Why Does the LLM Stop Computing: An Empirical Study of User-Reported Failures in Open-Source LLMs
作者: Guangba Yu, Zirui Wang, Yujie Huang, Renyi Zhong, Yuedong Zhong, Yilun Wang, Michael R. Lyu
分类: cs.SE, cs.AI, cs.DC
发布日期: 2026-01-20
💡 一句话要点
大规模实证研究开源LLM部署失败问题,揭示系统性瓶颈与解决方案。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 开源LLM 部署可靠性 实证研究 故障分析
📋 核心要点
- 开源LLM的普及使得用户可以本地部署和微调模型,但也带来了部署可靠性的挑战,现有研究对此关注不足。
- 该研究通过分析大量用户报告的失败案例,揭示了开源LLM部署中可靠性瓶颈从模型算法转移到系统部署的转变。
- 研究识别了诊断差异、系统同质性和生命周期升级三个关键现象,为提升开源LLM的可靠性提供了指导。
📝 摘要(中文)
本文针对开源大型语言模型(LLM)在用户本地部署时面临的可靠性问题,进行了首次大规模实证研究,分析了来自DeepSeek、Llama和Qwen生态系统的705个真实世界失败案例。研究揭示了与黑盒API调用不同,白盒编排将可靠性瓶颈从模型算法缺陷转移到部署堆栈的系统性脆弱性。研究发现了三个关键现象:(1)诊断差异:运行时崩溃预示着基础设施问题,而功能错误则表明内部tokenizer存在缺陷。(2)系统同质性:根本原因在不同系列中趋同,证实可靠性障碍是共享生态系统固有的,而非特定架构。(3)生命周期升级:障碍从微调期间的固有配置问题升级到推理期间的复合环境不兼容问题。研究提供了一个公开可用的数据集,并为提高LLM领域的可靠性提供了可操作的指导。
🔬 方法详解
问题定义:现有开源LLM的部署可靠性是一个关键问题,用户在本地部署和微调这些模型时,经常遇到各种失败情况。与使用API不同,用户需要自行管理整个部署堆栈,这使得可靠性问题更加复杂和难以诊断。现有的研究主要集中在模型算法的缺陷上,而忽略了部署环境和系统配置等因素对可靠性的影响。
核心思路:本文的核心思路是通过大规模实证研究,分析用户报告的真实失败案例,从而揭示开源LLM部署中常见的可靠性问题及其根本原因。通过对这些失败案例进行分类和分析,研究人员可以识别出关键的瓶颈和模式,并为提高部署可靠性提供有针对性的解决方案。
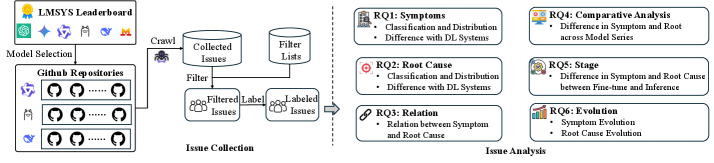
技术框架:该研究的技术框架主要包括以下几个步骤:1) 数据收集:收集来自DeepSeek、Llama和Qwen等开源LLM生态系统的用户报告的失败案例。2) 数据清洗和预处理:对收集到的数据进行清洗和预处理,去除噪声和冗余信息。3) 失败案例分类:根据失败的原因和表现,将失败案例分为不同的类别。4) 根本原因分析:对每个类别的失败案例进行深入分析,找出其根本原因。5) 模式识别:识别不同类别失败案例之间的关联和模式。6) 解决方案建议:根据分析结果,提出有针对性的解决方案,以提高开源LLM的部署可靠性。
关键创新:该研究的关键创新在于:1) 首次对开源LLM的部署可靠性问题进行了大规模实证研究。2) 揭示了可靠性瓶颈从模型算法转移到系统部署的转变。3) 识别了诊断差异、系统同质性和生命周期升级三个关键现象。4) 提供了一个公开可用的数据集,为后续研究提供了基础。
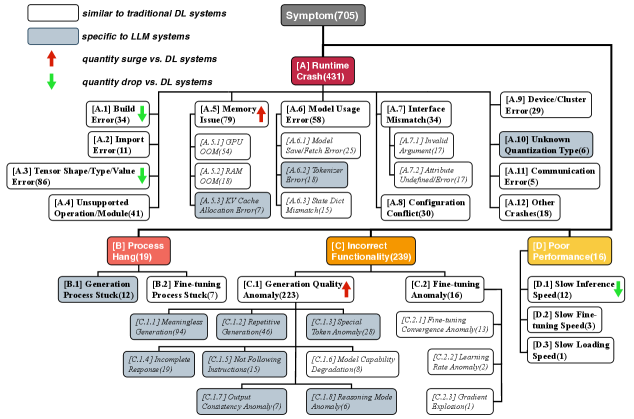
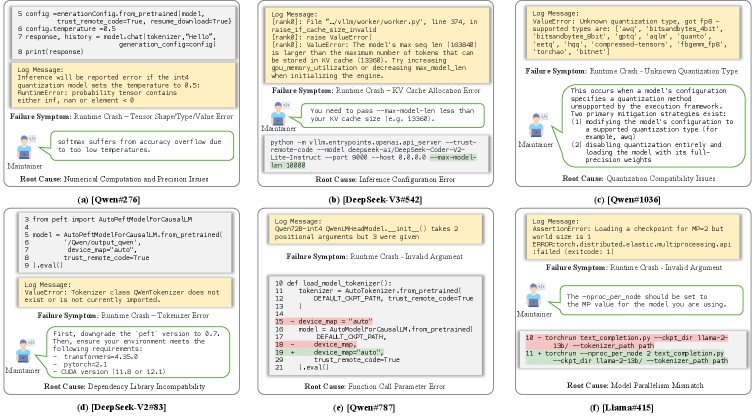
关键设计:研究中没有涉及具体的模型参数设置或网络结构设计。关键在于对用户报告的错误日志进行分析,并根据错误类型进行分类。例如,通过区分运行时崩溃和功能错误,可以判断问题是出在基础设施层面还是模型tokenizer层面。此外,研究还关注了不同LLM系列之间的共性问题,以及在微调和推理阶段出现的不同类型的错误。
🖼️ 关键图片
📊 实验亮点
研究分析了705个真实世界的失败案例,揭示了开源LLM部署中的系统性问题。研究发现,运行时崩溃通常与基础设施问题相关,而功能错误则与tokenizer缺陷有关。此外,研究还发现不同LLM系列之间存在系统同质性,表明可靠性问题是整个生态系统固有的。
🎯 应用场景
该研究成果可应用于提高开源LLM的部署可靠性,降低用户部署和维护成本。通过识别和解决常见的部署问题,可以加速开源LLM的普及和应用,促进人工智能技术的民主化。此外,该研究还可以为LLM的开发和优化提供反馈,帮助开发者设计更可靠的模型。
📄 摘要(原文)
The democratization of open-source Large Language Models (LLMs) allows users to fine-tune and deploy models on local infrastructure but exposes them to a First Mile deployment landscape. Unlike black-box API consumption, the reliability of user-managed orchestration remains a critical blind spot. To bridge this gap, we conduct the first large-scale empirical study of 705 real-world failures from the open-source DeepSeek, Llama, and Qwen ecosystems. Our analysis reveals a paradigm shift: white-box orchestration relocates the reliability bottleneck from model algorithmic defects to the systemic fragility of the deployment stack. We identify three key phenomena: (1) Diagnostic Divergence: runtime crashes distinctively signal infrastructure friction, whereas incorrect functionality serves as a signature for internal tokenizer defects. (2) Systemic Homogeneity: Root causes converge across divergent series, confirming reliability barriers are inherent to the shared ecosystem rather than specific architectures. (3) Lifecycle Escalation: Barriers escalate from intrinsic configuration struggles during fine-tuning to compounded environmental incompatibilities during inference. Supported by our publicly available dataset, these insights provide actionable guidance for enhancing the reliability of the LLM landscape.