On the Generalization Gap in LLM Planning: Tests and Verifier-Reward RL
作者: Valerio Belcamino, Nicholas Attolino, Alessio Capitanelli, Fulvio Mastrogiovanni
分类: cs.AI, cs.LG
发布日期: 2026-01-20
备注: 9 pages, 4 figures, 3 tables, 2 pages of supplementary materials. Submitted to a conference implementing a double-blind review process
💡 一句话要点
揭示LLM规划泛化差距:提出诊断干预方法与验证器奖励强化学习
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 规划任务 泛化能力 强化学习 符号匿名化
📋 核心要点
- 现有研究表明,微调LLM在PDDL规划任务中表现良好,但其泛化能力仍不明确,可能过度依赖领域特定信息。
- 本文通过诊断干预(符号匿名化、紧凑序列化)和验证器奖励强化学习,分析LLM规划的泛化能力。
- 实验表明,LLM对表面表示敏感,且验证器奖励强化学习未能有效提升跨域泛化能力,揭示了泛化差距。
📝 摘要(中文)
本文研究了微调的大型语言模型(LLM)在PDDL规划任务中的泛化能力。作者在一个包含10个IPC 2023领域的40,000个领域-问题-计划元组上微调了一个17亿参数的LLM,并评估了其在域内和跨域的泛化性能。结果表明,该模型在域内条件下达到了82.9%的有效计划率,但在两个未见领域上的有效计划率为0%。为了分析这种失败,作者引入了三种诊断干预方法:(i)实例级符号匿名化,(ii)紧凑计划序列化,以及(iii)使用VAL验证器作为成功导向的强化信号进行验证器奖励微调。符号匿名化和紧凑序列化导致性能显著下降,表明模型对表面表示具有很强的敏感性。验证器奖励微调在监督训练的一半epoch内达到性能饱和,但并未改善跨域泛化。结果表明,所探索的配置中,域内性能稳定在80%左右,而跨域性能崩溃,表明微调后的模型严重依赖于特定领域的模式,而不是可转移的规划能力。研究结果突出了基于LLM的规划中存在的泛化差距,并为研究其原因提供了诊断工具。
🔬 方法详解
问题定义:论文旨在解决LLM在规划任务中泛化能力不足的问题。现有方法虽然在特定领域表现良好,但缺乏跨领域的可迁移性,可能过度依赖训练数据中的领域特定模式,而非真正的规划能力。
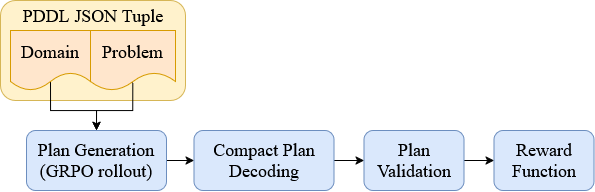
核心思路:论文的核心思路是通过一系列诊断干预和验证器奖励强化学习,来探究LLM在规划任务中的泛化瓶颈。通过分析模型对不同输入表示的敏感性,以及利用外部验证器提供的奖励信号进行微调,来提升模型的泛化能力。
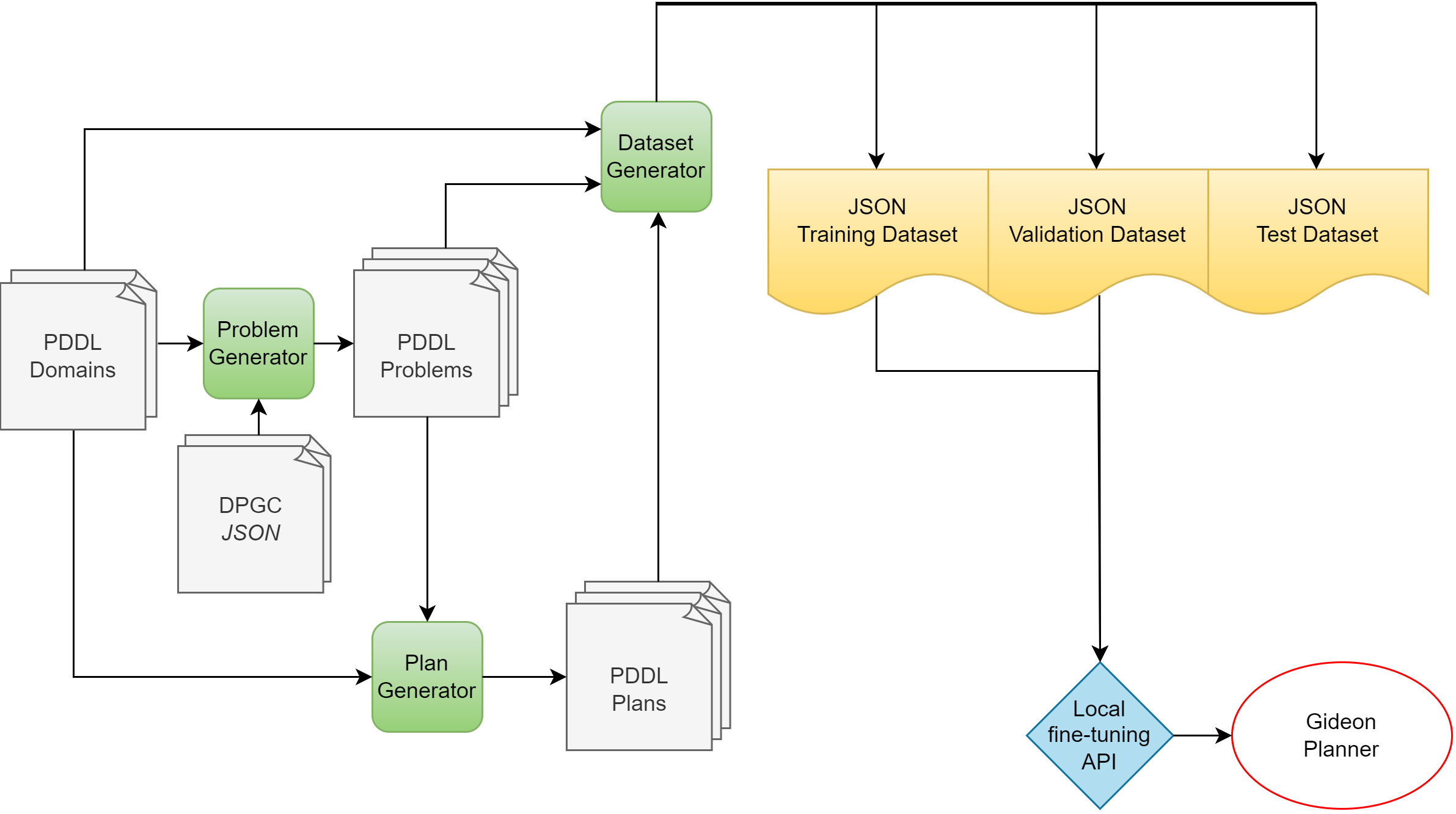
技术框架:整体框架包括三个主要部分:1) 使用包含多个规划领域的 PDDL 数据集微调 LLM;2) 应用三种诊断干预(符号匿名化、紧凑计划序列化)来评估模型对输入表示的敏感性;3) 使用 VAL 验证器作为奖励信号,通过强化学习进一步微调 LLM。
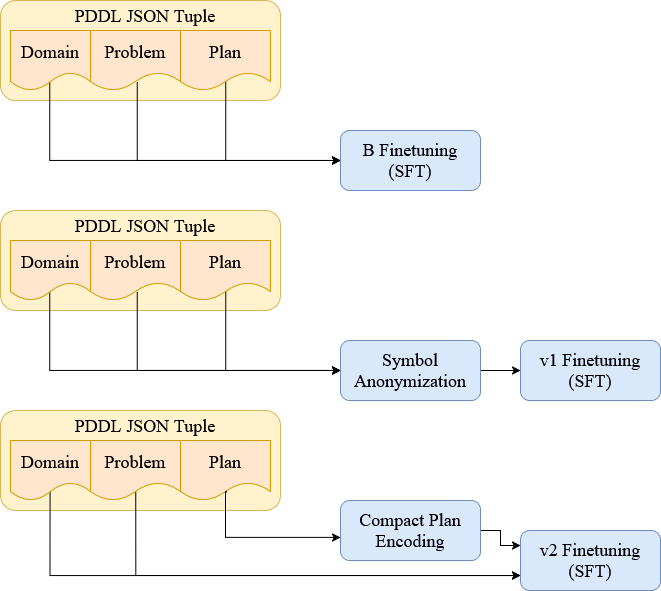
关键创新:论文的关键创新在于提出了三种诊断干预方法,用于评估LLM对规划任务中表面表示的敏感性。这些方法能够有效揭示模型是否真正学习到了通用的规划能力,还是仅仅记住了特定领域的模式。此外,使用外部验证器作为奖励信号进行强化学习微调,也是一种新颖的尝试。
关键设计:符号匿名化通过替换实例中的符号来改变输入表示,同时保持计划的语义不变。紧凑计划序列化旨在减少计划的冗余信息,使模型更关注关键步骤。验证器奖励强化学习使用 VAL 验证器来判断计划的有效性,并根据验证结果提供奖励信号,以指导模型的学习。具体而言,使用PPO算法进行强化学习微调,奖励函数基于VAL验证器的输出。
🖼️ 关键图片
📊 实验亮点
实验结果表明,微调后的LLM在域内达到了82.9%的有效计划率,但在未见领域上的有效计划率为0%。符号匿名化和紧凑序列化导致性能显著下降,验证器奖励微调未能有效改善跨域泛化。这些结果揭示了LLM在规划任务中存在的显著泛化差距。
🎯 应用场景
该研究成果可应用于提升AI规划系统的可靠性和泛化能力,例如在机器人导航、任务调度、游戏AI等领域。通过诊断工具,可以更好地理解和改进LLM在复杂规划任务中的表现,推动通用人工智能的发展。
📄 摘要(原文)
Recent work shows that fine-tuned Large Language Models (LLMs) can achieve high valid plan rates on PDDL planning tasks. However, it remains unclear whether this reflects transferable planning competence or domain-specific memorization. In this work, we fine-tune a 1.7B-parameter LLM on 40,000 domain-problem-plan tuples from 10 IPC 2023 domains, and evaluate both in-domain and cross-domain generalization. While the model reaches 82.9% valid plan rate in in-domain conditions, it achieves 0% on two unseen domains. To analyze this failure, we introduce three diagnostic interventions, namely (i) instance-wise symbol anonymization, (ii) compact plan serialization, and (iii) verifier-reward fine-tuning using the VAL validator as a success-focused reinforcement signal. Symbol anonymization and compact serialization cause significant performance drops despite preserving plan semantics, thus revealing strong sensitivity to surface representations. Verifier-reward fine-tuning reaches performance saturation in half the supervised training epochs, but does not improve cross-domain generalization. For the explored configurations, in-domain performance plateaus around 80%, while cross-domain performance collapses, suggesting that our fine-tuned model relies heavily on domain-specific patterns rather than transferable planning competence in this setting. Our results highlight a persistent generalization gap in LLM-based planning and provide diagnostic tools for studying its causes.