MATE: Matryoshka Audio-Text Embeddings for Open-Vocabulary Keyword Spotting
作者: Youngmoon Jung, Myunghun Jung, Joon-Young Yang, Yong-Hyeok Lee, Jaeyoung Roh, Hoon-Young Cho
分类: eess.AS, cs.AI
发布日期: 2026-01-20
备注: 5 pages, 1 figure, Accepted at ICASSP 2026
💡 一句话要点
提出MATE:用于开放词汇关键词检索的俄罗斯套娃式音频-文本嵌入
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 关键词检索 开放词汇 俄罗斯套娃嵌入 多粒度学习 深度度量学习
📋 核心要点
- 现有开放词汇关键词检索方法通常采用固定维度的嵌入,忽略了不同粒度信息的重要性。
- MATE通过嵌套子嵌入(前缀)在单个向量中编码多粒度信息,利用PCA引导前缀对齐,提升关键词检索性能。
- MATE在WSJ和LibriPhrase数据集上取得了SOTA结果,且没有引入额外的推理计算负担。
📝 摘要(中文)
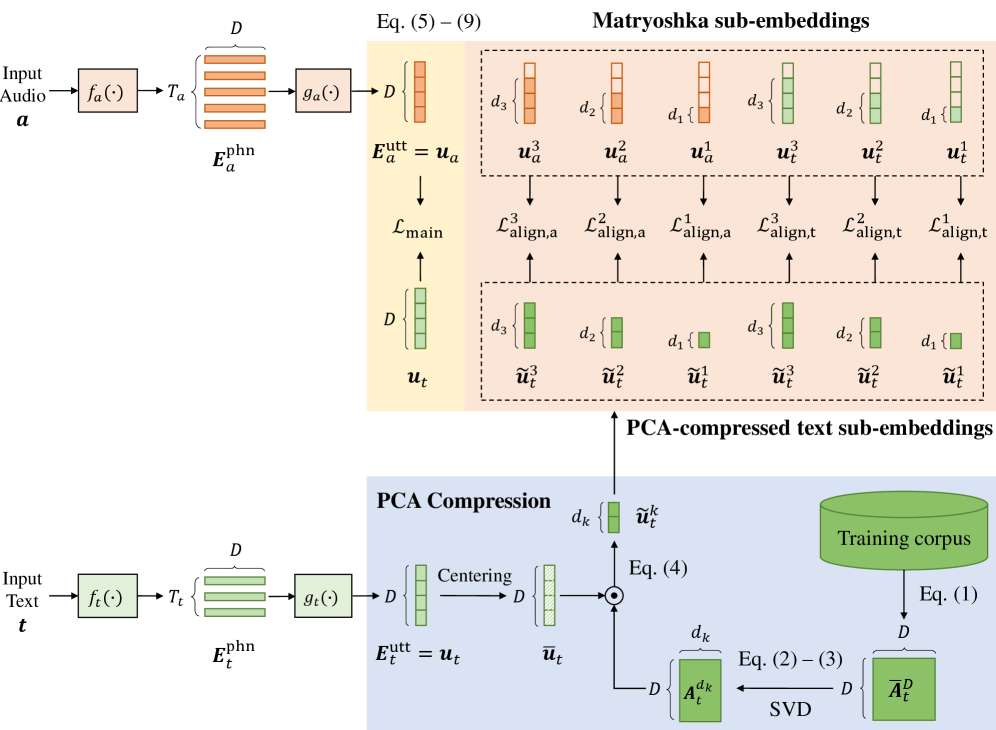
本文提出了一种名为Matryoshka Audio-Text Embeddings (MATE) 的双编码器框架,用于开放词汇关键词检索(KWS)。与以往基于单维度嵌入学习的语句级匹配方法不同,MATE通过嵌套的子嵌入(“前缀”)在单个向量中编码多个嵌入粒度。具体来说,引入了一种PCA引导的前缀对齐方法:每个前缀大小的完整文本嵌入的PCA压缩版本作为教师目标,用于对齐音频和文本前缀。这种对齐将显著的关键词线索集中在较低维度的前缀中,而较高维度则添加细节。MATE使用标准的深度度量学习目标进行音频-文本KWS训练,并且与损失函数无关。据我们所知,这是俄罗斯套娃式嵌入首次应用于KWS,在WSJ和LibriPhrase上实现了最先进的结果,且没有任何推理开销。
🔬 方法详解
问题定义:论文旨在解决开放词汇关键词检索(KWS)问题。现有方法主要采用基于文本的注册方式,但通常使用单一固定维度的嵌入来表示音频和文本,忽略了不同粒度信息的重要性,限制了模型的表达能力和检索性能。
核心思路:论文的核心思路是利用“俄罗斯套娃”式的嵌入结构,即Matryoshka Embeddings,在单个向量中嵌入多个不同粒度的子嵌入(前缀)。通过这种方式,模型可以同时学习到关键词的粗粒度和细粒度特征,从而提升检索的准确性。同时,利用PCA引导的前缀对齐,使得不同粒度的音频和文本嵌入能够更好地对齐。
技术框架:MATE是一个双编码器框架,包含音频编码器和文本编码器。两个编码器分别将音频和文本输入映射到嵌入空间。关键在于嵌入向量的结构,采用了嵌套的子嵌入(前缀)。训练过程中,使用PCA压缩后的文本嵌入作为教师信号,引导音频和文本前缀的对齐。整体流程包括:1) 音频和文本编码;2) 生成多粒度嵌入;3) PCA引导的前缀对齐;4) 使用深度度量学习目标进行训练。
关键创新:MATE的关键创新在于:1) 首次将Matryoshka Embeddings应用于KWS任务,实现了多粒度信息的编码;2) 提出了PCA引导的前缀对齐方法,有效地对齐了不同粒度的音频和文本嵌入。与现有方法的本质区别在于,MATE能够学习到不同粒度的关键词特征,而现有方法通常只关注单一粒度的特征。
关键设计:在实现PCA引导的前缀对齐时,首先对完整的文本嵌入进行PCA降维,得到不同维度(对应不同前缀长度)的教师目标。然后,使用均方误差(MSE)等损失函数,使得音频和文本前缀尽可能接近对应的教师目标。损失函数方面,可以使用标准的深度度量学习目标,如对比损失(Contrastive Loss)或Triplet Loss。网络结构方面,音频和文本编码器可以使用各种常见的神经网络结构,如卷积神经网络(CNN)或Transformer。
🖼️ 关键图片
📊 实验亮点
MATE在WSJ和LibriPhrase数据集上取得了最先进的结果,显著优于现有的KWS方法。实验结果表明,MATE能够有效地学习到多粒度的关键词特征,并且PCA引导的前缀对齐能够提升嵌入的质量。值得注意的是,MATE在提升性能的同时,并没有引入额外的推理开销。
🎯 应用场景
MATE在智能助手、语音搜索、语音控制等领域具有广泛的应用前景。例如,用户可以通过语音注册任意关键词,系统即可快速准确地识别该关键词。该技术还可以应用于语音监控、安全认证等场景,提升系统的智能化水平和用户体验。未来,MATE有望进一步扩展到其他多模态检索任务中。
📄 摘要(原文)
Open-vocabulary keyword spotting (KWS) with text-based enrollment has emerged as a flexible alternative to fixed-phrase triggers. Prior utterance-level matching methods, from an embedding-learning standpoint, learn embeddings at a single fixed dimensionality. We depart from this design and propose Matryoshka Audio-Text Embeddings (MATE), a dual-encoder framework that encodes multiple embedding granularities within a single vector via nested sub-embeddings ("prefixes"). Specifically, we introduce a PCA-guided prefix alignment: PCA-compressed versions of the full text embedding for each prefix size serve as teacher targets to align both audio and text prefixes. This alignment concentrates salient keyword cues in lower-dimensional prefixes, while higher dimensions add detail. MATE is trained with standard deep metric learning objectives for audio-text KWS, and is loss-agnostic. To our knowledge, this is the first application of matryoshka-style embeddings to KWS, achieving state-of-the-art results on WSJ and LibriPhrase without any inference overhead.