Proximal Policy Optimization with Evolutionary Mutations
作者: Casimir Czworkowski, Stephen Hornish, Alhassan S. Yasin
分类: cs.NE, cs.AI, cs.GT, cs.LG
发布日期: 2026-01-21
备注: 10 pages, 5 figures, 2 tables, 1 algorithm
💡 一句话要点
提出POEM算法,通过进化变异增强PPO探索能力,解决强化学习早熟收敛问题。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 近端策略优化 强化学习 进化算法 探索-利用平衡 策略变异
📋 核心要点
- PPO算法虽然稳定高效,但探索能力不足,容易陷入局部最优,导致早熟收敛。
- POEM算法借鉴进化算法思想,通过监控策略变化,自适应地对策略参数进行变异,促进探索。
- 实验表明,POEM在多个OpenAI Gym环境中显著优于PPO,验证了其在探索-利用平衡方面的有效性。
📝 摘要(中文)
近端策略优化(PPO)是一种广泛使用的强化学习算法,以其稳定性和样本效率而闻名,但由于探索有限,它经常遭受早熟收敛的困扰。本文提出了一种新的PPO改进算法POEM(具有进化变异的近端策略优化),它引入了一种受进化算法启发的自适应探索机制。POEM通过监控当前策略与先前策略的移动平均之间的Kullback-Leibler(KL)散度来增强策略多样性。当策略变化变得极小时,表明停滞,POEM会触发策略参数的自适应变异以促进探索。我们在四个OpenAI Gym环境(CarRacing、MountainCar、BipedalWalker和LunarLander)上评估了POEM。通过使用贝叶斯优化技术进行广泛的微调,并使用Welch's t检验进行统计测试,我们发现POEM在四个任务中的三个上明显优于PPO(BipedalWalker:t=-2.0642,p=0.0495;CarRacing:t=-6.3987,p=0.0002;MountainCar:t=-6.2431,p<0.0001),而LunarLander上的性能没有统计学意义(t=-1.8707,p=0.0778)。我们的结果突出了将进化原则整合到策略梯度方法中以克服探索-利用权衡的潜力。
🔬 方法详解
问题定义:PPO算法在强化学习中应用广泛,但其探索能力有限,容易过早收敛到次优策略。尤其在高维、复杂的环境中,缺乏有效的探索机制会导致算法无法找到全局最优解,影响最终性能。因此,如何提升PPO的探索能力,避免早熟收敛是一个重要的研究问题。
核心思路:POEM的核心思路是借鉴进化算法中的变异思想,在PPO的基础上引入自适应的策略变异机制。通过监控策略的变化情况(KL散度),判断算法是否陷入停滞。一旦检测到停滞,就对策略参数进行变异,从而跳出局部最优,探索更广阔的策略空间。这种自适应变异能够有效地平衡探索和利用,提升算法的整体性能。
技术框架:POEM的整体框架与PPO类似,主要包括以下几个阶段:1) 使用当前策略与环境交互,收集经验数据;2) 计算优势函数,评估动作的优劣;3) 使用近端策略优化目标函数更新策略;4) 监控当前策略与历史策略的KL散度,判断是否需要进行变异;5) 如果需要变异,则对策略参数进行自适应的变异。
关键创新:POEM的关键创新在于引入了自适应的策略变异机制。与传统的探索方法(如ε-greedy、高斯噪声)相比,POEM的变异是基于策略变化情况的,能够更有效地促进探索。此外,POEM的变异幅度是自适应调整的,可以根据环境的复杂程度和算法的收敛情况进行调整,从而更好地平衡探索和利用。
关键设计:POEM的关键设计包括:1) 使用KL散度来衡量策略的变化情况,作为触发变异的依据;2) 使用贝叶斯优化技术来微调变异的参数,以获得最佳的性能;3) 变异的方式可以采用多种形式,例如添加高斯噪声、随机扰动等。论文中具体使用的变异方式未知。
🖼️ 关键图片
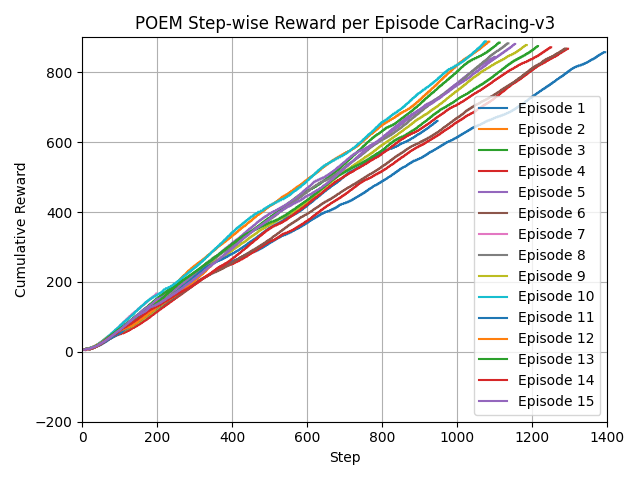
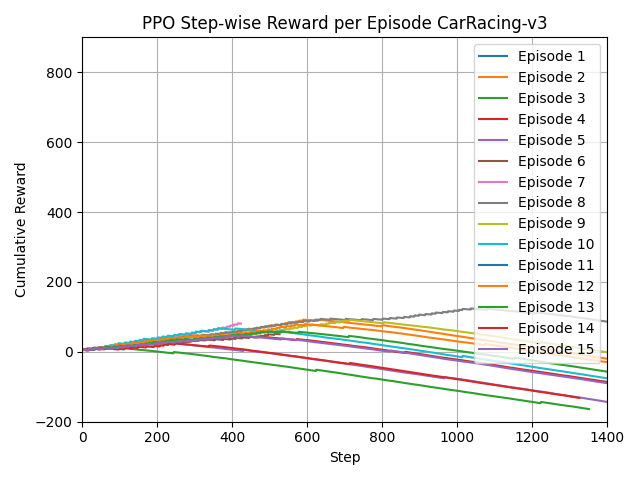
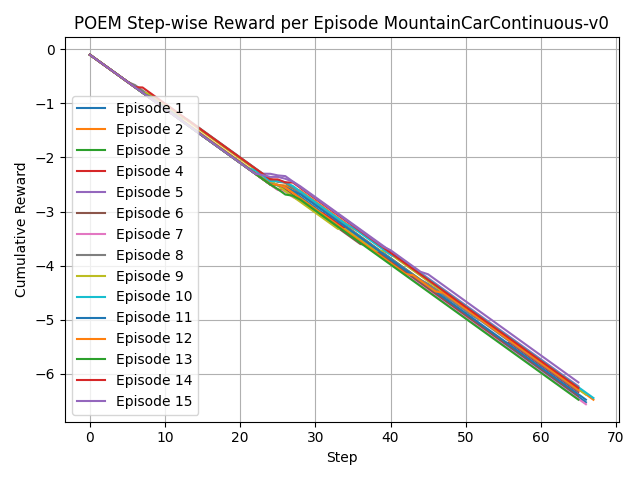
📊 实验亮点
实验结果表明,POEM在BipedalWalker、CarRacing和MountainCar三个OpenAI Gym环境中显著优于PPO。例如,在CarRacing环境中,POEM的性能提升显著(t=-6.3987,p=0.0002)。虽然在LunarLander环境中性能提升不显著,但总体而言,POEM的性能表现优于PPO,验证了其有效性。
🎯 应用场景
POEM算法可以应用于各种需要强化学习的场景,尤其是在环境复杂、奖励稀疏的情况下,例如机器人控制、游戏AI、自动驾驶等。通过增强探索能力,POEM可以帮助智能体更快地学习到最优策略,提高任务完成的效率和质量。该研究对于提升强化学习算法的鲁棒性和泛化能力具有重要意义。
📄 摘要(原文)
Proximal Policy Optimization (PPO) is a widely used reinforcement learning algorithm known for its stability and sample efficiency, but it often suffers from premature convergence due to limited exploration. In this paper, we propose POEM (Proximal Policy Optimization with Evolutionary Mutations), a novel modification to PPO that introduces an adaptive exploration mechanism inspired by evolutionary algorithms. POEM enhances policy diversity by monitoring the Kullback-Leibler (KL) divergence between the current policy and a moving average of previous policies. When policy changes become minimal, indicating stagnation, POEM triggers an adaptive mutation of policy parameters to promote exploration. We evaluate POEM on four OpenAI Gym environments: CarRacing, MountainCar, BipedalWalker, and LunarLander. Through extensive fine-tuning using Bayesian optimization techniques and statistical testing using Welch's t-test, we find that POEM significantly outperforms PPO on three of the four tasks (BipedalWalker: t=-2.0642, p=0.0495; CarRacing: t=-6.3987, p=0.0002; MountainCar: t=-6.2431, p<0.0001), while performance on LunarLander is not statistically significant (t=-1.8707, p=0.0778). Our results highlight the potential of integrating evolutionary principles into policy gradient methods to overcome exploration-exploitation tradeoffs.