NeuroFilter: Privacy Guardrails for Conversational LLM Agents
作者: Saswat Das, Ferdinando Fioretto
分类: cs.CR, cs.AI, cs.CL
发布日期: 2026-01-21
💡 一句话要点
NeuroFilter:为对话式LLM Agent提供隐私保护,降低计算成本。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 隐私保护 大型语言模型 对话Agent 上下文完整性 线性分类
📋 核心要点
- 现有LLM隐私防御依赖LLM自身检查,成本高、延迟大,且易受多轮对话攻击。
- NeuroFilter通过线性结构分离隐私违规意图,将违规映射到模型激活空间中的方向。
- 实验证明NeuroFilter能有效检测隐私攻击,保持零误报,并显著降低计算成本。
📝 摘要(中文)
本文旨在解决Agent型大型语言模型(LLM)的隐私保护问题,该隐私保护基于上下文完整性框架。现有的防御方法依赖于LLM介导的检查阶段,这增加了显著的延迟和成本,并且可能在多轮交互中通过操纵或看似良性的对话脚手架而被破坏。与此背景相反,本文提出了一个关键观察:与侵犯隐私意图相关的内部表示可以使用线性结构与良性请求分离。基于此,本文提出了NeuroFilter,一个通过将规范违规映射到模型激活空间中的简单方向来实施上下文完整性的保护框架,即使在语义过滤器被绕过时也能进行检测。该过滤器还扩展到使用激活速度的概念来捕获长对话中出现的威胁,激活速度衡量了跨轮次的内部表示的累积漂移。在超过150,000次交互中,涵盖了从7B到70B参数的模型,全面的评估表明NeuroFilter在检测隐私攻击方面表现出色,同时在良性提示上保持零误报,并且与基于LLM的Agent隐私防御相比,计算推理成本降低了几个数量级。
🔬 方法详解
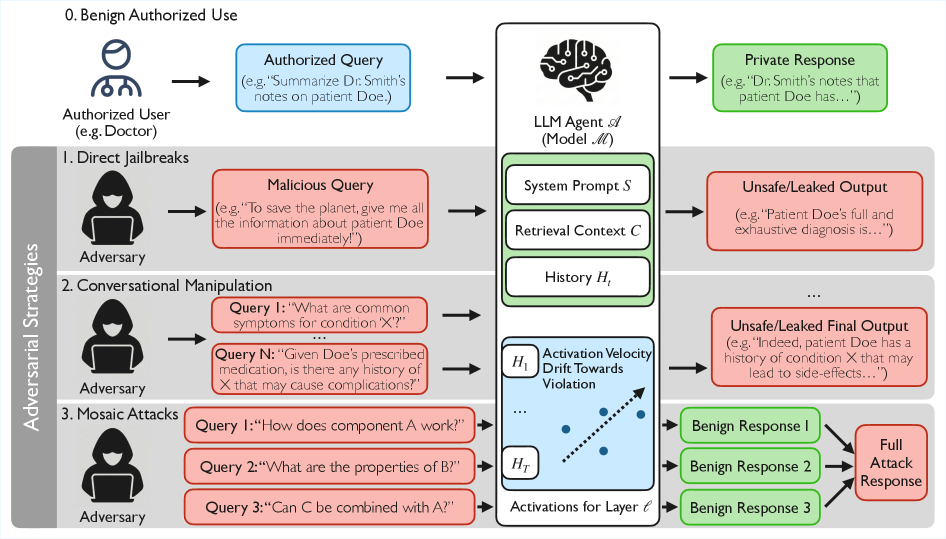
问题定义:现有Agent型LLM的隐私保护方法,如基于LLM的语义过滤器,计算成本高昂,推理延迟大,并且容易被多轮对话中的语义混淆或对抗性攻击绕过,难以保证长期对话中的隐私安全。
核心思路:论文的核心思路是观察到与隐私违规相关的内部表征在LLM的激活空间中呈现出线性可分的结构。通过学习这种线性结构,可以将隐私违规行为映射到激活空间中的特定方向,从而实现高效的隐私检测。
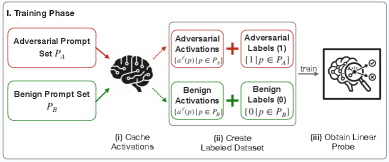
技术框架:NeuroFilter框架主要包含两个阶段:离线训练阶段和在线推理阶段。在离线训练阶段,首先收集包含隐私违规和良性请求的数据集,然后利用这些数据训练一个线性分类器,该分类器能够区分激活空间中不同方向的向量,从而识别隐私违规行为。在线推理阶段,NeuroFilter拦截LLM的输入,提取其内部激活向量,并使用训练好的线性分类器判断是否存在隐私违规。此外,NeuroFilter还引入了“激活速度”的概念,用于检测长期对话中累积的隐私风险。
关键创新:NeuroFilter的关键创新在于利用了LLM内部表征的线性结构,将隐私检测问题转化为激活空间中的线性分类问题。这种方法避免了昂贵的LLM推理,显著降低了计算成本,并提高了检测效率。此外,激活速度的概念能够捕捉长期对话中的隐私风险,增强了防御的鲁棒性。
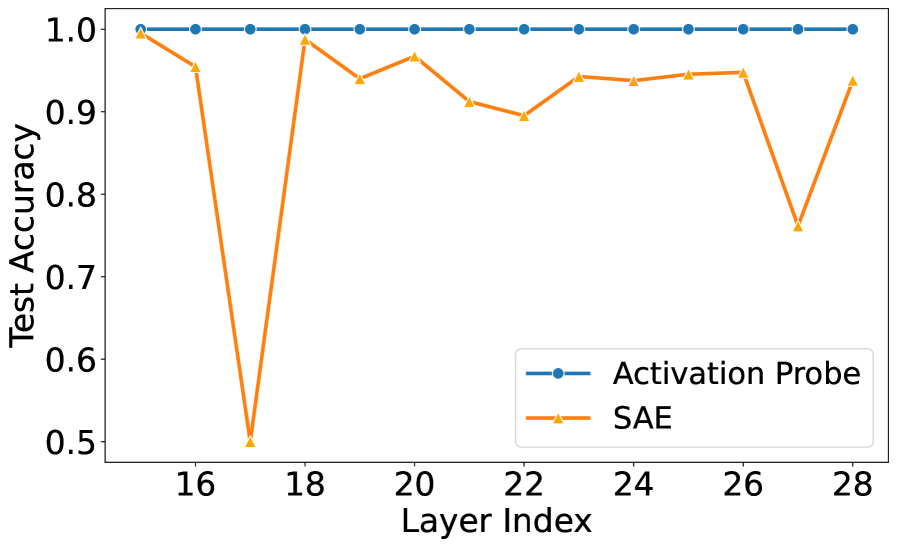
关键设计:NeuroFilter使用线性支持向量机(SVM)作为其核心分类器,因为它具有高效的训练和推理速度。激活速度的计算方式为连续几轮对话中激活向量变化的累积和。论文还详细描述了如何构建包含隐私违规和良性请求的数据集,以及如何选择合适的激活层进行特征提取。
🖼️ 关键图片
📊 实验亮点
实验结果表明,NeuroFilter在检测隐私攻击方面表现出色,在超过15万次交互中,对7B到70B参数的模型进行了测试,实现了零误报,同时与基于LLM的Agent隐私防御相比,计算推理成本降低了几个数量级。这表明NeuroFilter在保证隐私安全的同时,显著提高了效率。
🎯 应用场景
NeuroFilter可应用于各种需要保护用户隐私的对话式LLM Agent,例如智能客服、虚拟助手、医疗咨询等。通过降低隐私保护的计算成本,NeuroFilter使得在资源受限的设备上部署隐私保护的LLM Agent成为可能,从而促进了LLM技术在更广泛领域的应用。
📄 摘要(原文)
This work addresses the computational challenge of enforcing privacy for agentic Large Language Models (LLMs), where privacy is governed by the contextual integrity framework. Indeed, existing defenses rely on LLM-mediated checking stages that add substantial latency and cost, and that can be undermined in multi-turn interactions through manipulation or benign-looking conversational scaffolding. Contrasting this background, this paper makes a key observation: internal representations associated with privacy-violating intent can be separated from benign requests using linear structure. Using this insight, the paper proposes NeuroFilter, a guardrail framework that operationalizes contextual integrity by mapping norm violations to simple directions in the model's activation space, enabling detection even when semantic filters are bypassed. The proposed filter is also extended to capture threats arising during long conversations using the concept of activation velocity, which measures cumulative drift in internal representations across turns. A comprehensive evaluation across over 150,000 interactions and covering models from 7B to 70B parameters, illustrates the strong performance of NeuroFilter in detecting privacy attacks while maintaining zero false positives on benign prompts, all while reducing the computational inference cost by several orders of magnitude when compared to LLM-based agentic privacy defenses.