LifeAgentBench: A Multi-dimensional Benchmark and Agent for Personal Health Assistants in Digital Health
作者: Ye Tian, Zihao Wang, Onat Gungor, Xiaoran Fan, Tajana Rosing
分类: cs.AI
发布日期: 2026-01-20
💡 一句话要点
提出LifeAgentBench,用于评估和提升数字健康中个人健康助手的能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 数字健康 大型语言模型 基准测试 健康助手 多步推理
📋 核心要点
- 现有LLM在个性化数字健康支持方面能力不足,缺乏系统性的评估基准。
- 提出LifeAgentBench基准测试LLM在长期、跨维度健康生活方式推理方面的能力。
- 设计LifeAgent代理,通过多步证据检索和确定性聚合,显著提升了健康助手性能。
📝 摘要(中文)
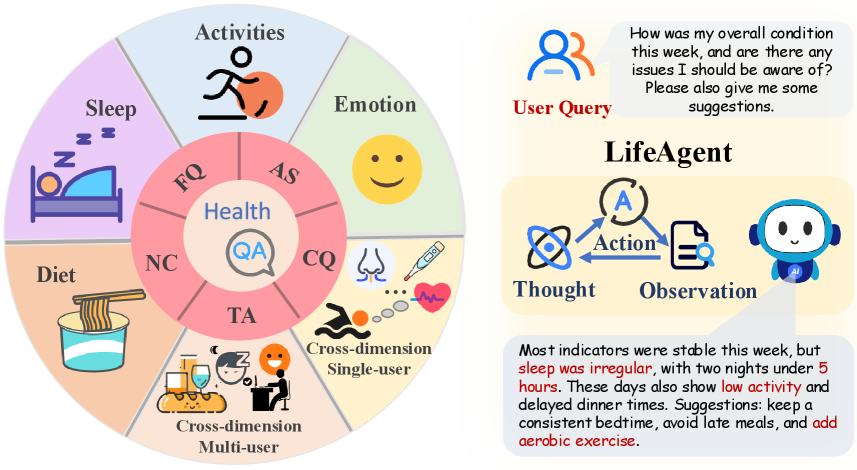
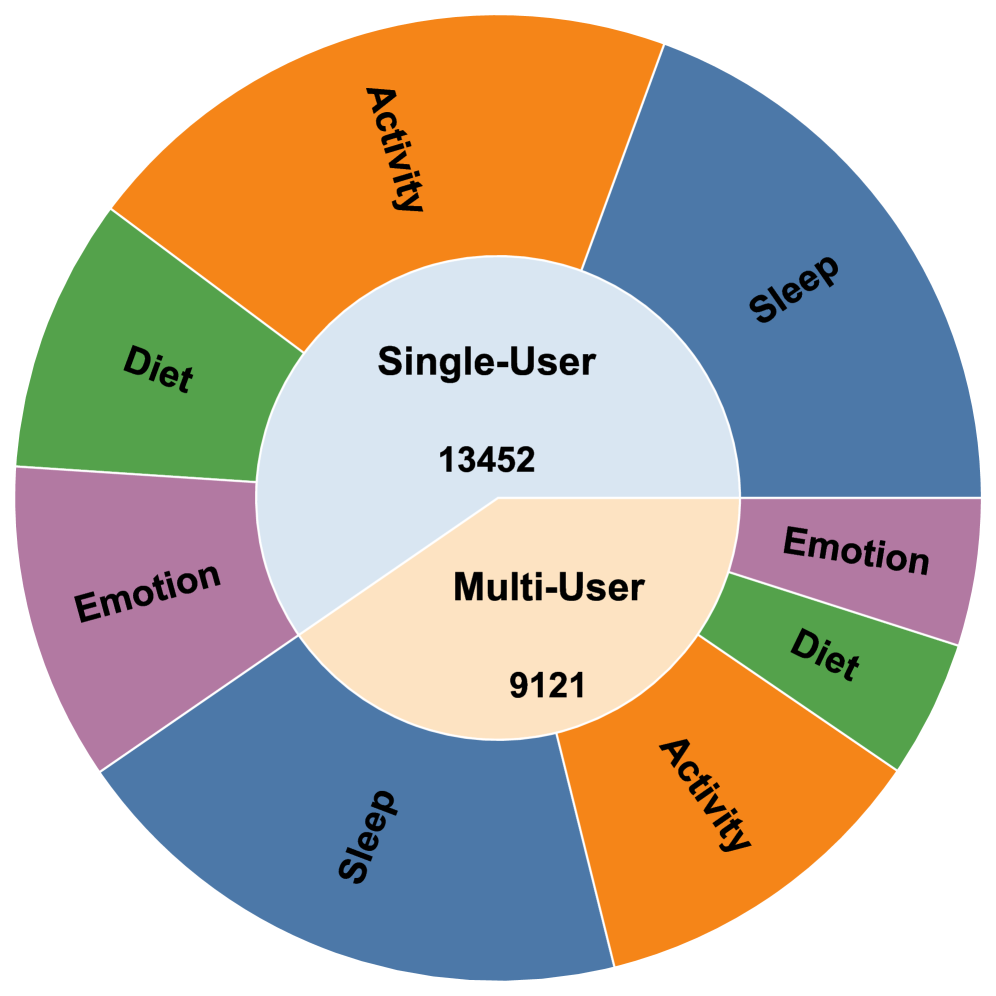
本文提出了LifeAgentBench,一个大规模QA基准,用于评估长期、跨维度和多用户的健康生活方式推理。该基准包含22573个问题,涵盖从基本检索到复杂推理。同时,发布了一个可扩展的基准构建流程和一个标准化的评估协议,以实现对基于LLM的健康助手的可靠和可扩展的评估。对11个领先的LLM在LifeAgentBench上进行了系统评估,识别了长期聚合和跨维度推理的关键瓶颈。受此启发,提出了LifeAgent,一个强大的健康助手基线代理,它集成了多步证据检索和确定性聚合,与两个广泛使用的基线相比,取得了显著的改进。案例研究进一步证明了其在现实生活场景中的潜力。该基准已公开发布。
🔬 方法详解
问题定义:现有的大语言模型(LLM)在处理个性化数字健康支持时,面临着长期、跨维度推理的挑战。具体来说,需要模型能够整合用户长期积累的异构生活方式数据,并进行复杂的推理,以提供有针对性的健康建议。现有的方法缺乏系统性的评估基准,难以准确衡量LLM在此场景下的能力,同时也缺乏有效的模型架构来应对这些挑战。
核心思路:本文的核心思路是构建一个大规模的基准测试集LifeAgentBench,用于全面评估LLM在个性化健康助手方面的能力。同时,基于评估结果,设计一个名为LifeAgent的代理,该代理通过多步证据检索和确定性聚合,能够更好地处理长期和跨维度的数据,从而提升健康助手的性能。
技术框架:LifeAgentBench包含一个可扩展的基准构建流程和一个标准化的评估协议。LifeAgent代理主要包含以下几个模块:1) 数据收集模块,负责收集用户的健康生活方式数据;2) 证据检索模块,根据用户的问题,从数据中检索相关的证据;3) 确定性聚合模块,将检索到的证据进行整合,生成最终的答案。
关键创新:LifeAgent的关键创新在于其多步证据检索和确定性聚合机制。传统方法通常直接使用LLM进行推理,容易受到噪声数据的干扰。LifeAgent通过多步检索,可以更准确地找到相关的证据,并通过确定性聚合,避免了LLM的幻觉问题,从而提高了答案的准确性和可靠性。
关键设计:LifeAgent使用了基于知识图谱的证据检索方法,通过构建用户健康知识图谱,可以更高效地检索相关的证据。在确定性聚合方面,使用了基于规则的聚合方法,根据不同的问题类型,设计不同的聚合规则,以确保答案的准确性。
🖼️ 关键图片
📊 实验亮点
在LifeAgentBench上的实验结果表明,LifeAgent代理显著优于现有的基线方法。例如,与两个广泛使用的基线相比,LifeAgent在准确率方面取得了显著的提升。案例研究也表明,LifeAgent在现实生活场景中具有很大的应用潜力。
🎯 应用场景
该研究成果可应用于开发更智能、更个性化的数字健康助手,帮助用户更好地管理自己的健康。例如,可以根据用户的饮食、运动、睡眠等数据,提供个性化的健康建议和风险评估。此外,该基准测试集也可以促进LLM在医疗健康领域的应用研究。
📄 摘要(原文)
Personalized digital health support requires long-horizon, cross-dimensional reasoning over heterogeneous lifestyle signals, and recent advances in mobile sensing and large language models (LLMs) make such support increasingly feasible. However, the capabilities of current LLMs in this setting remain unclear due to the lack of systematic benchmarks. In this paper, we introduce LifeAgentBench, a large-scale QA benchmark for long-horizon, cross-dimensional, and multi-user lifestyle health reasoning, containing 22,573 questions spanning from basic retrieval to complex reasoning. We release an extensible benchmark construction pipeline and a standardized evaluation protocol to enable reliable and scalable assessment of LLM-based health assistants. We then systematically evaluate 11 leading LLMs on LifeAgentBench and identify key bottlenecks in long-horizon aggregation and cross-dimensional reasoning. Motivated by these findings, we propose LifeAgent as a strong baseline agent for health assistant that integrates multi-step evidence retrieval with deterministic aggregation, achieving significant improvements compared with two widely used baselines. Case studies further demonstrate its potential in realistic daily-life scenarios. The benchmark is publicly available at https://anonymous.4open.science/r/LifeAgentBench-CE7B.