Large Language Model-Powered Evolutionary Code Optimization on a Phylogenetic Tree
作者: Leyi Zhao, Weijie Huang, Yitong Guo, Jiang Bian, Chenghong Wang, Xuhong Zhang
分类: cs.AI, cs.LG
发布日期: 2026-01-20
🔗 代码/项目: GITHUB
💡 一句话要点
提出PhyloEvolve以解决GPU算法优化中的效率问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 进化算法 上下文强化学习 系统发育树 算法优化 科学计算 性能提升
📋 核心要点
- 现有的GPU算法优化方法依赖于结果选择和随机变异,未能充分利用迭代过程中的轨迹信息,导致效率低下。
- 本文提出PhyloEvolve,通过将优化问题转化为上下文强化学习,利用历史优化经验,避免了模型重训练。
- 在多个科学计算工作负载上,PhyloEvolve展示了在运行时间、内存效率和正确性上的一致性提升,超越了基线和传统进化方法。
📝 摘要(中文)
优化现代GPU的科学计算算法是一个劳动密集型的迭代过程,涉及代码修改、基准测试和调优。尽管已有研究探索了基于大型语言模型(LLM)的进化方法进行自动化代码优化,但这些方法主要依赖结果选择和随机变异,未充分利用迭代优化过程中生成的丰富轨迹信息。本文提出PhyloEvolve,一个将GPU导向算法优化重新框定为上下文强化学习(ICRL)问题的LLM代理系统。该系统通过算法蒸馏和基于提示的决策变换器集成到迭代工作流中,利用算法修改序列和性能反馈作为学习信号。我们引入了捕捉算法变体之间继承、分歧和重组的系统发育树表示,支持回溯、跨谱系转移和可重复性。实验结果表明,PhyloEvolve在多个科学计算工作负载上均表现出显著的运行时、内存效率和正确性提升。
🔬 方法详解
问题定义:本文旨在解决GPU算法优化中的低效问题,现有方法未能充分利用优化过程中的轨迹信息,导致优化效果不佳。
核心思路:PhyloEvolve通过将算法优化视为上下文强化学习问题,能够在不重训练模型的情况下重用优化经验,从而提高效率和效果。
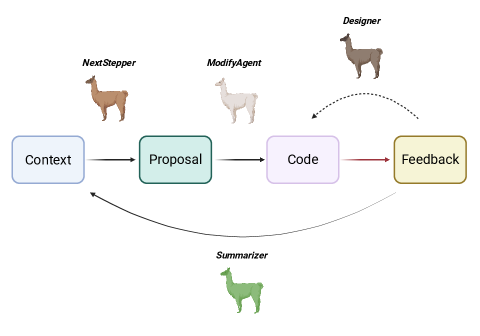
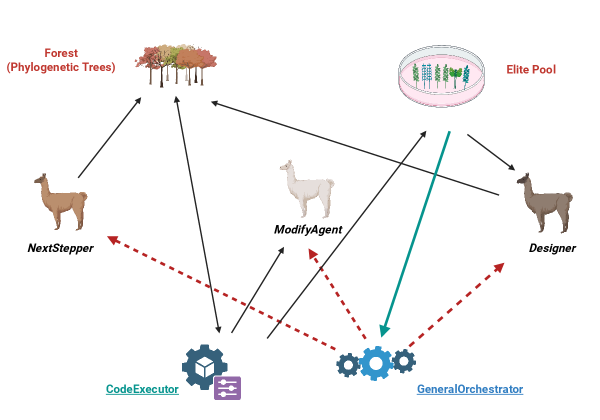
技术框架:系统整体架构包括算法蒸馏、基于提示的决策变换器和迭代工作流,利用算法修改序列和性能反馈作为学习信号,并通过系统发育树组织优化历史。
关键创新:引入系统发育树表示,捕捉算法变体之间的继承和重组关系,支持回溯和跨谱系转移,显著提升了优化的可重复性和效率。
关键设计:系统结合精英轨迹池、多岛平行探索和容器化执行,平衡了在异构硬件上的探索与利用,确保了优化过程的高效性。
🖼️ 关键图片
📊 实验亮点
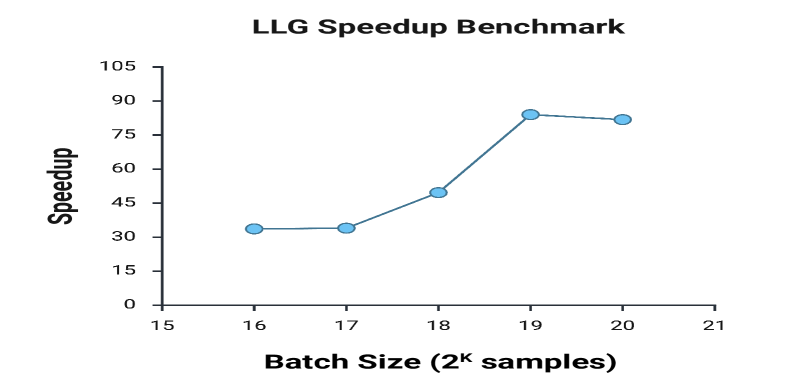
在多个科学计算工作负载上,PhyloEvolve展示了显著的性能提升,具体表现为运行时间减少、内存效率提高和结果正确性增强,相较于基线和传统进化方法,优化效果显著。
🎯 应用场景
PhyloEvolve的研究成果在科学计算、机器学习算法优化等领域具有广泛的应用潜力。通过提高算法优化的效率和准确性,该系统可以帮助研究人员和工程师更快速地开发高性能计算应用,推动相关领域的技术进步。
📄 摘要(原文)
Optimizing scientific computing algorithms for modern GPUs is a labor-intensive and iterative process involving repeated code modification, benchmarking, and tuning across complex hardware and software stacks. Recent work has explored large language model (LLM)-assisted evolutionary methods for automated code optimization, but these approaches primarily rely on outcome-based selection and random mutation, underutilizing the rich trajectory information generated during iterative optimization. We propose PhyloEvolve, an LLM-agent system that reframes GPU-oriented algorithm optimization as an In-Context Reinforcement Learning (ICRL) problem. This formulation enables trajectory-conditioned reuse of optimization experience without model retraining. PhyloEvolve integrates Algorithm Distillation and prompt-based Decision Transformers into an iterative workflow, treating sequences of algorithm modifications and performance feedback as first-class learning signals. To organize optimization history, we introduce a phylogenetic tree representation that captures inheritance, divergence, and recombination among algorithm variants, enabling backtracking, cross-lineage transfer, and reproducibility. The system combines elite trajectory pooling, multi-island parallel exploration, and containerized execution to balance exploration and exploitation across heterogeneous hardware. We evaluate PhyloEvolve on scientific computing workloads including PDE solvers, manifold learning, and spectral graph algorithms, demonstrating consistent improvements in runtime, memory efficiency, and correctness over baseline and evolutionary methods. Code is published at: https://github.com/annihi1ation/phylo_evolve