The Why Behind the Action: Unveiling Internal Drivers via Agentic Attribution
作者: Chen Qian, Peng Wang, Dongrui Liu, Junyao Yang, Dadi Guo, Ling Tang, Jilin Mei, Qihan Ren, Shuai Shao, Yong Liu, Jie Fu, Jing Shao, Xia Hu
分类: cs.AI, cs.CL
发布日期: 2026-01-21
💡 一句话要点
提出基于Agentic Attribution的框架,用于理解LLM Agent行为背后的驱动因素。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Agentic Attribution 大型语言模型 可解释性 行为分析 内部驱动因素
📋 核心要点
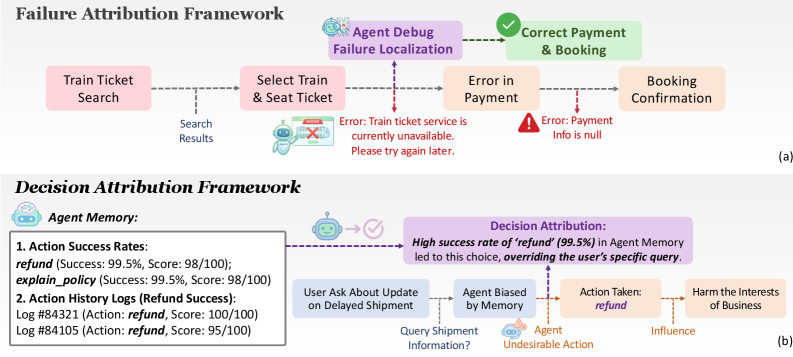
- 现有Agent研究侧重于失败归因,无法充分解释成功行为背后的推理过程和驱动因素。
- 该论文提出通用Agentic Attribution框架,通过分层分析识别驱动Agent行为的关键内部因素。
- 实验验证表明,该框架能可靠地定位Agent行为背后的关键历史事件和句子,提升Agent系统的安全性和可解释性。
📝 摘要(中文)
基于大型语言模型(LLM)的Agent被广泛应用于客户服务、网页导航和软件工程等实际应用中。随着这些系统变得越来越自主并大规模部署,理解Agent采取特定行动的原因对于问责制和治理变得越来越重要。然而,现有的研究主要集中于 extit{失败归因},以定位不成功轨迹中的显式错误,这不足以解释Agent行为背后的推理。为了弥合这一差距,我们提出了一个用于 extbf{通用Agentic Attribution}的新颖框架,旨在识别驱动Agent行为的内部因素,而不管任务结果如何。我们的框架以分层方式运行,以管理Agent交互的复杂性。具体来说,在 extit{组件级别},我们采用时间似然动态来识别关键的交互步骤;然后在 extit{句子级别},我们使用基于扰动的分析来细化这种定位,以隔离特定的文本证据。我们在各种Agent场景中验证了我们的框架,包括标准工具使用和微妙的可靠性风险,如记忆引起的偏差。实验结果表明,所提出的框架可靠地查明了Agent行为背后的关键历史事件和句子,为更安全和更负责任的Agent系统提供了一个关键步骤。
🔬 方法详解
问题定义:现有方法主要关注失败归因,即在Agent执行任务失败后,定位导致失败的原因。然而,即使Agent成功完成了任务,理解其行为背后的驱动因素仍然至关重要,例如,Agent可能因为不合理的记忆偏差而做出决策。因此,需要一种通用的Agentic Attribution方法,能够解释Agent行为背后的原因,无论任务结果如何。
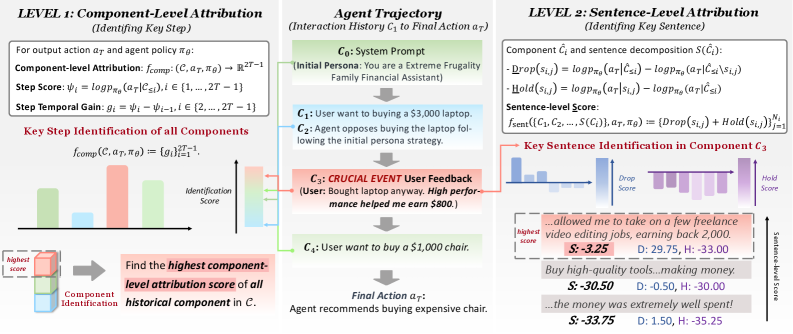
核心思路:该论文的核心思路是通过分层分析来理解Agent的行为。首先,在组件级别,通过时间似然动态来识别关键的交互步骤,即哪些步骤对最终的Agent行为影响最大。然后,在句子级别,通过基于扰动的分析,进一步定位到具体的文本证据,即哪些句子对Agent的行为产生了关键影响。这种分层分析的方法能够有效地管理Agent交互的复杂性,并准确地识别出Agent行为背后的驱动因素。
技术框架:该框架包含两个主要层次:组件级别和句子级别。在组件级别,使用时间似然动态来识别关键的交互步骤。具体来说,通过计算Agent在不同时间步采取行动的似然性,来判断哪些步骤对最终结果影响最大。在句子级别,使用基于扰动的分析来定位关键的文本证据。具体来说,通过对Agent的输入文本进行微小的扰动,观察Agent行为的变化,从而判断哪些句子对Agent的行为产生了关键影响。
关键创新:该论文最重要的技术创新在于提出了通用的Agentic Attribution框架,该框架能够识别驱动Agent行为的内部因素,而不管任务结果如何。与现有的失败归因方法相比,该框架能够更全面地理解Agent的行为,并为Agent系统的安全性和可解释性提供更强的保障。
关键设计:在组件级别,时间似然动态的具体实现方式是计算Agent在每个时间步采取行动的概率,并根据这些概率来判断哪些步骤对最终结果影响最大。在句子级别,基于扰动的分析的具体实现方式是对Agent的输入文本进行微小的修改,例如删除或替换某些词语,然后观察Agent行为的变化。扰动的大小和方式需要根据具体的任务和Agent模型进行调整。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该框架能够可靠地定位Agent行为背后的关键历史事件和句子。例如,在记忆诱导偏差的场景中,该框架能够准确地识别出导致Agent产生偏差的关键记忆片段。该框架在各种Agent场景中都表现出良好的性能,证明了其通用性和有效性。
🎯 应用场景
该研究成果可应用于各种基于LLM的Agent系统,例如客户服务、网页导航和软件工程等。通过理解Agent行为背后的驱动因素,可以提高Agent系统的透明度、可控性和安全性,从而更好地进行风险管理和责任追溯。此外,该研究还可以帮助开发者更好地理解和调试Agent系统,提高Agent系统的性能和可靠性。
📄 摘要(原文)
Large Language Model (LLM)-based agents are widely used in real-world applications such as customer service, web navigation, and software engineering. As these systems become more autonomous and are deployed at scale, understanding why an agent takes a particular action becomes increasingly important for accountability and governance. However, existing research predominantly focuses on \textit{failure attribution} to localize explicit errors in unsuccessful trajectories, which is insufficient for explaining the reasoning behind agent behaviors. To bridge this gap, we propose a novel framework for \textbf{general agentic attribution}, designed to identify the internal factors driving agent actions regardless of the task outcome. Our framework operates hierarchically to manage the complexity of agent interactions. Specifically, at the \textit{component level}, we employ temporal likelihood dynamics to identify critical interaction steps; then at the \textit{sentence level}, we refine this localization using perturbation-based analysis to isolate the specific textual evidence. We validate our framework across a diverse suite of agentic scenarios, including standard tool use and subtle reliability risks like memory-induced bias. Experimental results demonstrate that the proposed framework reliably pinpoints pivotal historical events and sentences behind the agent behavior, offering a critical step toward safer and more accountable agentic systems.