VisTIRA: Closing the Image-Text Modality Gap in Visual Math Reasoning via Structured Tool Integration
作者: Saeed Khaki, Ashudeep Singh, Nima Safaei, Kamal Ginotra
分类: cs.AI, cs.CL, cs.LG
发布日期: 2026-01-20
💡 一句话要点
VisTIRA:通过结构化工具集成弥合视觉数学推理中的图像-文本模态差距
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉数学推理 工具集成 模态差距 视觉语言模型 结构化推理 OCR grounding 图像理解
📋 核心要点
- 视觉语言模型在处理图像形式的数学问题时,性能显著低于文本形式,存在明显的模态差距。
- VisTIRA框架通过将图像数学问题分解为自然语言和可执行代码,利用工具进行结构化推理。
- 实验表明,工具集成监督和OCR grounding能有效提升图像数学推理性能,尤其对小模型效果显著。
📝 摘要(中文)
当数学问题以图像形式呈现时,视觉语言模型(VLMs)在数学推理方面落后于纯文本语言模型。本文将此现象定义为模态差距:相同的问题以文本形式呈现会产生明显更高的准确率,这是由于在阅读密集公式、布局和混合符号-图表上下文中的复合失败所致。首先,本文提出了VisTIRA(视觉和工具集成推理代理),一个工具集成的推理框架,它通过迭代地将给定的数学问题(作为图像)分解为自然语言的理由和可执行的Python步骤来确定最终答案,从而实现结构化的解决问题。其次,本文构建了一个框架来测量和改进视觉数学推理:一个基于LaTeX的pipeline,将思维链数学语料库(例如,NuminaMath)转换为具有挑战性的图像对应物,以及从真实世界的家庭作业式图像数据集(称为SnapAsk)派生的大量合成工具使用轨迹,用于微调VLM。实验表明,工具集成监督可以改善基于图像的推理,而OCR grounding可以进一步缩小较小模型的差距,尽管其优势会随着规模的扩大而减小。这些发现表明,模态差距的严重程度与模型大小成反比,并且结构化推理和基于OCR的grounding是推进视觉数学推理的互补策略。
🔬 方法详解
问题定义:论文旨在解决视觉数学推理中存在的图像-文本模态差距问题。现有的视觉语言模型在处理图像形式的数学问题时,由于难以理解复杂的公式、布局以及混合的符号和图表,性能远低于处理文本形式的相同问题。这表明现有方法在视觉信息的理解和推理方面存在不足。
核心思路:论文的核心思路是通过引入工具集成,将复杂的视觉数学问题分解为更易于处理的子问题。具体来说,模型首先将图像问题转化为自然语言的理由,然后生成可执行的Python代码,利用外部工具(如计算器、符号计算库)来解决这些子问题,最终得到答案。这种结构化的推理过程有助于模型更好地理解问题并减少错误。
技术框架:VisTIRA框架包含以下主要模块:1) 图像编码器:用于提取图像的视觉特征。2) 自然语言理由生成器:将视觉特征转化为自然语言描述,解释解题思路。3) 代码生成器:根据自然语言理由生成可执行的Python代码。4) 工具执行器:执行生成的代码,得到中间结果。5) 答案预测器:根据中间结果和原始问题,预测最终答案。整个流程是一个迭代的过程,模型可以根据中间结果不断调整解题策略。
关键创新:论文的关键创新在于将工具集成到视觉数学推理框架中。与传统的端到端模型相比,VisTIRA能够利用外部工具进行精确计算和符号推理,从而显著提高了解题的准确性。此外,论文还提出了一个基于LaTeX的pipeline,用于生成具有挑战性的图像数学问题,并构建了一个大规模的合成工具使用轨迹数据集,用于微调视觉语言模型。
关键设计:在自然语言理由生成器和代码生成器中,可以使用Transformer架构。损失函数可以包括交叉熵损失和代码执行结果的监督损失。为了提高代码的正确性,可以使用代码验证技术,例如通过执行生成的代码并检查其是否符合预期的行为。在训练过程中,可以使用强化学习来优化工具的使用策略。
🖼️ 关键图片

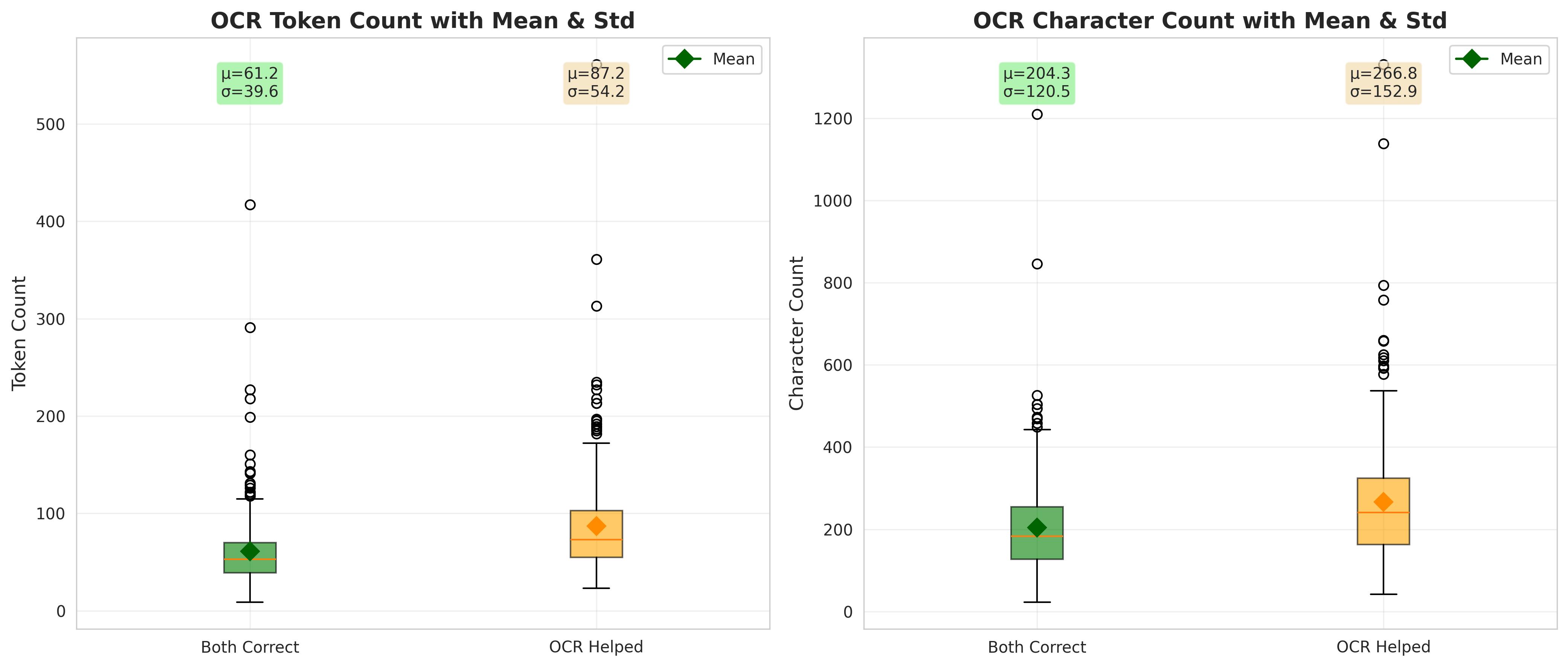
📊 实验亮点
实验结果表明,VisTIRA框架能够显著提高视觉数学推理的准确性。通过工具集成监督,模型在图像数学问题上的性能得到了显著提升。此外,OCR grounding对于较小模型的性能提升尤为明显。研究还发现,模态差距的严重程度与模型大小成反比,表明更大的模型具有更强的视觉信息处理能力。
🎯 应用场景
该研究成果可应用于智能教育领域,例如自动批改数学作业、提供个性化辅导等。此外,该技术还可以扩展到其他需要视觉信息理解和推理的领域,例如科学文档分析、工程图纸理解等。未来,该研究有望推动视觉语言模型在复杂推理任务中的应用。
📄 摘要(原文)
Vision-language models (VLMs) lag behind text-only language models on mathematical reasoning when the same problems are presented as images rather than text. We empirically characterize this as a modality gap: the same question in text form yields markedly higher accuracy than its visually typeset counterpart, due to compounded failures in reading dense formulas, layout, and mixed symbolic-diagrammatic context. First, we introduce VisTIRA (Vision and Tool-Integrated Reasoning Agent), a tool-integrated reasoning framework that enables structured problem solving by iteratively decomposing a given math problem (as an image) into natural language rationales and executable Python steps to determine the final answer. Second, we build a framework to measure and improve visual math reasoning: a LaTeX-based pipeline that converts chain-of-thought math corpora (e.g., NuminaMath) into challenging image counterparts, and a large set of synthetic tool-use trajectories derived from a real-world, homework-style image dataset (called SnapAsk) for fine-tuning VLMs. Our experiments show that tool-integrated supervision improves image-based reasoning, and OCR grounding can further narrow the gap for smaller models, although its benefit diminishes at scale. These findings highlight that modality gap severity inversely correlates with model size, and that structured reasoning and OCR-based grounding are complementary strategies for advancing visual mathematical reasoning.