Vehicle Routing with Finite Time Horizon using Deep Reinforcement Learning with Improved Network Embedding
作者: Ayan Maity, Sudeshna Sarkar
分类: cs.AI
发布日期: 2026-01-21
备注: Accepted at AAAI-26 Workshop on AI for Urban Planning
💡 一句话要点
提出一种改进网络嵌入的深度强化学习方法,解决有限时间范围内的车辆路径问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 车辆路径问题 有限时间范围 深度强化学习 网络嵌入 图神经网络
📋 核心要点
- 现有车辆路径方法难以在有限时间范围内最大化客户服务率,尤其是在复杂网络中。
- 论文提出一种新颖的路由网络嵌入模块,结合局部节点嵌入和全局图表示,并考虑剩余时间。
- 实验表明,该方法在真实和合成网络中均优于现有方法,显著提高了客户服务率并缩短了求解时间。
📝 摘要(中文)
本文研究了具有有限时间范围的车辆路径问题。该问题的目标是在有限的时间范围内最大化服务的客户请求数量。我们提出了一种新颖的路由网络嵌入模块,该模块创建局部节点嵌入向量和上下文感知的全局图表示。针对车辆路径问题,我们提出的马尔可夫决策过程将节点特征、网络邻接矩阵和边特征作为状态空间的组成部分。我们将剩余的有限时间范围纳入网络嵌入模块,为嵌入模块提供适当的路由上下文。我们将嵌入模块与基于策略梯度的深度强化学习框架相结合,以解决有限时间范围内的车辆路径问题。我们在真实世界的路由网络以及合成生成的欧几里德网络上训练和验证了我们提出的路由方法。实验结果表明,我们的方法比现有的路由方法实现了更高的客户服务率,并且解决方案时间明显更短。
🔬 方法详解
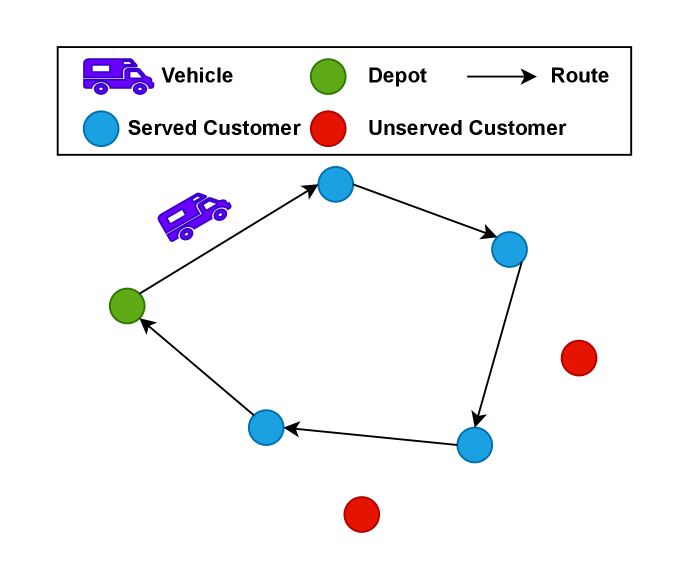
问题定义:本文旨在解决有限时间范围内的车辆路径问题(Vehicle Routing Problem with Finite Time Horizon)。传统方法在处理此类问题时,往往难以兼顾服务客户数量的最大化和时间约束的满足,尤其是在大规模、复杂的路网环境中,容易陷入局部最优解,导致客户服务率不高,求解时间较长。
核心思路:论文的核心思路是将车辆路径问题建模为马尔可夫决策过程(MDP),并利用深度强化学习(DRL)方法进行求解。关键在于设计一个有效的网络嵌入模块,该模块能够学习到节点和边的局部特征以及全局上下文信息,同时将剩余时间信息融入到嵌入表示中,从而为智能体提供更全面的状态信息,指导其做出更明智的路由决策。
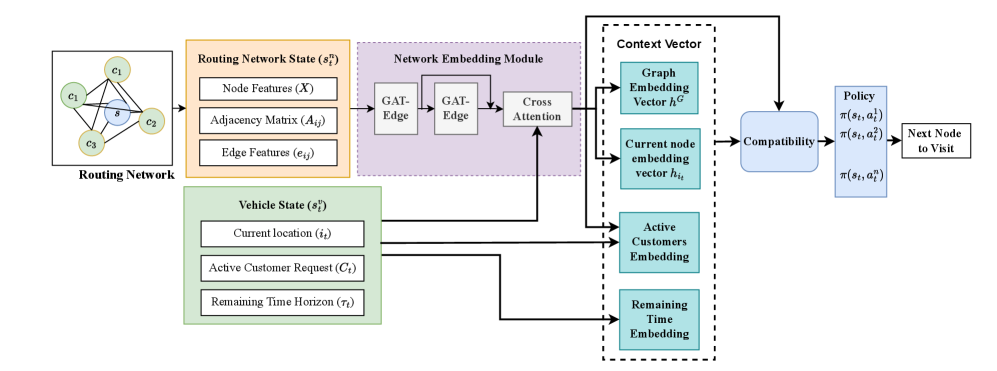
技术框架:整体框架包含以下几个主要模块:1) 路由网络嵌入模块:负责生成节点和边的嵌入表示,该模块考虑了节点特征、网络邻接矩阵、边特征以及剩余时间信息。2) 马尔可夫决策过程建模:将车辆路径问题建模为MDP,状态空间包括节点特征、网络邻接矩阵和边特征,动作空间为车辆下一步可以访问的节点,奖励函数与服务的客户数量相关。3) 基于策略梯度的深度强化学习:利用深度神经网络作为策略网络,学习最优的路由策略,目标是最大化累积奖励。
关键创新:论文的关键创新在于提出的路由网络嵌入模块,该模块能够有效地融合局部节点信息、全局图结构信息以及剩余时间信息,从而为强化学习智能体提供更具上下文感知的状态表示。与传统方法相比,该方法能够更好地捕捉车辆路径问题的动态特性和时间约束,从而提高客户服务率和缩短求解时间。
关键设计:在网络嵌入模块中,具体采用了图神经网络(GNN)来学习节点和边的嵌入表示。剩余时间信息被编码成一个时间向量,并与节点和边的特征向量进行拼接,作为GNN的输入。策略网络采用深度神经网络,损失函数为策略梯度损失,优化目标是最大化期望累积奖励。具体参数设置和网络结构细节在论文中进行了详细描述(未知)。
🖼️ 关键图片
📊 实验亮点
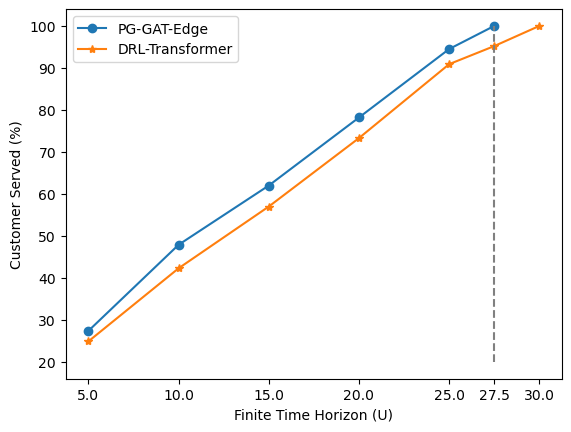
实验结果表明,该方法在真实世界的路由网络和合成生成的欧几里德网络上均取得了显著的性能提升。与现有方法相比,该方法实现了更高的客户服务率,并且解决方案时间明显更短。具体提升幅度未知,但摘要中强调了“higher”和“significantly lower”,表明提升较为显著。
🎯 应用场景
该研究成果可应用于物流配送、外卖服务、出租车调度、应急救援等领域。通过优化车辆的行驶路线,可以在有限的时间内服务更多的客户,提高服务效率,降低运营成本,并提升客户满意度。未来,该方法可以进一步扩展到更复杂的场景,例如考虑多车辆、多仓库、动态需求等因素。
📄 摘要(原文)
In this paper, we study the vehicle routing problem with a finite time horizon. In this routing problem, the objective is to maximize the number of customer requests served within a finite time horizon. We present a novel routing network embedding module which creates local node embedding vectors and a context-aware global graph representation. The proposed Markov decision process for the vehicle routing problem incorporates the node features, the network adjacency matrix and the edge features as components of the state space. We incorporate the remaining finite time horizon into the network embedding module to provide a proper routing context to the embedding module. We integrate our embedding module with a policy gradient-based deep Reinforcement Learning framework to solve the vehicle routing problem with finite time horizon. We trained and validated our proposed routing method on real-world routing networks, as well as synthetically generated Euclidean networks. Our experimental results show that our method achieves a higher customer service rate than the existing routing methods. Additionally, the solution time of our method is significantly lower than that of the existing methods.