ToolCaching: Towards Efficient Caching for LLM Tool-calling
作者: Yi Zhai, Dian Shen, Junzhou Luo, Bin Yang
分类: cs.SE, cs.AI, cs.PL
发布日期: 2026-01-20
💡 一句话要点
提出ToolCaching,解决LLM工具调用中冗余请求问题,提升缓存效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM工具调用 缓存策略 特征驱动 自适应缓存 VAAC算法
📋 核心要点
- 现有LLM工具调用存在大量冗余请求,传统缓存策略难以应对异构语义和动态负载。
- ToolCaching通过集成语义和系统级特征,自适应评估请求可缓存性和缓存价值。
- VAAC算法结合bandit准入和价值驱动驱逐,实验表明可显著提升缓存命中率并降低延迟。
📝 摘要(中文)
大型语言模型(LLM)的最新进展彻底改变了Web应用程序,通过自然语言界面实现了智能搜索、推荐和助手服务。工具调用扩展了LLM与外部API交互的能力,极大地增强了它们的实用性。虽然之前的研究通过采用传统的计算机系统技术(如并行和异步执行)提高了工具调用性能,但冗余或重复工具调用请求的挑战在很大程度上仍未得到解决。缓存是解决此问题的经典方法,但将其应用于LLM工具调用会带来新的困难,因为异构的请求语义、动态的工作负载和不同的新鲜度要求使得传统的缓存策略无效。为了解决这些问题,我们提出了ToolCaching,这是一种高效的、特征驱动的、自适应的LLM工具调用系统缓存框架。ToolCaching系统地集成了语义和系统级特征,以评估请求的可缓存性并估计缓存价值。其核心是VAAC算法,该算法集成了基于bandit的准入控制和价值驱动的多因素驱逐,共同考虑了请求频率、新近度和缓存价值。在合成和公共工具调用工作负载上的大量实验表明,与标准策略相比,使用VAAC的ToolCaching实现了高达11%的缓存命中率和34%的延迟降低,有效地加速了实际应用中的LLM工具调用。
🔬 方法详解
问题定义:论文旨在解决LLM工具调用过程中大量存在的冗余或重复请求问题。现有方法,如并行和异步执行,虽然能提升工具调用性能,但未能有效解决冗余请求带来的资源浪费和延迟增加。传统的缓存策略由于无法有效处理LLM工具调用请求的异构语义、动态工作负载和不同的新鲜度要求,因此效果不佳。
核心思路:论文的核心思路是利用缓存机制,但针对LLM工具调用的特点进行优化。通过提取和利用请求的语义和系统级特征,自适应地评估请求的可缓存性,并估计其缓存价值。这样可以更有效地决定哪些请求应该被缓存,以及如何管理缓存中的数据,从而提高缓存命中率,降低延迟。
技术框架:ToolCaching框架主要包含以下几个模块:特征提取模块,负责提取请求的语义和系统级特征;可缓存性评估模块,基于提取的特征评估请求是否适合缓存;缓存价值估计模块,估计请求的缓存价值,用于指导缓存的准入和驱逐;缓存管理模块,负责实际的缓存操作,包括数据的存储、检索和淘汰。VAAC算法是缓存管理模块的核心,它集成了基于bandit的准入控制和价值驱动的多因素驱逐策略。
关键创新:论文的关键创新在于提出了一个特征驱动和自适应的缓存框架,专门针对LLM工具调用进行了优化。与传统的缓存策略不同,ToolCaching能够根据请求的语义和系统级特征,动态地调整缓存策略,从而更好地适应LLM工具调用的特点。VAAC算法的bandit准入和价值驱动驱逐机制,能够有效地平衡缓存的利用率和命中率。
关键设计:VAAC算法是ToolCaching的关键设计。它使用bandit算法来学习不同请求的缓存价值,并根据学习到的价值来决定是否允许新的请求进入缓存。在缓存空间不足时,VAAC算法会根据请求的频率、新近度和缓存价值等多个因素,选择要驱逐的请求。具体的参数设置和损失函数未知,需要在论文中进一步查找。
🖼️ 关键图片
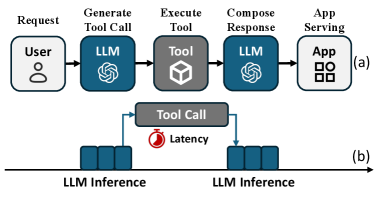
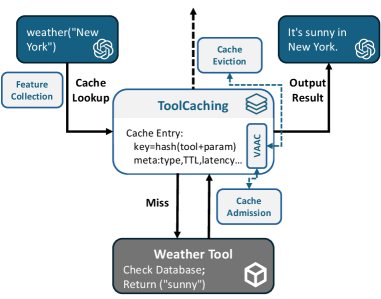

📊 实验亮点
实验结果表明,ToolCaching与VAAC算法相比于标准缓存策略,在合成和公共工具调用工作负载上,实现了高达11%的缓存命中率提升和34%的延迟降低。这些数据表明ToolCaching能够有效地加速LLM工具调用,并在实际应用中具有显著的性能优势。
🎯 应用场景
ToolCaching可广泛应用于各种需要LLM工具调用的场景,例如智能助手、智能搜索、推荐系统等。通过减少冗余的API调用,可以显著降低延迟,提高用户体验,并节省计算资源。该研究对于提升LLM在实际应用中的效率和可用性具有重要意义,并为未来的LLM系统优化提供了新的思路。
📄 摘要(原文)
Recent advances in Large Language Models (LLMs) have revolutionized web applications, enabling intelligent search, recommendation, and assistant services with natural language interfaces. Tool-calling extends LLMs with the ability to interact with external APIs, greatly enhancing their practical utility. While prior research has improved tool-calling performance by adopting traditional computer systems techniques, such as parallel and asynchronous execution, the challenge of redundant or repeated tool-calling requests remains largely unaddressed. Caching is a classic solution to this problem, but applying it to LLM tool-calling introduces new difficulties due to heterogeneous request semantics, dynamic workloads, and varying freshness requirements, which render conventional cache policies ineffective. To address these issues, we propose ToolCaching, an efficient feature-driven and adaptive caching framework for LLM tool-calling systems. ToolCaching systematically integrates semantic and system-level features to evaluate request cacheability and estimate caching value. At its core, the VAAC algorithm integrates bandit-based admission with value-driven, multi-factor eviction, jointly accounting for request frequency, recency, and caching value. Extensive experiments on synthetic and public tool-calling workloads demonstrate that ToolCaching with VAAC achieves up to 11% higher cache hit ratios and 34% lower latency compared to standard policies, effectively accelerating LLM tool-calling in practical applications.