Evaluation of Large Language Models in Legal Applications: Challenges, Methods, and Future Directions
作者: Yiran Hu, Huanghai Liu, Chong Wang, Kunran Li, Tien-Hsuan Wu, Haitao Li, Xinran Xu, Siqing Huo, Weihang Su, Ning Zheng, Siyuan Zheng, Qingyao Ai, Yun Liu, Renjun Bian, Yiqun Liu, Charles L. A. Clarke, Weixing Shen, Ben Kao
分类: cs.CY, cs.AI, cs.CL
发布日期: 2026-01-21
💡 一句话要点
综述:评估大语言模型在法律应用中的挑战、方法与未来方向
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 法律应用 评估方法 法律推理 可信赖性
📋 核心要点
- 现有法律领域的大语言模型评估缺乏对推理过程合理性和可信赖问题的深入考察,仅关注表面准确性。
- 该综述旨在识别法律领域LLM评估的关键挑战,并分析现有评估方法在应对这些挑战时的局限性。
- 通过对现有评估方法和基准进行分类和回顾,为未来构建更现实、可靠和具有法律基础的评估框架提供方向。
📝 摘要(中文)
大型语言模型(LLMs)正日益融入法律应用,包括司法决策支持、法律实践辅助和面向公众的法律服务。尽管LLMs在处理法律知识和任务方面显示出强大的潜力,但它们在现实法律环境中的部署引发了关键问题,这些问题超越了表面准确性,涉及法律推理过程的合理性以及公平性和可靠性等可信赖问题。因此,系统地评估LLM在法律任务中的表现对于其负责任的应用至关重要。本综述确定了在评估LLM用于基于现实法律实践的法律任务时面临的关键挑战。我们分析了评估LLM在法律领域表现时涉及的主要困难,包括结果正确性、推理可靠性和可信赖性。基于这些挑战,我们根据任务设计、数据集和评估指标,回顾并分类了现有的评估方法和基准。我们进一步讨论了当前方法在多大程度上解决了这些挑战,强调了它们的局限性,并概述了未来研究方向,以实现更现实、可靠和具有法律基础的LLM法律领域评估框架。
🔬 方法详解
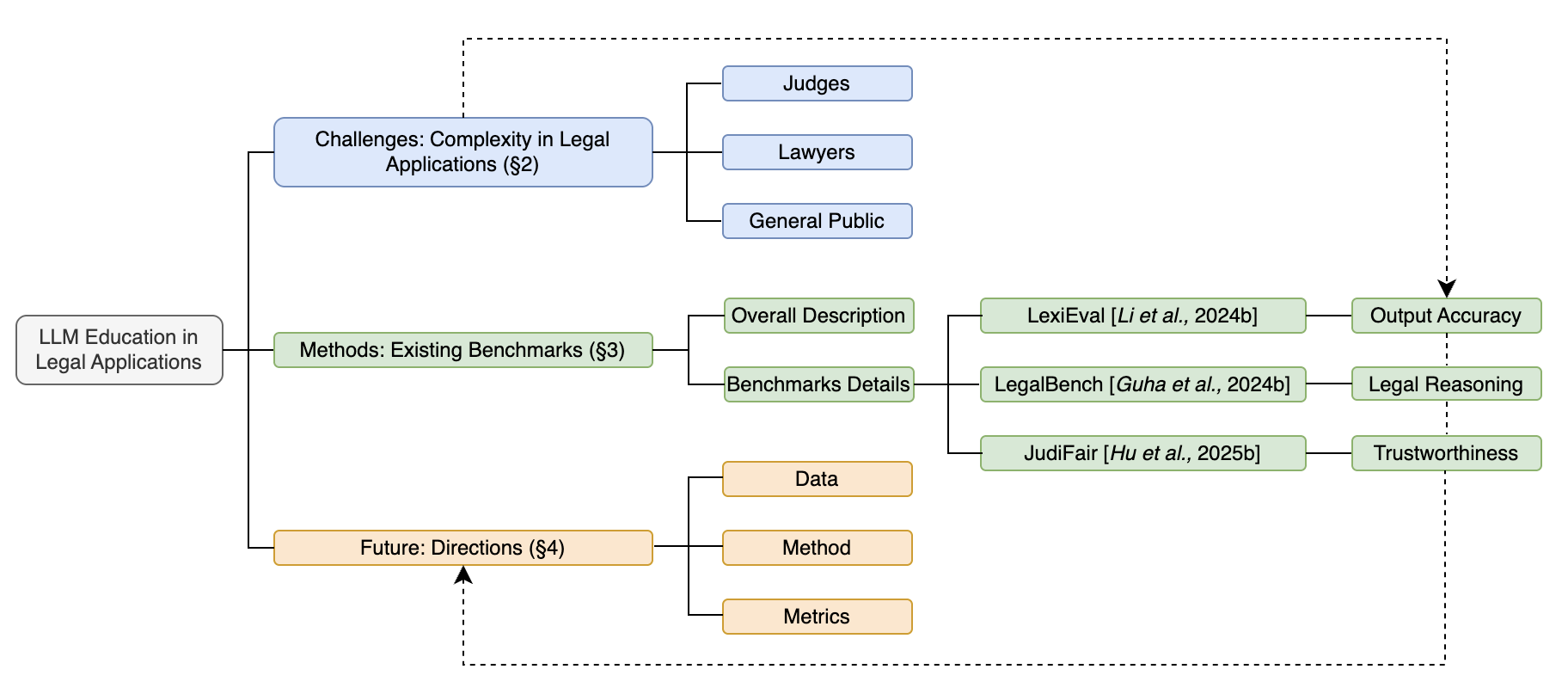
问题定义:论文旨在解决如何系统性地评估大语言模型(LLMs)在法律领域应用中的性能问题。现有方法主要关注结果的表面准确性,忽略了法律推理过程的可靠性、公平性以及其他可信赖性问题。此外,现有的评估方法和基准难以全面覆盖现实法律实践中的复杂场景和挑战。
核心思路:论文的核心思路是首先识别并分析法律领域LLM评估的关键挑战,包括结果正确性、推理可靠性和可信赖性。然后,对现有评估方法和基准进行分类和回顾,分析它们在应对这些挑战时的局限性。最后,基于这些分析,提出未来研究方向,旨在构建更现实、可靠和具有法律基础的评估框架。
技术框架:该论文采用综述的形式,没有提出新的技术框架。其主要框架包括:1) 识别法律领域LLM评估的关键挑战;2) 对现有评估方法和基准进行分类和回顾;3) 讨论现有方法在应对这些挑战时的局限性;4) 提出未来研究方向。
关键创新:该论文的主要创新在于其系统性地识别和分析了法律领域LLM评估的关键挑战,并对现有评估方法和基准进行了全面的回顾和分类。与现有研究相比,该论文更加关注法律推理过程的可靠性和可信赖性,并提出了未来研究方向,旨在构建更现实、可靠和具有法律基础的评估框架。
关键设计:该论文没有涉及具体的参数设置、损失函数或网络结构等技术细节。其主要关注的是对现有评估方法和基准的分类和回顾,以及对未来研究方向的展望。
🖼️ 关键图片
📊 实验亮点
该论文是一篇综述性文章,没有提供具体的实验结果。其主要贡献在于系统性地识别和分析了法律领域LLM评估的关键挑战,并对现有评估方法和基准进行了全面的回顾和分类,为未来的研究提供了重要的参考。
🎯 应用场景
该研究成果可应用于指导法律领域大语言模型的开发和部署,例如司法决策支持系统、法律咨询助手等。通过构建更可靠的评估框架,可以提高LLM在法律领域的应用效果和可信度,从而更好地服务于法律专业人士和公众。
📄 摘要(原文)
Large language models (LLMs) are being increasingly integrated into legal applications, including judicial decision support, legal practice assistance, and public-facing legal services. While LLMs show strong potential in handling legal knowledge and tasks, their deployment in real-world legal settings raises critical concerns beyond surface-level accuracy, involving the soundness of legal reasoning processes and trustworthy issues such as fairness and reliability. Systematic evaluation of LLM performance in legal tasks has therefore become essential for their responsible adoption. This survey identifies key challenges in evaluating LLMs for legal tasks grounded in real-world legal practice. We analyze the major difficulties involved in assessing LLM performance in the legal domain, including outcome correctness, reasoning reliability, and trustworthiness. Building on these challenges, we review and categorize existing evaluation methods and benchmarks according to their task design, datasets, and evaluation metrics. We further discuss the extent to which current approaches address these challenges, highlight their limitations, and outline future research directions toward more realistic, reliable, and legally grounded evaluation frameworks for LLMs in legal domains.