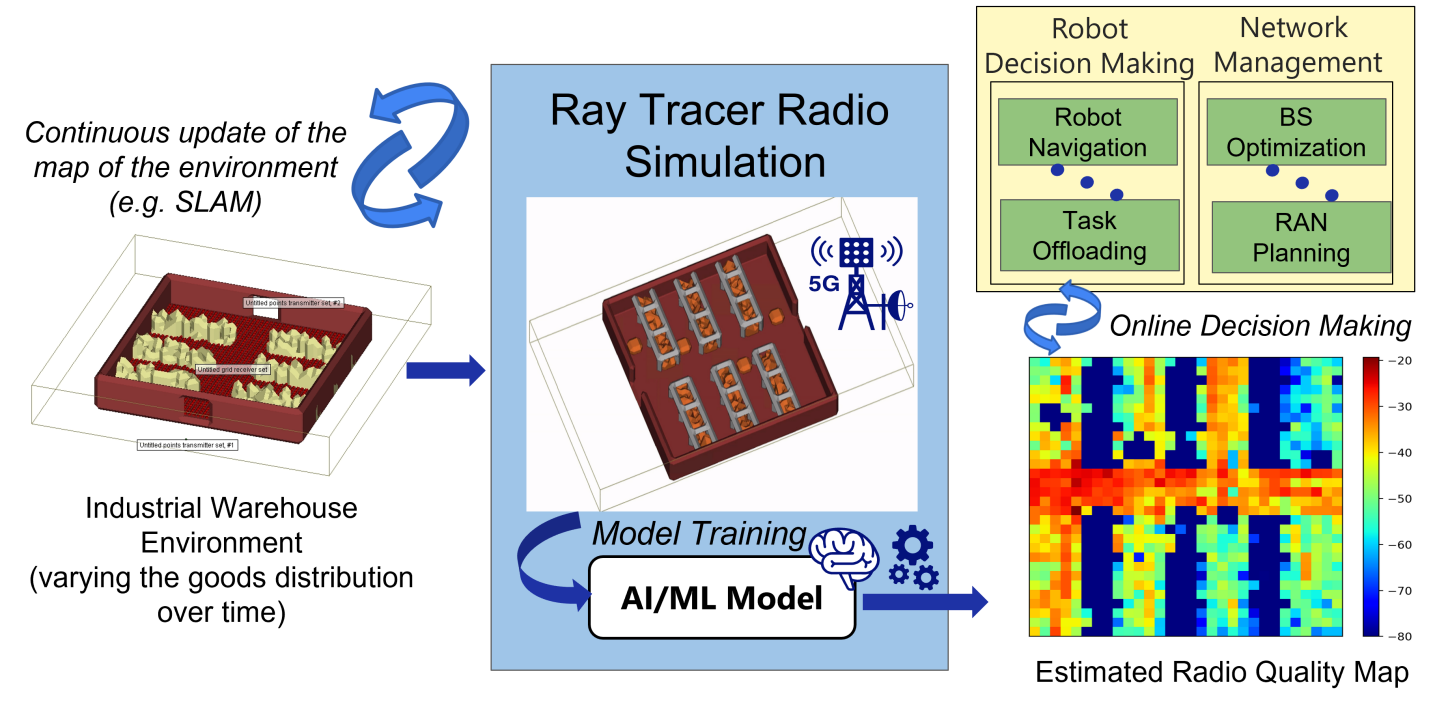
- 在动态环境中,机器人需要准确理解环境和无线电信号质量,但现有方法难以应对环境的快速变化。
- MapViT采用两阶段ViT框架,借鉴LLM的预训练和微调思想,分别学习环境几何特征和预测无线电信号质量。
- 实验表明,MapViT在准确性和计算效率之间取得了平衡,适用于资源受限的移动平台,并提高了数据效率和可迁移性。
📝 摘要(中文)
移动和无线网络的最新进展正在释放机器人自主性的全部潜力,使机器人能够利用超低延迟、高数据吞吐量和普遍连接。然而,为了使机器人能够无缝、高效和可靠地导航和操作,它们必须准确了解周围环境和无线电信号质量。在高度动态和不断变化的环境中实现这一点仍然是一个具有挑战性且很大程度上未解决的问题。在本文中,我们介绍MapViT,一个基于Vision Transformer (ViT)的两阶段框架,其灵感来自大型语言模型 (LLM) 的预训练和微调范式的成功。MapViT 旨在预测环境变化和预期的无线电信号质量。我们使用一组具有代表性的机器学习 (ML) 模型评估该框架,分析它们在不同场景中的各自优势和局限性。实验结果表明,所提出的两阶段流水线能够实现实时预测,基于 ViT 的实现方案在准确性和计算效率之间取得了良好的平衡。这使得 MapViT 成为移动机器人等能源和资源受限平台的有希望的解决方案。此外,从自监督预训练阶段导出的几何基础模型提高了数据效率和可迁移性,即使在标记数据有限的情况下也能实现有效的下游预测。总的来说,这项工作为下一代数字孪生生态系统奠定了基础,并为推动未来 6G 支持系统中多模态智能的新型 ML 基础模型铺平了道路。
🔬 方法详解
问题定义:论文旨在解决动态环境中机器人实时预测无线电质量地图的问题。现有方法难以在快速变化的环境中提供准确的无线电信号质量预测,并且通常需要大量的标记数据进行训练,这在实际应用中是不切实际的。
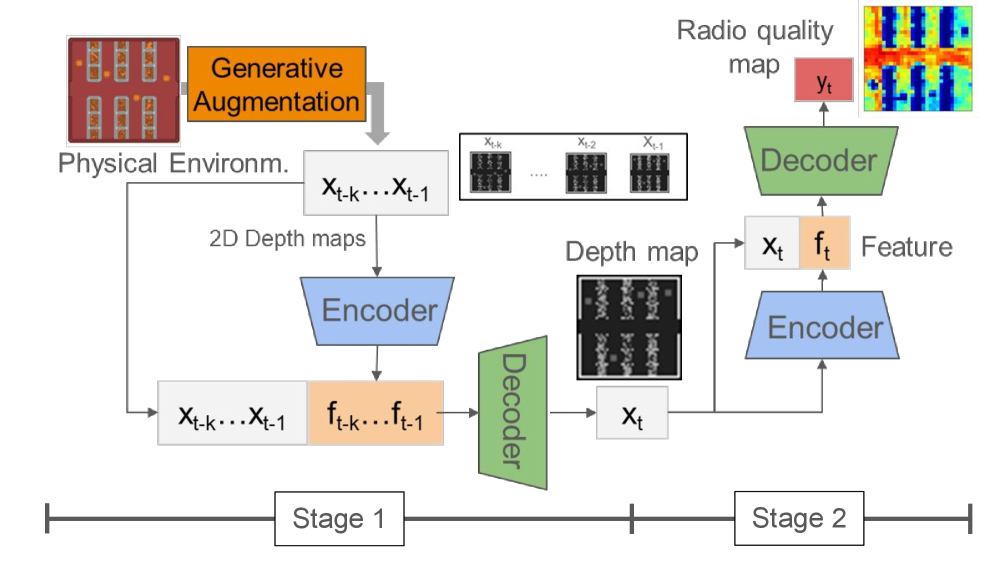
核心思路:论文的核心思路是借鉴大型语言模型(LLM)的预训练和微调范式,利用Vision Transformer(ViT)构建一个两阶段的框架。第一阶段通过自监督学习提取环境的几何特征,构建几何基础模型。第二阶段利用预训练的几何基础模型,结合少量标记数据,微调模型以预测无线电信号质量。这种方法可以提高数据效率和模型的可迁移性。
技术框架:MapViT框架包含两个主要阶段:1) 几何预训练阶段:使用自监督学习方法,例如对比学习或掩码图像建模,在大量无标记的环境数据上训练ViT模型,使其学习环境的几何特征。2) 无线电质量预测阶段:使用少量标记的无线电信号质量数据,微调预训练的ViT模型,使其能够预测给定环境下的无线电信号质量。整个流程包括数据预处理、模型训练、模型评估和部署。
关键创新:MapViT的关键创新在于将LLM的预训练和微调范式引入到无线电质量地图预测领域。通过自监督学习构建几何基础模型,可以有效地利用无标记数据,提高数据效率和模型的可迁移性。此外,使用ViT作为基础模型,可以有效地提取图像特征,并实现实时预测。
关键设计:在几何预训练阶段,论文可能采用了对比学习损失函数,例如InfoNCE,来最大化相似环境图像之间的相似性,并最小化不同环境图像之间的相似性。在无线电质量预测阶段,论文可能采用了均方误差(MSE)或交叉熵损失函数,来衡量预测的无线电信号质量与真实值之间的差异。ViT模型的具体结构(例如,Transformer块的数量、注意力头的数量、嵌入维度)需要根据具体的数据集和计算资源进行调整。
🖼️ 关键图片
📊 实验亮点
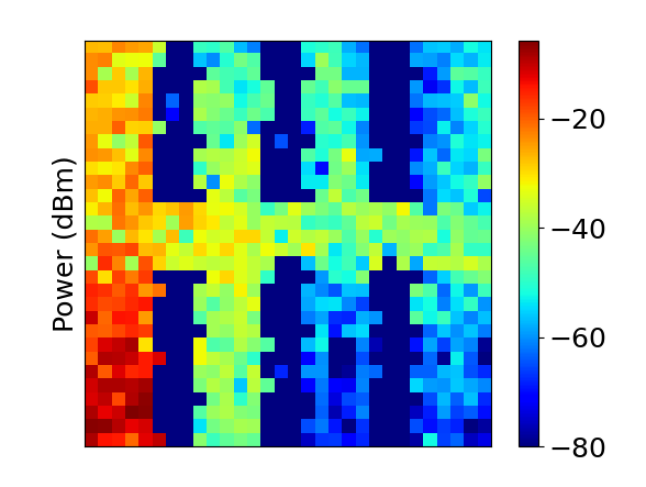
实验结果表明,MapViT在实时预测无线电质量地图方面表现出色,在准确性和计算效率之间取得了良好的平衡。与传统的机器学习模型相比,MapViT在数据效率和可迁移性方面具有显著优势,即使在标记数据有限的情况下也能实现有效的预测。具体性能数据(例如,预测精度、召回率、F1-score)未知,但论文强调了ViT在资源受限平台上的适用性。
🎯 应用场景
MapViT可应用于机器人导航、自动驾驶、无人机巡检等领域,帮助设备在复杂动态环境中实现可靠的无线通信和定位。该研究为构建下一代数字孪生生态系统奠定了基础,并推动了6G通信系统中多模态智能的发展,具有重要的实际应用价值和未来发展潜力。
📄 摘要(原文)
Recent advancements in mobile and wireless networks are unlocking the full potential of robotic autonomy, enabling robots to take advantage of ultra-low latency, high data throughput, and ubiquitous connectivity. However, for robots to navigate and operate seamlessly, efficiently and reliably, they must have an accurate understanding of both their surrounding environment and the quality of radio signals. Achieving this in highly dynamic and ever-changing environments remains a challenging and largely unsolved problem. In this paper, we introduce MapViT, a two-stage Vision Transformer (ViT)-based framework inspired by the success of pre-train and fine-tune paradigm for Large Language Models (LLMs). MapViT is designed to predict both environmental changes and expected radio signal quality. We evaluate the framework using a set of representative Machine Learning (ML) models, analyzing their respective strengths and limitations across different scenarios. Experimental results demonstrate that the proposed two-stage pipeline enables real-time prediction, with the ViT-based implementation achieving a strong balance between accuracy and computational efficiency. This makes MapViT a promising solution for energy- and resource-constrained platforms such as mobile robots. Moreover, the geometry foundation model derived from the self-supervised pre-training stage improves data efficiency and transferability, enabling effective downstream predictions even with limited labeled data. Overall, this work lays the foundation for next-generation digital twin ecosystems, and it paves the way for a new class of ML foundation models driving multi-modal intelligence in future 6G-enabled systems.