torch-sla: Differentiable Sparse Linear Algebra with Adjoint Solvers and Sparse Tensor Parallelism for PyTorch
作者: Mingyuan Chi
分类: cs.DC, cs.AI
发布日期: 2026-01-20
🔗 代码/项目: GITHUB
💡 一句话要点
提出torch-sla以解决稀疏线性代数计算效率问题
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation)
关键词: 稀疏线性代数 GPU加速 多GPU扩展 自动微分 科学计算
📋 核心要点
- 现有的稀疏线性代数求解方法在GPU加速和多GPU扩展方面存在效率瓶颈,难以满足大规模科学计算的需求。
- 本文提出的torch-sla库通过GPU加速和领域分解技术,实现了高效的稀疏线性代数运算,并支持自动微分。
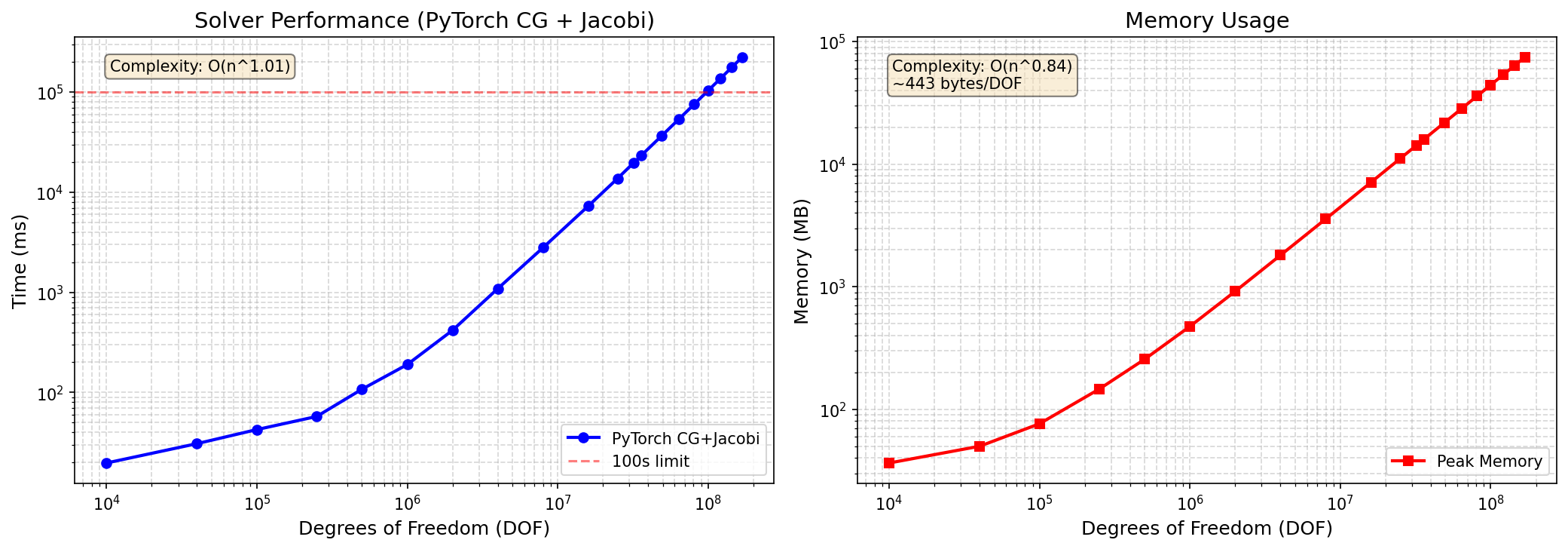
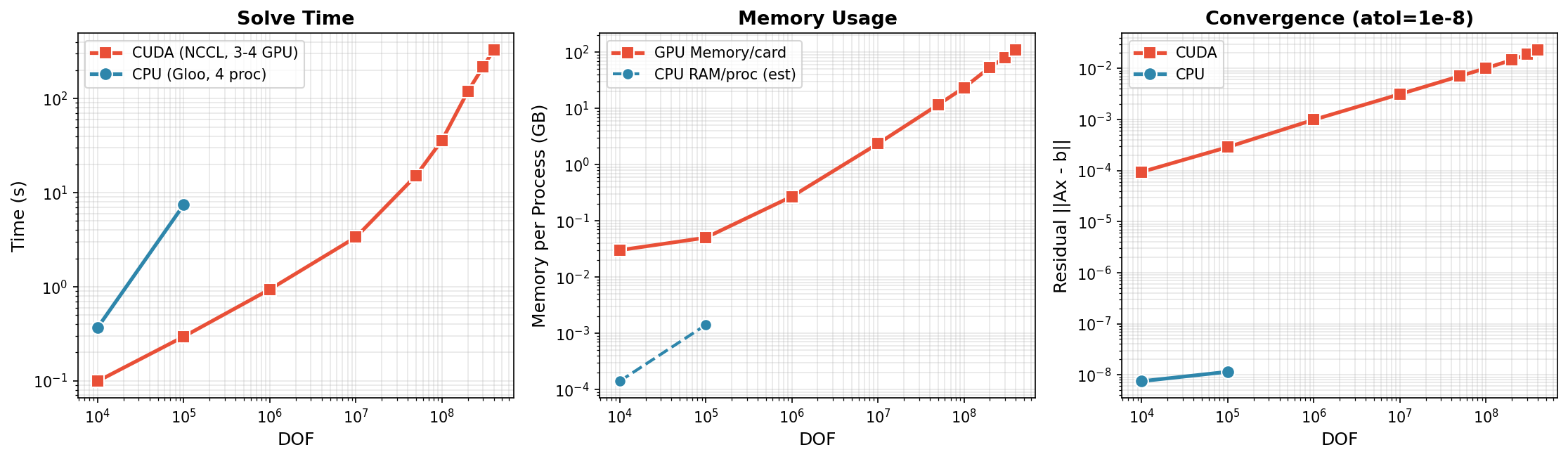
- 实验结果表明,torch-sla在3个GPU上实现了4亿自由度的线性求解,显著提升了计算效率和内存使用效率。
📝 摘要(中文)
工业科学计算通常使用稀疏矩阵表示非结构化数据,如有限元网格、图和点云。本文提出了torch-sla,这是一个开源的PyTorch库,支持GPU加速、可扩展且可微分的稀疏线性代数运算。该库解决了三个基本挑战:1)稀疏线性求解、非线性求解(牛顿法、皮卡德法、安德森法)和特征值计算的GPU加速;2)通过领域分解和halo交换实现多GPU扩展,达到在3个GPU上进行4亿自由度线性求解;3)基于伴随的微分计算,达到$ ext{O}(1)$的计算图节点和$ ext{O}( ext{nnz})$的内存使用,与求解迭代无关。torch-sla支持多种后端(SciPy、cuDSS、PyTorch原生),并与PyTorch的自动微分无缝集成,便于进行端到端的可微分模拟。
🔬 方法详解
问题定义:本文旨在解决稀疏线性代数计算中的效率问题,特别是在GPU加速和多GPU扩展方面的挑战。现有方法在处理大规模稀疏矩阵时,往往面临计算速度慢和内存使用不合理的问题。
核心思路:torch-sla通过结合GPU加速、领域分解和伴随微分技术,提供了一种高效的稀疏线性代数求解方案。该设计旨在提高计算速度,同时降低内存消耗,使得大规模科学计算变得可行。
技术框架:torch-sla的整体架构包括多个模块:稀疏线性求解模块、非线性求解模块、特征值计算模块,以及与PyTorch自动微分的集成。通过这些模块,用户可以方便地进行高效的稀疏线性代数运算。
关键创新:torch-sla的主要创新在于实现了基于伴随的微分计算,能够在求解过程中保持$ ext{O}(1)$的计算图节点和$ ext{O}( ext{nnz})$的内存使用,这一特性与传统方法相比具有显著优势。
关键设计:在实现过程中,torch-sla采用了领域分解和halo交换技术,以支持多GPU的高效计算。此外,库支持多种后端,用户可以根据需求选择合适的计算平台。
🖼️ 关键图片
📊 实验亮点
实验结果显示,torch-sla在3个GPU上成功实现了4亿自由度的线性求解,显著提高了计算效率。与传统方法相比,内存使用效率降低至$ ext{O}( ext{nnz})$,并且计算图节点数保持在$ ext{O}(1)$,展示了其在大规模稀疏线性代数计算中的优势。
🎯 应用场景
torch-sla在科学计算、工程模拟和机器学习等领域具有广泛的应用潜力。其高效的稀疏线性代数求解能力可以加速大规模数据处理,提升模型训练和推理的效率,特别是在需要处理复杂结构数据的场景中,具有重要的实际价值。
📄 摘要(原文)
Industrial scientific computing predominantly uses sparse matrices to represent unstructured data -- finite element meshes, graphs, point clouds. We present \torchsla{}, an open-source PyTorch library that enables GPU-accelerated, scalable, and differentiable sparse linear algebra. The library addresses three fundamental challenges: (1) GPU acceleration for sparse linear solves, nonlinear solves (Newton, Picard, Anderson), and eigenvalue computation; (2) Multi-GPU scaling via domain decomposition with halo exchange, reaching \textbf{400 million DOF linear solve on 3 GPUs}; and (3) Adjoint-based differentiation} achieving $\mathcal{O}(1)$ computational graph nodes (for autograd) and $\mathcal{O}(\text{nnz})$ memory -- independent of solver iterations. \torchsla{} supports multiple backends (SciPy, cuDSS, PyTorch-native) and seamlessly integrates with PyTorch autograd for end-to-end differentiable simulations. Code is available at https://github.com/walkerchi/torch-sla.