Benchmarking Large Language Models for ABAP Code Generation: An Empirical Study on Iterative Improvement by Compiler Feedback
作者: Stephan Wallraven, Tim Köhne, Hartmut Westenberger, Andreas Moser
分类: cs.SE, cs.AI, cs.PL
发布日期: 2026-01-21
备注: 20 pages, 10 figures, Author: Hartmut Westenberger (ORCID: 0009-0009-9063-8318)
💡 一句话要点
评估大语言模型在ABAP代码生成中的性能,着重分析编译器反馈的迭代改进效果
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: ABAP代码生成 大语言模型 编译器反馈 迭代改进 基准测试
📋 核心要点
- 现有ABAP代码生成缺乏系统性分析,阻碍了LLM在该领域的有效应用和潜力挖掘。
- 利用编译器反馈进行迭代改进是核心思路,旨在提升LLM生成ABAP代码的正确性和功能性。
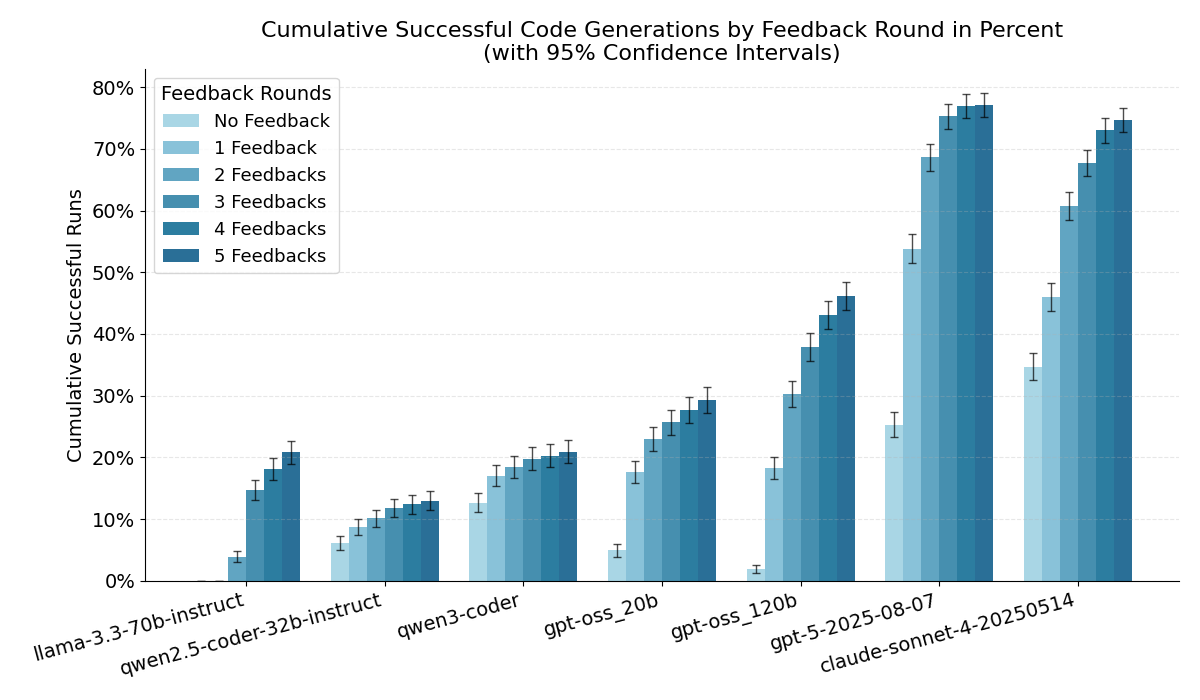
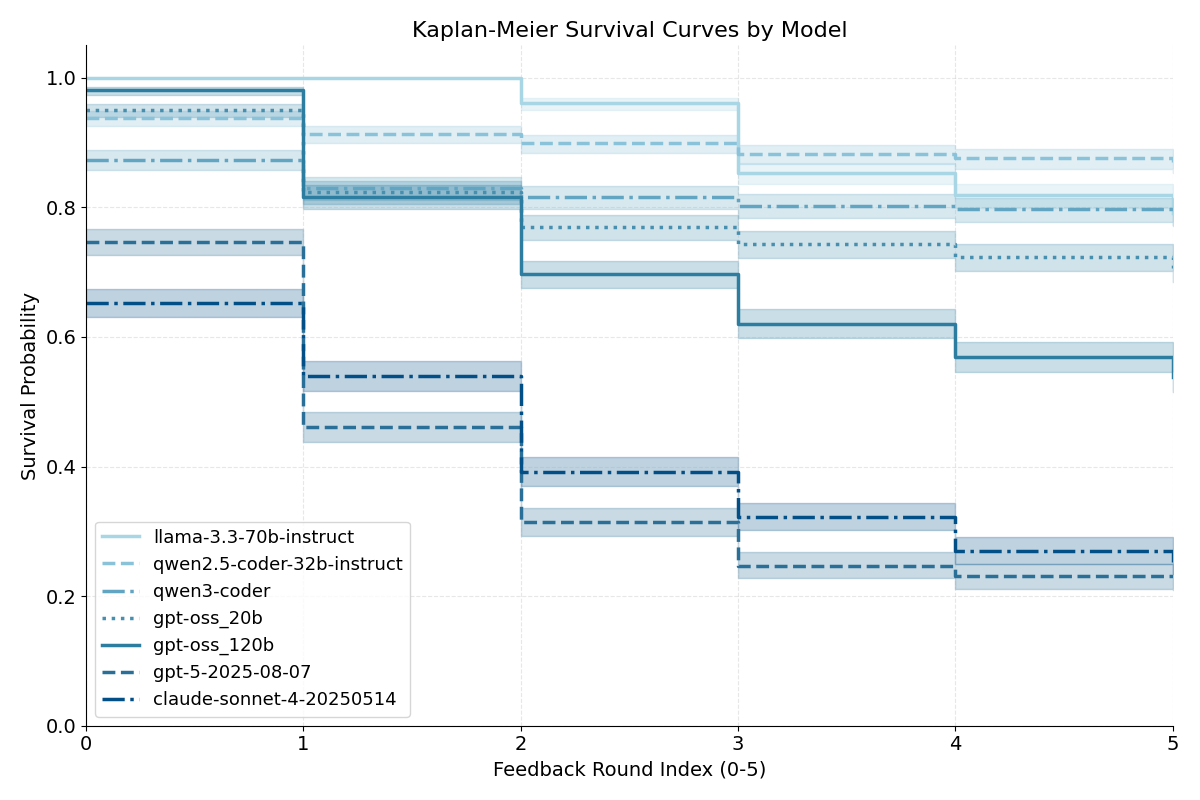
- 实验结果表明,更强大的LLM在ABAP代码生成任务中表现出色,成功率高达75%左右。
📝 摘要(中文)
本研究旨在评估大语言模型(LLM)在生成ABAP代码方面的性能。尽管生成式AI已在多种编程语言中成功应用,但迄今为止,对ABAP代码生成的系统性分析还很少。本研究旨在通过实证分析,考察各种LLM生成语法正确且功能性ABAP代码的能力,它们利用编译器反馈进行迭代改进的效率,以及哪些任务类型构成特殊挑战。为此,我们进行了一项包含180个任务的基准测试,其中包括改编自HumanEval的任务和实际的SAP场景。结果表明,不同模型之间的性能存在显著差异:更强大的LLM在多次迭代后成功率达到75%左右,并极大地受益于编译器反馈,而较小的模型表现明显较弱。总的来说,该研究突出了强大的LLM在ABAP开发过程中的巨大潜力,尤其是在迭代错误纠正方面。
🔬 方法详解
问题定义:该论文旨在解决大语言模型在ABAP代码生成任务中的性能评估问题。现有方法缺乏对ABAP代码生成的系统性分析,无法充分了解不同LLM在该任务上的能力,以及如何利用编译器反馈进行迭代改进。这阻碍了LLM在ABAP开发中的应用和潜力挖掘。
核心思路:论文的核心思路是通过构建一个包含多种ABAP代码生成任务的基准测试,并利用编译器反馈进行迭代改进,从而系统性地评估不同LLM的性能。通过分析LLM在不同任务上的表现,以及它们利用编译器反馈的能力,可以深入了解LLM在ABAP代码生成方面的优势和局限性。
技术框架:该研究的技术框架主要包括以下几个阶段:1) 构建ABAP代码生成基准测试,包含改编自HumanEval的任务和实际的SAP场景。2) 选择多个LLM进行测试,包括不同规模和架构的模型。3) 利用编译器反馈进行迭代改进,即LLM根据编译器返回的错误信息,对生成的代码进行修改和优化。4) 评估LLM在不同任务上的性能,包括语法正确率、功能正确率等。
关键创新:该研究的关键创新在于:1) 首次对LLM在ABAP代码生成任务中的性能进行系统性分析。2) 提出利用编译器反馈进行迭代改进的方法,可以有效提升LLM生成ABAP代码的质量。3) 构建了一个包含多种ABAP代码生成任务的基准测试,为后续研究提供了参考。
关键设计:基准测试包含180个任务,涵盖不同难度和类型的ABAP代码生成场景。选择的LLM包括不同规模和架构的模型,以便比较不同模型的性能。编译器反馈用于指导LLM进行迭代改进,每次迭代后都会重新评估代码的正确性。性能评估指标包括语法正确率、功能正确率等。
🖼️ 关键图片
📊 实验亮点
实验结果表明,更强大的LLM在ABAP代码生成任务中表现出色,经过多次迭代和编译器反馈,成功率达到75%左右。相比之下,较小的模型性能明显较弱,表明模型规模对ABAP代码生成至关重要。该研究还发现,编译器反馈对提升LLM的性能有显著作用。
🎯 应用场景
该研究成果可应用于ABAP代码的自动生成、代码补全、代码修复等领域,提高ABAP开发效率,降低开发成本。未来,可以将该研究扩展到其他编程语言,推动软件开发的自动化和智能化。
📄 摘要(原文)
This work investigates the performance of Large Language Models (LLMs) in generating ABAP code. Despite successful applications of generative AI in many programming languages, there are hardly any systematic analyses of ABAP code generation to date. The aim of the study is to empirically analyze to what extent various LLMs can generate syntactically correct and functional ABAP code, how effectively they use compiler feedback for iterative improvement, and which task types pose special challenges. For this purpose, a benchmark with 180 tasks is conducted, consisting of adapted HumanEval tasks and practical SAP scenarios. The results show significant performance differences between the models: more powerful LLMs achieve success rates of around 75% after several iterations and benefit greatly from compiler feedback, while smaller models perform significantly weaker. Overall, the study highlights the high potential of powerful LLMs for ABAP development processes, especially in iterative error correction.