When Text-as-Vision Meets Semantic IDs in Generative Recommendation: An Empirical Study
作者: Shutong Qiao, Wei Yuan, Tong Chen, Xiangyu Zhao, Quoc Viet Hung Nguyen, Hongzhi Yin
分类: cs.IR, cs.AI
发布日期: 2026-01-21
💡 一句话要点
提出基于OCR的文本表示方法,提升生成式推荐中语义ID学习效果
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 生成式推荐 语义ID学习 OCR 文本表示 多模态融合 视觉文本 推荐系统
📋 核心要点
- 现有文本编码器在处理推荐系统中常见的符号化、属性化物品描述时,存在语义连贯性弱和属性关系扭曲的问题。
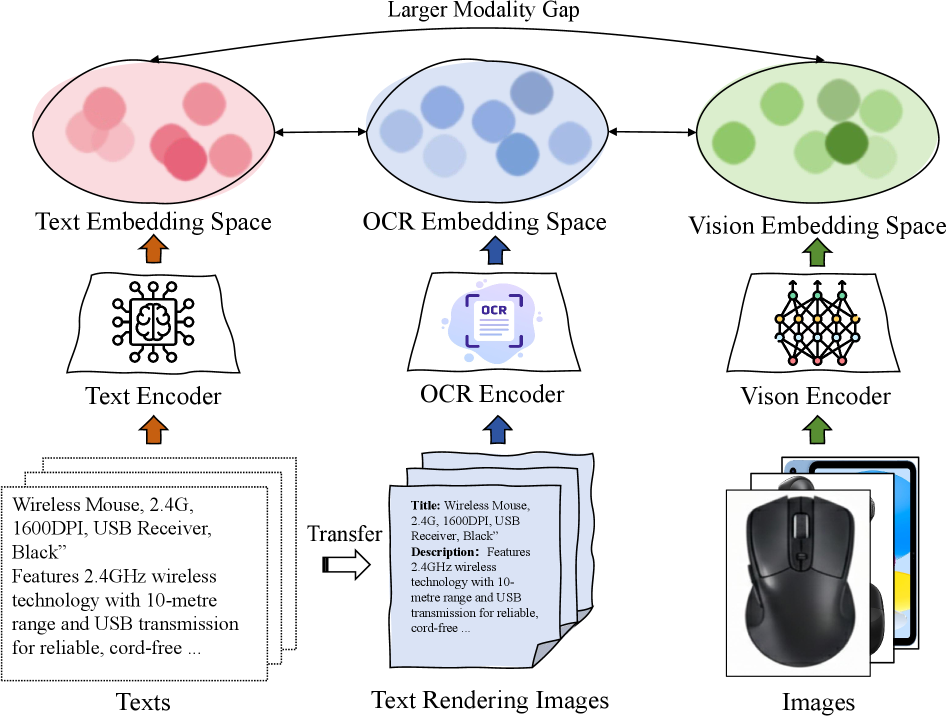
- 论文核心思想是将文本视为视觉信号,利用OCR技术将物品描述渲染成图像,再用视觉模型进行编码,学习语义ID。
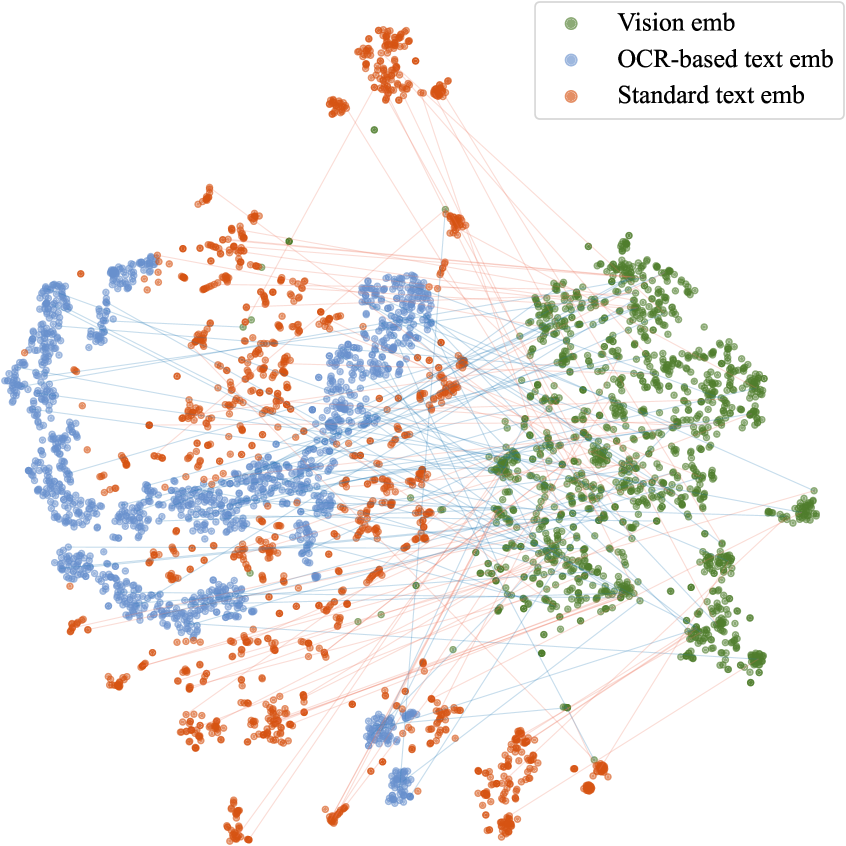
- 实验结果表明,基于OCR的文本表示在单模态和多模态生成式推荐中,性能优于标准文本嵌入,且具有良好的鲁棒性。
📝 摘要(中文)
语义ID学习是生成式推荐(GR)模型中的关键接口,它将物品映射到基于辅助信息的离散标识符,通常通过预训练的文本编码器实现。然而,这些文本编码器主要针对结构良好的自然语言进行优化。在实际推荐数据中,物品描述通常是符号化和以属性为中心的,包含数字、单位和缩写。这些文本编码器可能会将这些信号分解为碎片化的token,削弱语义连贯性并扭曲属性之间的关系。更糟糕的是,在多模态GR中,依赖标准文本编码器会引入额外的障碍:文本和图像嵌入通常表现出不匹配的几何结构,使得跨模态融合的效果降低且不稳定。本文重新审视了语义ID学习的表示设计,将文本视为视觉信号。我们对基于OCR的文本表示进行了系统的实证研究,通过将物品描述渲染成图像并使用基于视觉的OCR模型对其进行编码。在四个数据集和两个生成式骨干网络上的实验表明,在单模态和多模态设置中,对于语义ID学习,基于OCR的文本始终与标准文本嵌入相匹配或超过标准文本嵌入。此外,我们发现基于OCR的语义ID在极端的空间分辨率压缩下仍然保持稳健,表明在实际部署中具有很强的鲁棒性和效率。
🔬 方法详解
问题定义:论文旨在解决生成式推荐模型中,使用预训练文本编码器学习语义ID时,由于物品描述的特殊性(符号化、属性化),导致语义信息损失和跨模态融合困难的问题。现有方法直接使用预训练的文本编码器,但这些编码器针对自然语言优化,无法有效处理推荐场景下的物品描述,造成信息碎片化和模态不匹配。
核心思路:论文的核心思路是将物品描述视为视觉信号,利用OCR技术将文本渲染成图像,然后使用视觉模型进行编码。这种方法能够更好地保留物品描述中的结构信息和属性关系,同时缓解文本和图像模态之间的差异,从而提升语义ID学习的效果。
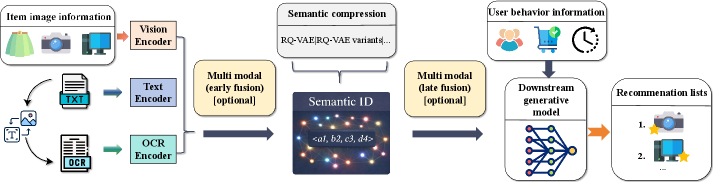
技术框架:整体框架包含以下几个主要步骤:1) 将物品描述文本渲染成图像;2) 使用OCR模型(例如,Vision Transformer)对图像进行编码,提取视觉特征;3) 将提取的视觉特征作为语义ID,用于生成式推荐模型的训练和推理。该框架可以应用于单模态和多模态生成式推荐模型中,替换原有的文本编码器。
关键创新:最重要的技术创新点在于将文本视为视觉信号,并利用OCR技术进行编码。这种方法避免了直接使用预训练文本编码器处理非自然语言文本,从而更好地保留了物品描述中的语义信息。与现有方法相比,该方法更适合处理推荐场景下的物品描述,并且能够有效缓解跨模态融合的问题。
关键设计:论文中使用了Vision Transformer作为OCR模型,用于提取图像特征。在实验中,研究者探索了不同的空间分辨率,并发现即使在极端的空间分辨率压缩下,基于OCR的语义ID仍然保持稳健。此外,论文还使用了标准的生成式推荐模型作为骨干网络,并将其与基于OCR的语义ID学习方法相结合,验证了该方法的有效性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在四个数据集和两个生成式骨干网络上,基于OCR的文本表示在语义ID学习方面始终与标准文本嵌入相匹配或超过标准文本嵌入。尤其是在多模态推荐中,基于OCR的方法能够显著提升推荐性能。此外,研究发现基于OCR的语义ID在极端的空间分辨率压缩下仍然保持稳健,表明其在实际部署中具有很强的鲁棒性和效率。
🎯 应用场景
该研究成果可广泛应用于电商、社交媒体、内容推荐等领域,提升推荐系统的准确性和用户体验。通过更有效地利用物品描述信息,可以更好地理解用户偏好,从而提供更个性化的推荐服务。此外,该方法在多模态推荐中具有重要价值,可以促进文本和图像信息的有效融合,提升推荐效果。
📄 摘要(原文)
Semantic ID learning is a key interface in Generative Recommendation (GR) models, mapping items to discrete identifiers grounded in side information, most commonly via a pretrained text encoder. However, these text encoders are primarily optimized for well-formed natural language. In real-world recommendation data, item descriptions are often symbolic and attribute-centric, containing numerals, units, and abbreviations. These text encoders can break these signals into fragmented tokens, weakening semantic coherence and distorting relationships among attributes. Worse still, when moving to multimodal GR, relying on standard text encoders introduces an additional obstacle: text and image embeddings often exhibit mismatched geometric structures, making cross-modal fusion less effective and less stable. In this paper, we revisit representation design for Semantic ID learning by treating text as a visual signal. We conduct a systematic empirical study of OCR-based text representations, obtained by rendering item descriptions into images and encoding them with vision-based OCR models. Experiments across four datasets and two generative backbones show that OCR-text consistently matches or surpasses standard text embeddings for Semantic ID learning in both unimodal and multimodal settings. Furthermore, we find that OCR-based Semantic IDs remain robust under extreme spatial-resolution compression, indicating strong robustness and efficiency in practical deployments.