DARC: Decoupled Asymmetric Reasoning Curriculum for LLM Evolution
作者: Shengda Fan, Xuyan Ye, Yankai Lin
分类: cs.AI, cs.CL
发布日期: 2026-01-20 (更新: 2026-01-21)
🔗 代码/项目: GITHUB
💡 一句话要点
DARC:解耦非对称推理课程,提升大型语言模型自进化能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 自博弈 自蒸馏 推理 课程学习
📋 核心要点
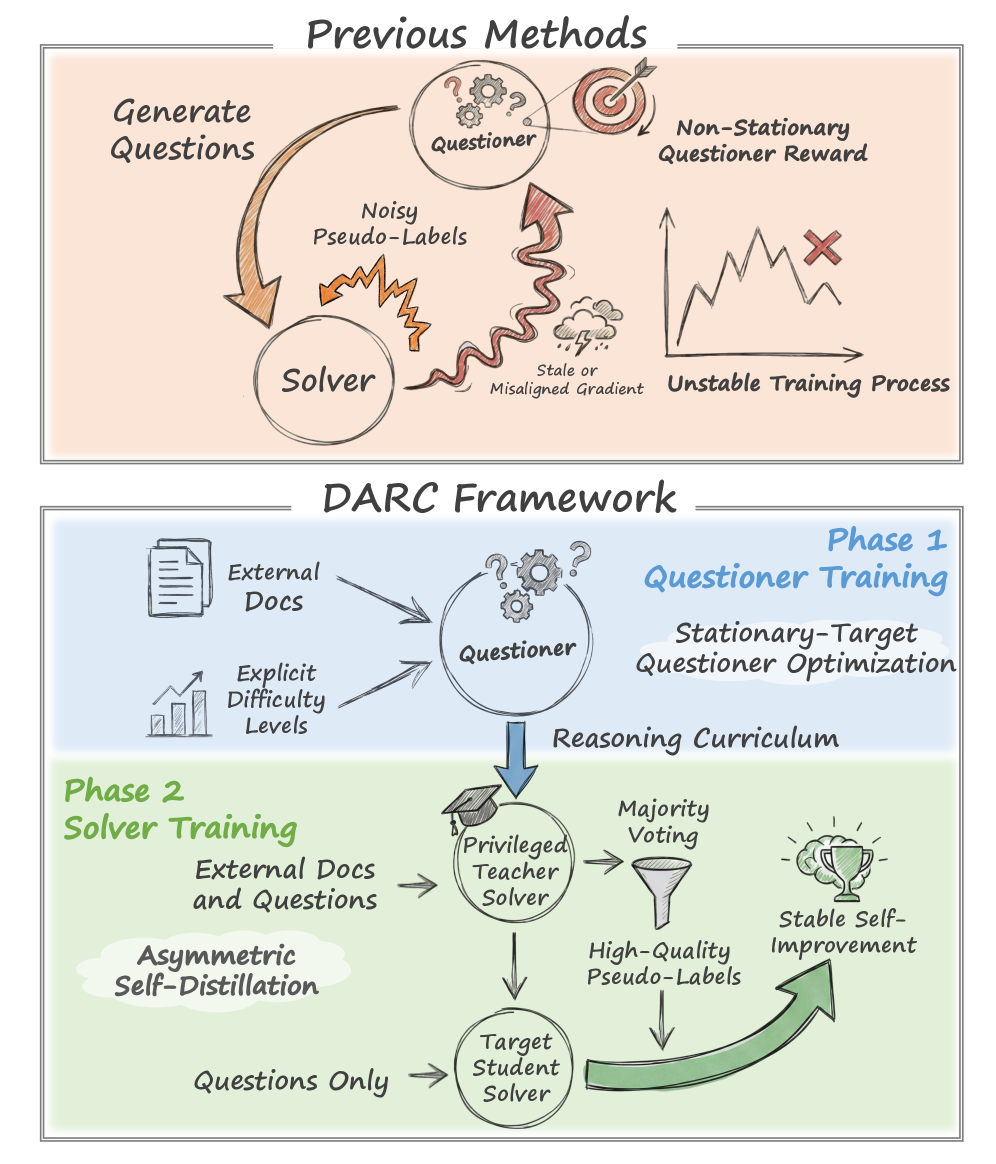
- 现有自博弈框架在训练大型语言模型时,存在优化不稳定问题,源于奖励反馈的非平稳性和自生成伪标签的自举误差。
- DARC框架通过解耦提问者和求解器的训练过程,并引入非对称自蒸馏机制,有效缓解了优化不稳定性问题。
- 实验结果表明,DARC在多个推理基准测试中显著提升了模型性能,且无需人工标注即可达到接近完全监督模型的水平。
📝 摘要(中文)
本文提出了一种名为DARC(解耦非对称推理课程)的两阶段框架,旨在稳定大型语言模型的自进化过程。现有的自博弈框架由于提问者的求解器依赖奖励反馈导致的非平稳目标,以及求解器使用自生成伪标签进行监督时的自举误差,常常面临优化不稳定的问题。DARC首先训练提问者,使其能够根据显式的难度级别和外部语料库合成难度校准的问题。然后,DARC采用非对称自蒸馏机制训练求解器,其中具有文档增强的教师模型生成高质量的伪标签,以监督缺乏文档访问的学生求解器。实验结果表明,DARC具有模型无关性,在九个推理基准测试和三个骨干模型上平均提升了10.9个点。此外,DARC始终优于所有基线,并且在不依赖人工标注的情况下接近完全监督模型的性能。
🔬 方法详解
问题定义:现有基于自博弈的大型语言模型训练方法,由于提问者依赖求解器的反馈来调整问题难度,导致训练目标不稳定。同时,求解器使用自身生成的伪标签进行训练,会引入自举误差,进一步加剧训练的不稳定性。因此,如何稳定自博弈框架下的LLM训练是一个关键问题。
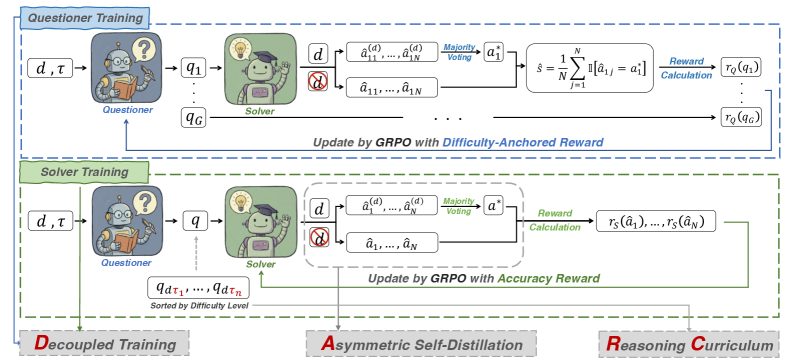
核心思路:DARC的核心思路是将提问者和求解器的训练解耦,并采用非对称的自蒸馏方法。具体来说,首先独立训练提问者,使其能够生成具有不同难度级别的问题。然后,利用一个文档增强的教师模型生成高质量的伪标签,指导一个不具备文档访问权限的学生模型进行学习。这种非对称的蒸馏方式可以有效减少自举误差,并提升模型的泛化能力。
技术框架:DARC框架包含两个主要阶段:1) 难度校准的提问者训练:利用显式的难度级别和外部语料库,训练提问者生成不同难度的问题。2) 非对称自蒸馏的求解器训练:使用文档增强的教师模型生成伪标签,监督学生求解器的训练。教师模型可以访问额外的文档信息,从而生成更准确的标签。
关键创新:DARC的关键创新在于解耦了提问者和求解器的训练过程,并引入了非对称自蒸馏机制。这种解耦方式避免了提问者训练对求解器反馈的依赖,从而稳定了训练目标。非对称自蒸馏则利用了更强的教师模型来生成高质量的伪标签,减少了自举误差。
关键设计:在提问者训练阶段,使用难度级别作为条件,控制生成问题的难度。在求解器训练阶段,教师模型通过检索外部文档来增强其推理能力,从而生成更准确的伪标签。损失函数采用标准的交叉熵损失,用于监督学生模型的训练。学生模型不具备文档访问权限,旨在学习教师模型的推理能力,而不是简单地记忆文档内容。
🖼️ 关键图片
📊 实验亮点
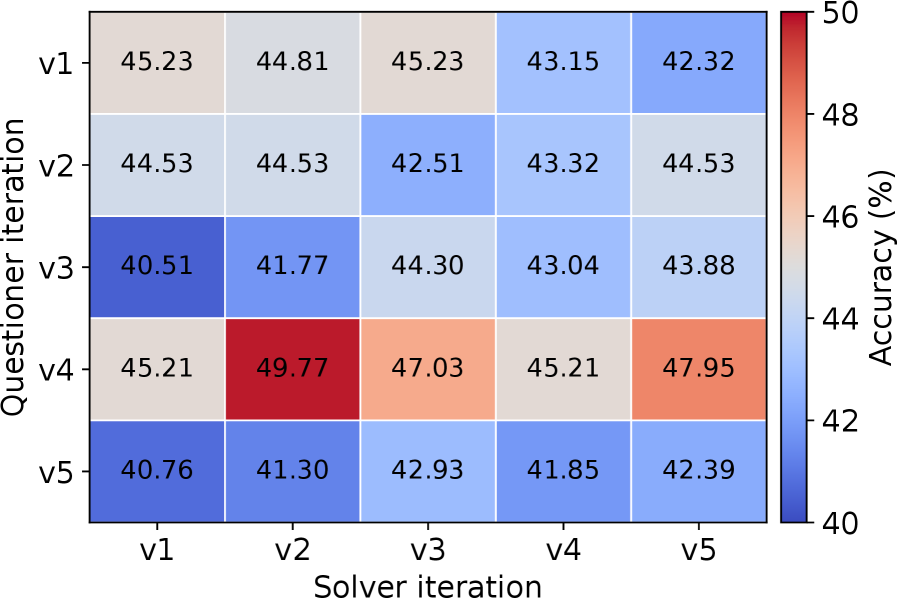
DARC在九个推理基准测试和三个骨干模型上取得了显著的性能提升,平均提升幅度达到10.9个点。DARC的性能始终优于所有基线方法,并且在不依赖人工标注的情况下,能够达到接近完全监督模型的性能水平。这些实验结果充分证明了DARC框架的有效性和优越性。
🎯 应用场景
DARC框架可以应用于各种需要大型语言模型进行推理和决策的任务中,例如问答系统、文本摘要、代码生成等。该方法能够提升模型的自学习能力和泛化性能,降低对人工标注数据的依赖,具有重要的实际应用价值和广阔的未来发展前景。
📄 摘要(原文)
Self-play with large language models has emerged as a promising paradigm for achieving self-improving artificial intelligence. However, existing self-play frameworks often suffer from optimization instability, due to (i) non-stationary objectives induced by solver-dependent reward feedback for the Questioner, and (ii) bootstrapping errors from self-generated pseudo-labels used to supervise the Solver. To mitigate these challenges, we introduce DARC (Decoupled Asymmetric Reasoning Curriculum), a two-stage framework that stabilizes the self-evolution process. First, we train the Questioner to synthesize difficulty-calibrated questions, conditioned on explicit difficulty levels and external corpora. Second, we train the Solver with an asymmetric self-distillation mechanism, where a document-augmented teacher generates high-quality pseudo-labels to supervise the student Solver that lacks document access. Empirical results demonstrate that DARC is model-agnostic, yielding an average improvement of 10.9 points across nine reasoning benchmarks and three backbone models. Moreover, DARC consistently outperforms all baselines and approaches the performance of fully supervised models without relying on human annotations. The code is available at https://github.com/RUCBM/DARC.