Diffusion Large Language Models for Black-Box Optimization
作者: Ye Yuan, Can, Chen, Zipeng Sun, Dinghuai Zhang, Christopher Pal, Xue Liu
分类: cs.CE, cs.AI
发布日期: 2026-01-20
💡 一句话要点
提出基于扩散语言模型的黑盒优化方法dLLM,在少量样本下实现设计优化。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 黑盒优化 扩散模型 大型语言模型 蒙特卡洛树搜索 设计优化 少量样本学习
📋 核心要点
- 现有黑盒优化方法依赖于任务特定的代理或生成模型,忽略了大型语言模型的上下文学习能力。
- 论文提出基于扩散语言模型的黑盒优化方法dLLM,利用其双向建模和迭代细化能力。
- dLLM在design-bench的少量样本设置中取得了state-of-the-art的结果,验证了方法的有效性。
📝 摘要(中文)
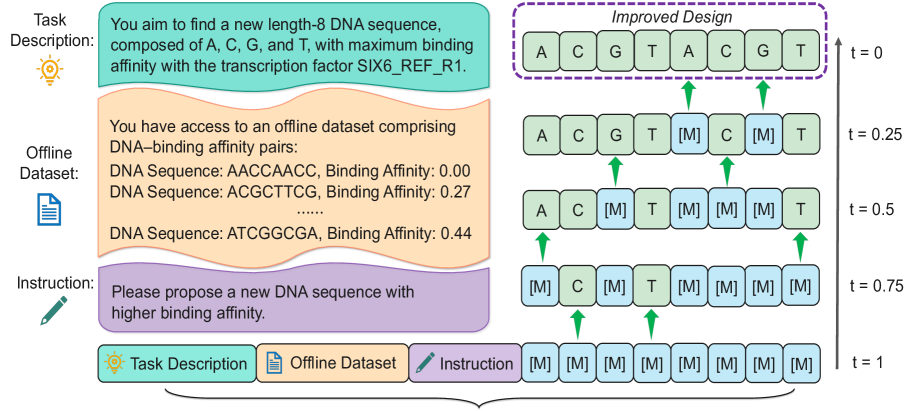
离线黑盒优化(BBO)旨在仅基于离线数据集(包含设计及其标签)找到最优设计。这种情况常见于DNA序列设计和机器人等领域,在这些领域中,只有少量带标签的数据点可用。传统方法通常依赖于特定于任务的代理模型或生成模型,忽略了预训练大型语言模型(LLM)的上下文学习能力。最近的研究工作通过将任务描述和离线数据集构建为自然语言提示,使自回归LLM适应于BBO,从而实现直接设计生成。然而,这些设计通常包含双向依赖关系,而从左到右的模型难以捕捉这些依赖关系。在本文中,我们探索了用于BBO的扩散LLM,利用其双向建模和迭代细化能力。这促使我们提出了上下文去噪模块:我们以自然语言格式的任务描述和离线数据集为条件,提示扩散LLM将掩码设计去噪为改进的候选设计。为了引导生成过程朝着高性能设计发展,我们引入了掩码扩散树搜索,它将去噪过程转化为逐步蒙特卡洛树搜索,动态平衡探索和利用。每个节点代表一个部分掩码设计,每个去噪步骤都是一个动作,并通过在高斯过程下训练的预期改进来评估候选设计。我们的方法dLLM在design-bench上的少量样本设置中实现了最先进的结果。
🔬 方法详解
问题定义:论文旨在解决离线黑盒优化问题,即在只有少量带标签的离线数据的情况下,找到最优的设计方案。现有方法,如基于自回归LLM的方法,难以捕捉设计中存在的双向依赖关系,限制了优化效果。
核心思路:论文的核心思路是利用扩散语言模型(Diffusion LLM)的双向建模能力和迭代细化能力来解决黑盒优化问题。通过将任务描述和离线数据集作为自然语言提示,引导扩散LLM生成更优的设计方案。
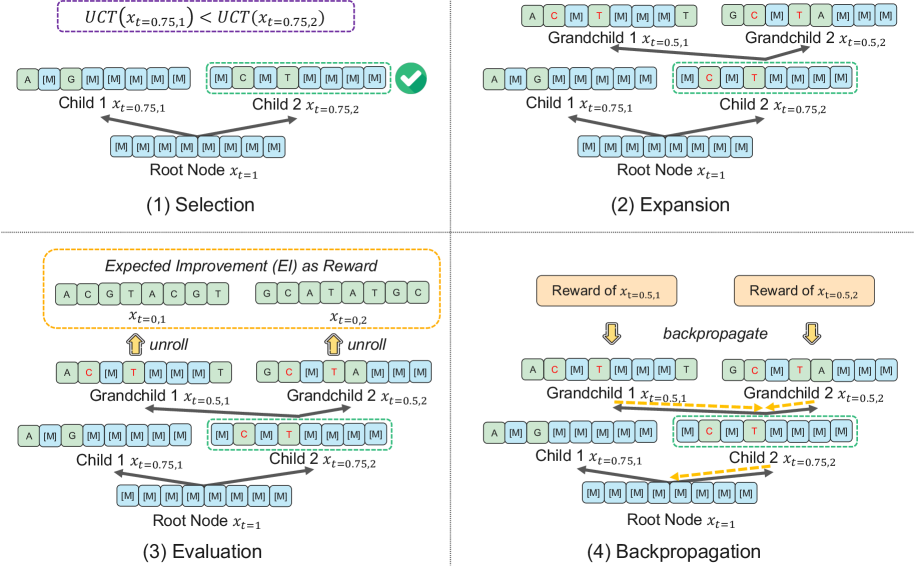
技术框架:dLLM方法包含两个主要模块:上下文去噪模块和掩码扩散树搜索。上下文去噪模块以自然语言格式的任务描述和离线数据集为条件,提示扩散LLM将掩码设计去噪为改进的候选设计。掩码扩散树搜索将去噪过程转化为逐步蒙特卡洛树搜索,动态平衡探索和利用,引导生成过程朝着高性能设计发展。
关键创新:关键创新在于将扩散模型引入黑盒优化领域,并设计了上下文去噪模块和掩码扩散树搜索算法。扩散模型能够更好地捕捉设计中的双向依赖关系,而掩码扩散树搜索能够有效地探索设计空间,找到更优的设计方案。
关键设计:掩码扩散树搜索中,每个节点代表一个部分掩码设计,每个去噪步骤都是一个动作。候选设计通过在高斯过程下训练的预期改进来评估。高斯过程模型基于离线数据集进行训练,用于预测设计的性能。蒙特卡洛树搜索算法平衡了探索(探索未知的区域)和利用(利用已知的优秀区域),以找到全局最优解。
🖼️ 关键图片
📊 实验亮点
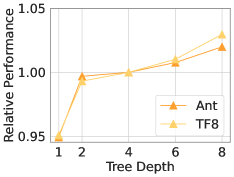
dLLM在design-bench数据集上的少量样本设置中取得了state-of-the-art的结果。实验结果表明,dLLM能够有效地利用离线数据,生成高性能的设计方案,显著优于现有的黑盒优化方法。具体的性能提升数据在论文中给出。
🎯 应用场景
该研究成果可应用于DNA序列设计、机器人设计、材料设计等领域,在这些领域中,获取带标签的数据成本高昂,需要利用少量数据进行优化。该方法能够加速设计过程,降低实验成本,并有可能发现更优的设计方案。
📄 摘要(原文)
Offline black-box optimization (BBO) aims to find optimal designs based solely on an offline dataset of designs and their labels. Such scenarios frequently arise in domains like DNA sequence design and robotics, where only a few labeled data points are available. Traditional methods typically rely on task-specific proxy or generative models, overlooking the in-context learning capabilities of pre-trained large language models (LLMs). Recent efforts have adapted autoregressive LLMs to BBO by framing task descriptions and offline datasets as natural language prompts, enabling direct design generation. However, these designs often contain bidirectional dependencies, which left-to-right models struggle to capture. In this paper, we explore diffusion LLMs for BBO, leveraging their bidirectional modeling and iterative refinement capabilities. This motivates our in-context denoising module: we condition the diffusion LLM on the task description and the offline dataset, both formatted in natural language, and prompt it to denoise masked designs into improved candidates. To guide the generation toward high-performing designs, we introduce masked diffusion tree search, which casts the denoising process as a step-wise Monte Carlo Tree Search that dynamically balances exploration and exploitation. Each node represents a partially masked design, each denoising step is an action, and candidates are evaluated via expected improvement under a Gaussian Process trained on the offline dataset. Our method, dLLM, achieves state-of-the-art results in few-shot settings on design-bench.