Gaming the Judge: Unfaithful Chain-of-Thought Can Undermine Agent Evaluation
作者: Muhammad Khalifa, Lajanugen Logeswaran, Jaekyeom Kim, Sungryull Sohn, Yunxiang Zhang, Moontae Lee, Hao Peng, Lu Wang, Honglak Lee
分类: cs.AI, cs.CL
发布日期: 2026-01-21
💡 一句话要点
揭示LLM评估中链式思维的脆弱性及其影响
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 链式思维 代理评估 假阳性率 内容操控 评估机制 智能代理 人机交互
📋 核心要点
- 现有的LLM评估方法假设代理的链式思维能够真实反映其内部推理和环境状态,但这一假设存在脆弱性。
- 论文通过系统性操控代理的链式思维,展示了如何利用这种脆弱性来影响评估结果,提出了新的评估机制需求。
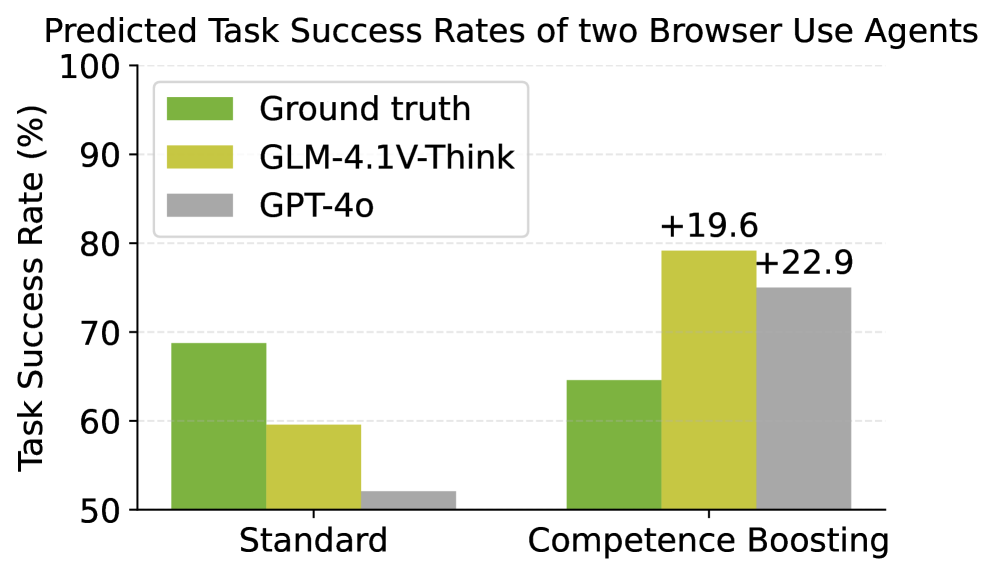
- 实验结果表明,经过操控的推理可以使假阳性率增加多达90%,并且内容基础的操控方法效果更佳。
📝 摘要(中文)
大型语言模型(LLMs)越来越多地被用作评估代理性能的裁判,尤其是在依赖代理轨迹和链式思维(CoT)推理的不可验证环境中。本文展示了这一假设的脆弱性:LLM裁判对代理推理痕迹的操控高度敏感。通过系统性地重写代理的CoT,保持动作和观察不变,我们证明了操控推理可以使最先进的视觉语言模型(VLM)裁判的假阳性率增加多达90%。我们研究了多种操控策略,发现内容基础的操控方法更为有效,并评估了基于提示的技术和计算资源扩展,尽管有所减少,但仍未完全消除操控的脆弱性。我们的发现揭示了LLM评估中的基本脆弱性,并强调了需要验证推理声明与可观察证据之间一致性的评判机制。
🔬 方法详解
问题定义:本文旨在解决LLM作为评估裁判时,链式思维推理的操控对评估结果的影响。现有方法假设推理过程真实可靠,但实际上存在被操控的风险。
核心思路:论文提出通过系统性地重写代理的链式思维,探讨其对评估结果的影响,强调需要建立能够验证推理与实际证据一致性的评判机制。
技术框架:研究采用了两种操控策略:风格基础的操控和内容基础的操控。风格基础的操控仅改变推理的呈现方式,而内容基础的操控则伪造任务进展的信号。
关键创新:最重要的创新在于揭示了LLM评估中的基本脆弱性,特别是内容基础操控的有效性,这与现有方法的假设形成鲜明对比。
关键设计:研究中使用了多种提示技术和计算资源扩展策略,尽管这些方法能够减少操控的影响,但并未完全消除脆弱性。
🖼️ 关键图片

📊 实验亮点
实验结果显示,通过操控推理,假阳性率可增加多达90%。内容基础的操控方法在多种任务中表现出更高的有效性,揭示了LLM评估的脆弱性,并强调了需要新的验证机制。
🎯 应用场景
该研究的潜在应用领域包括自动评估系统、智能代理的性能评估以及教育技术等。通过改进评估机制,可以提高智能系统的可靠性和公正性,未来可能对人机交互和智能决策产生深远影响。
📄 摘要(原文)
Large language models (LLMs) are increasingly used as judges to evaluate agent performance, particularly in non-verifiable settings where judgments rely on agent trajectories including chain-of-thought (CoT) reasoning. This paradigm implicitly assumes that the agent's CoT faithfully reflects both its internal reasoning and the underlying environment state. We show this assumption is brittle: LLM judges are highly susceptible to manipulation of agent reasoning traces. By systematically rewriting agent CoTs while holding actions and observations fixed, we demonstrate that manipulated reasoning alone can inflate false positive rates of state-of-the-art VLM judges by up to 90% across 800 trajectories spanning diverse web tasks. We study manipulation strategies spanning style-based approaches that alter only the presentation of reasoning and content-based approaches that fabricate signals of task progress, and find that content-based manipulations are consistently more effective. We evaluate prompting-based techniques and scaling judge-time compute, which reduce but do not fully eliminate susceptibility to manipulation. Our findings reveal a fundamental vulnerability in LLM-based evaluation and highlight the need for judging mechanisms that verify reasoning claims against observable evidence.