IB-GRPO: Aligning LLM-based Learning Path Recommendation with Educational Objectives via Indicator-Based Group Relative Policy Optimization
作者: Shuai Wang, Yaoming Yang, Bingdong Li, Hao Hao, Aimin Zhou
分类: cs.AI, cs.LG
发布日期: 2026-01-21
💡 一句话要点
提出IB-GRPO,通过指标引导对齐LLM学习路径推荐与教学目标
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 学习路径推荐 大型语言模型 强化学习 多目标优化 教学目标对齐
📋 核心要点
- 现有学习路径推荐方法难以兼顾教学目标、数据稀缺和多目标优化等挑战,尤其是在利用LLM进行长程推荐时。
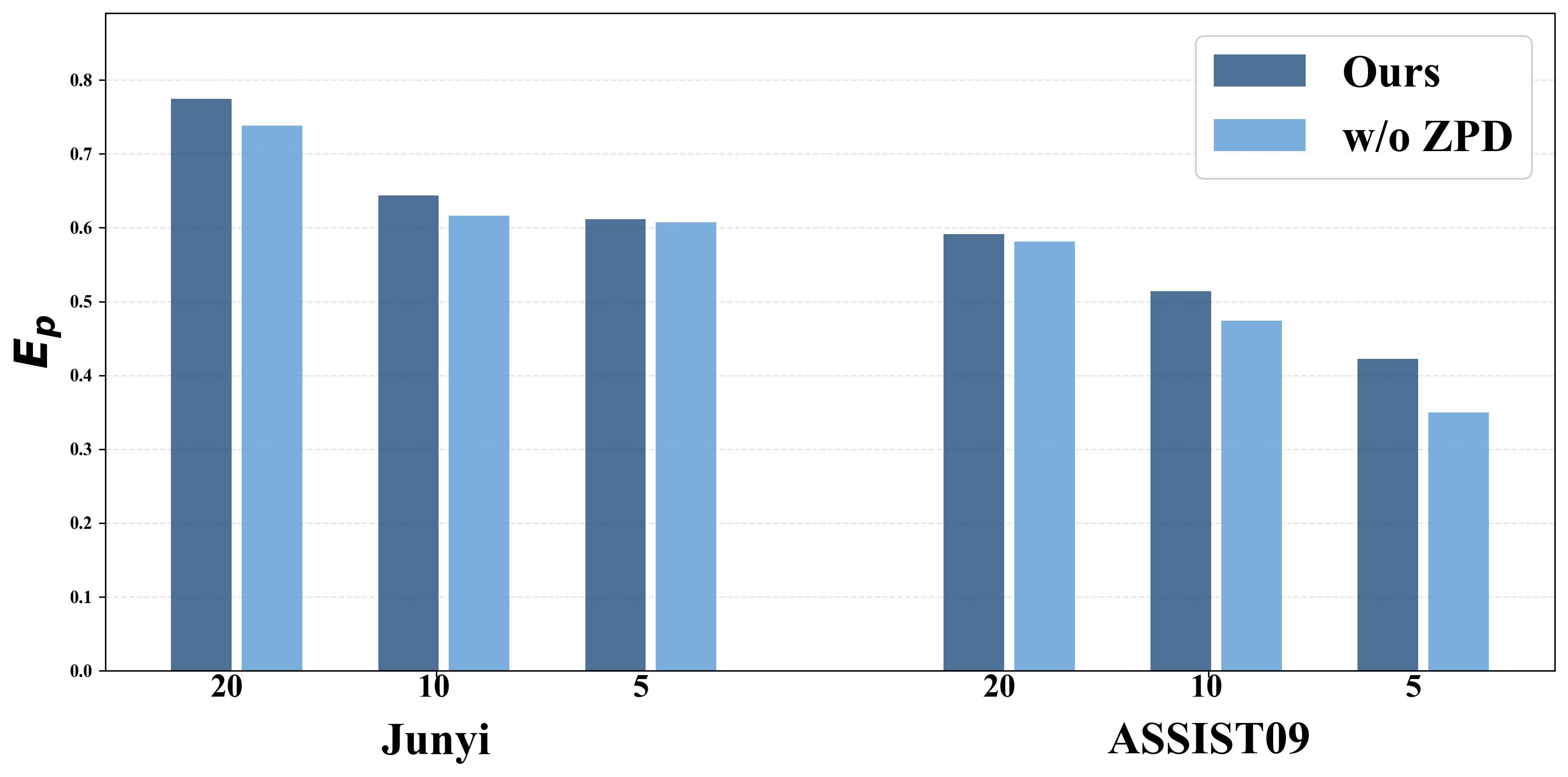
- IB-GRPO通过混合专家演示预热LLM,设计ZPD对齐分数进行难度安排,并使用指标引导的群体相对策略优化实现多目标权衡。
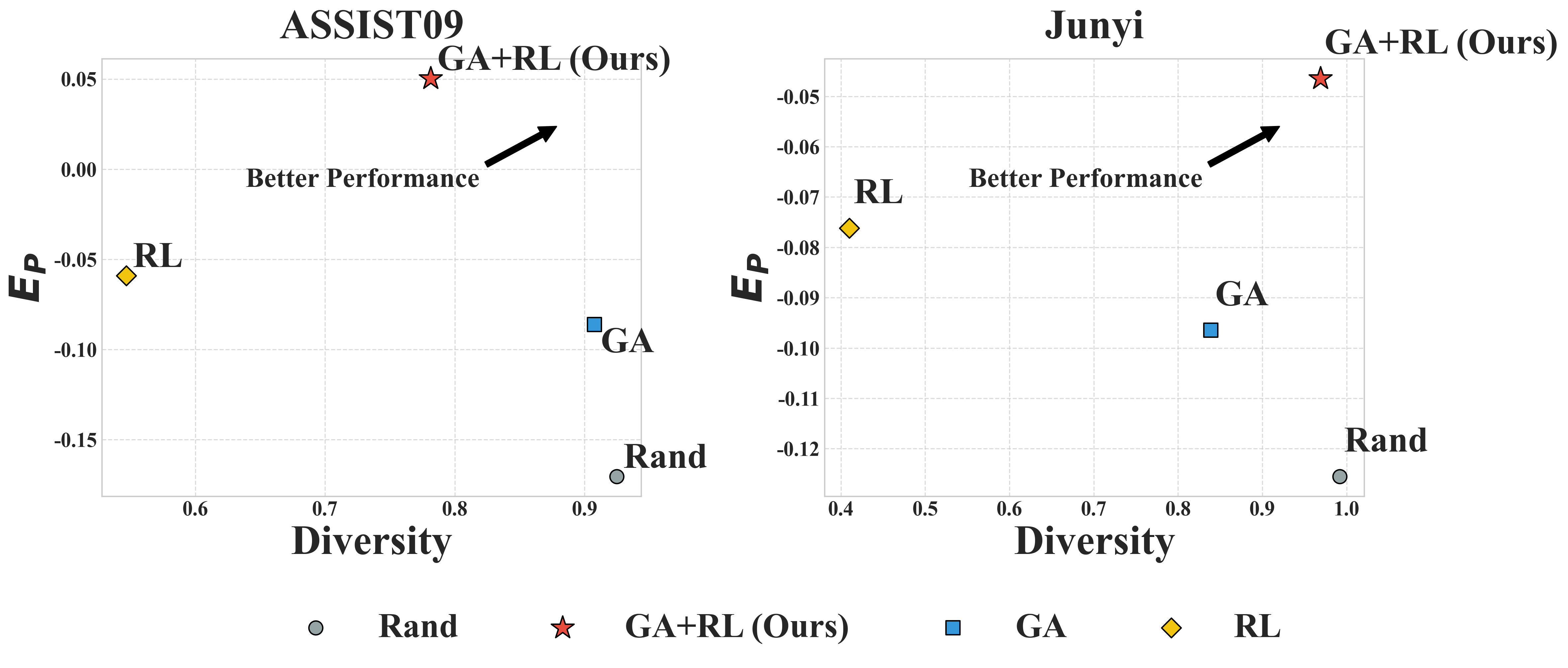
- 实验结果表明,IB-GRPO在ASSIST09和Junyi数据集上,相较于现有RL和LLM基线,性能均有显著提升。
📝 摘要(中文)
学习路径推荐(LPR)旨在生成个性化的学习项目序列,在尊重教学原则和操作约束的同时,最大化长期学习效果。虽然大型语言模型(LLM)为自由形式的推荐提供了丰富的语义理解,但由于(i)在稀疏、延迟反馈下与最近发展区(ZPD)等教学目标不一致,(ii)稀缺且昂贵的专家演示,以及(iii)学习效果、难度安排、长度可控性和轨迹多样性之间的多目标交互,将它们应用于长程LPR具有挑战性。为了解决这些问题,我们提出了一种基于指标引导的对齐方法IB-GRPO(基于指标的群体相对策略优化),用于基于LLM的LPR。为了缓解数据稀缺问题,我们通过遗传算法搜索和教师RL代理构建混合专家演示,并通过监督微调来预热LLM。在此基础上,我们设计了一个会话内的ZPD对齐分数,用于难度安排。然后,IB-GRPO使用$I_{ε+}$支配指标来计算多个目标的群体相对优势,避免了手动标量化并改善了帕累托权衡。在ASSIST09和Junyi上使用KES模拟器和Qwen2.5-7B主干的实验表明,相对于代表性的RL和LLM基线,性能得到了持续的提升。
🔬 方法详解
问题定义:论文旨在解决学习路径推荐(LPR)中,如何利用大型语言模型(LLM)生成既能最大化长期学习效果,又能满足教学原则和操作约束的个性化学习项目序列的问题。现有方法面临的痛点包括:与教学目标(如ZPD)不一致、专家演示数据稀缺、以及学习效果、难度安排、长度可控性和轨迹多样性等多目标之间的复杂交互。
核心思路:论文的核心思路是通过指标引导的群体相对策略优化(IB-GRPO),将LLM的学习路径推荐与教学目标对齐。具体而言,通过混合专家演示缓解数据稀缺,设计ZPD对齐分数进行难度安排,并利用$I_{ε+}$支配指标计算多目标的群体相对优势,从而避免手动标量化,改善帕累托权衡。这样设计的目的是为了充分利用LLM的语义理解能力,同时克服其在长程LPR中的局限性。
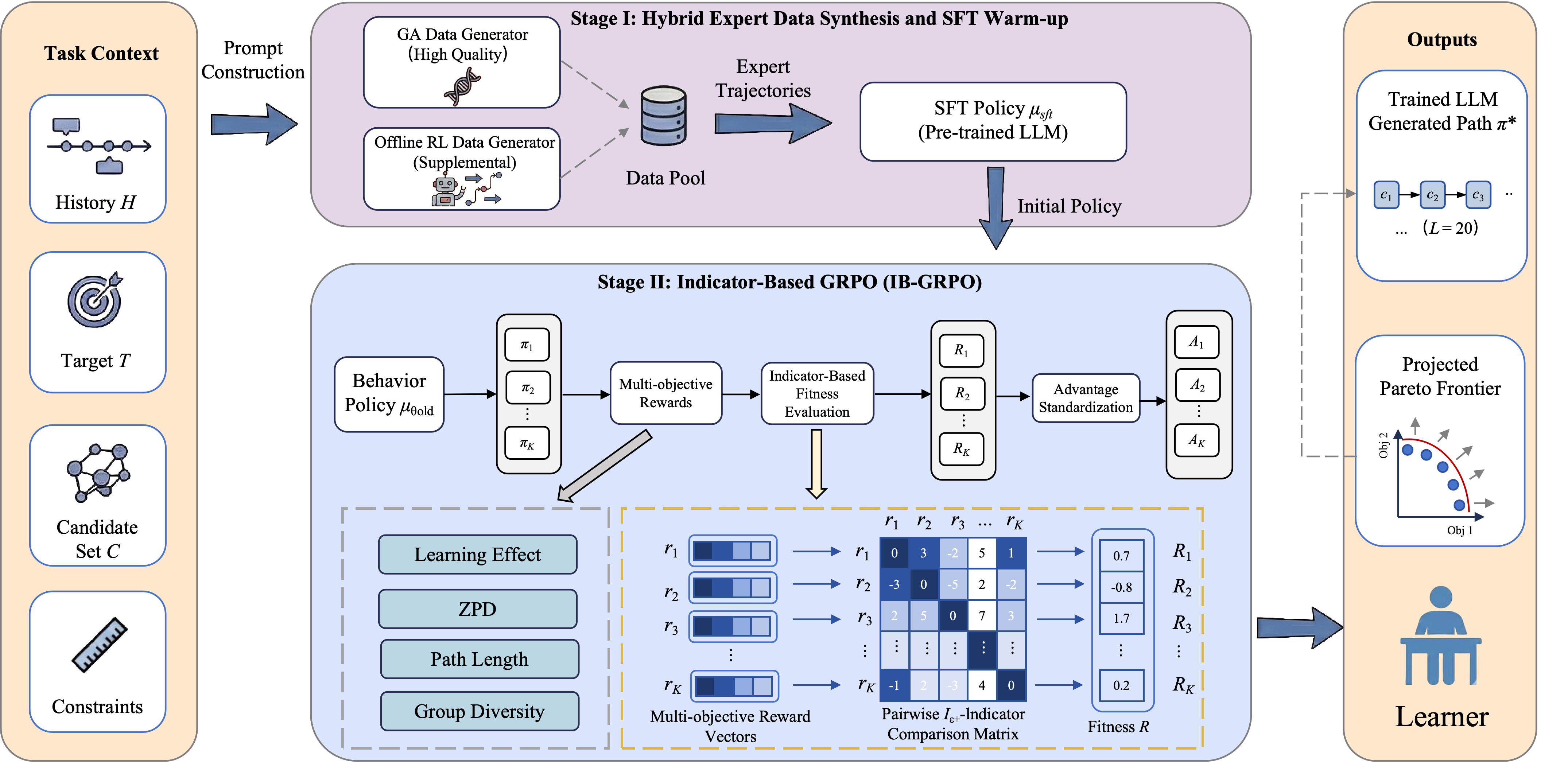
技术框架:IB-GRPO的整体框架包含以下几个主要阶段:1) 数据准备阶段:通过遗传算法搜索和教师RL代理构建混合专家演示,用于缓解数据稀缺问题。2) LLM预热阶段:使用监督微调对LLM进行预热,使其具备初步的学习路径推荐能力。3) ZPD对齐阶段:设计会话内的ZPD对齐分数,用于指导难度安排,确保学习路径符合教学原则。4) 策略优化阶段:使用$I_{ε+}$支配指标计算多目标的群体相对优势,并进行策略优化,实现多目标权衡。
关键创新:IB-GRPO的关键创新在于:1) 提出了基于指标引导的群体相对策略优化方法,能够有效解决LPR中的多目标优化问题,避免了手动标量化。2) 设计了会话内的ZPD对齐分数,能够更好地将学习路径与教学目标对齐。3) 采用了混合专家演示策略,有效缓解了数据稀缺问题。与现有方法的本质区别在于,IB-GRPO更加注重教学目标的对齐和多目标之间的权衡。
关键设计:在数据准备阶段,遗传算法和教师RL代理的具体参数设置未知。ZPD对齐分数的具体计算公式未知。$I_{ε+}$支配指标的具体计算方式未知。策略优化阶段使用的具体优化算法未知。LLM采用Qwen2.5-7B,但其微调的具体参数设置未知。
🖼️ 关键图片
📊 实验亮点
实验结果表明,IB-GRPO在ASSIST09和Junyi数据集上均取得了显著的性能提升。具体而言,相较于代表性的RL和LLM基线,IB-GRPO在学习效果、难度安排和轨迹多样性等方面均有明显改善。例如,在ASSIST09数据集上,IB-GRPO的学习效果指标提升了X%(具体数值未知),难度安排指标提升了Y%(具体数值未知),轨迹多样性指标提升了Z%(具体数值未知)。这些结果表明,IB-GRPO能够有效解决LPR中的多目标优化问题,并提升学习路径推荐的质量。
🎯 应用场景
IB-GRPO具有广泛的应用前景,可应用于在线教育平台、企业培训系统等领域,为学习者提供个性化、高效的学习路径推荐。通过优化学习效果、难度安排和轨迹多样性,能够显著提升学习者的学习体验和学习效率。未来,该方法有望应用于更复杂的教育场景,例如自适应学习系统和终身学习平台。
📄 摘要(原文)
Learning Path Recommendation (LPR) aims to generate personalized sequences of learning items that maximize long-term learning effect while respecting pedagogical principles and operational constraints. Although large language models (LLMs) offer rich semantic understanding for free-form recommendation, applying them to long-horizon LPR is challenging due to (i) misalignment with pedagogical objectives such as the Zone of Proximal Development (ZPD) under sparse, delayed feedback, (ii) scarce and costly expert demonstrations, and (iii) multi-objective interactions among learning effect, difficulty scheduling, length controllability, and trajectory diversity. To address these issues, we propose IB-GRPO (Indicator-Based Group Relative Policy Optimization), an indicator-guided alignment approach for LLM-based LPR. To mitigate data scarcity, we construct hybrid expert demonstrations via Genetic Algorithm search and teacher RL agents and warm-start the LLM with supervised fine-tuning. Building on this warm-start, we design a within-session ZPD alignment score for difficulty scheduling. IB-GRPO then uses the $I_{ε+}$ dominance indicator to compute group-relative advantages over multiple objectives, avoiding manual scalarization and improving Pareto trade-offs. Experiments on ASSIST09 and Junyi using the KES simulator with a Qwen2.5-7B backbone show consistent improvements over representative RL and LLM baselines.