Foundations of Global Consistency Checking with Noisy LLM Oracles
作者: Paul He, Elke Kirschbaum, Shiva Kasiviswanathan
分类: cs.AI
发布日期: 2026-01-20
备注: Under Review
💡 一句话要点
提出基于LLM的全局一致性检查框架,通过自适应分治算法高效检测并修复不一致性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 全局一致性 大型语言模型 事实核查 自适应分治 最小不一致子集
📋 核心要点
- 现有方法难以保证大规模自然语言事实集合的全局一致性,LLM判断存在噪声且成对检查不足。
- 提出自适应分治算法,通过识别最小不一致子集(MUS)并计算最小修复来解决全局一致性问题。
- 实验表明,该方法能高效检测和定位不一致性,为基于LLM的语言一致性验证提供可扩展框架。
📝 摘要(中文)
确保自然语言事实集合的全局一致性对于事实核查、摘要生成和知识库构建等任务至关重要。尽管大型语言模型(LLM)可以评估小规模事实子集的一致性,但它们的判断存在噪声,并且成对检查不足以保证全局一致性。本文形式化了这个问题,并证明在最坏情况下,验证全局一致性需要指数级的oracle查询。为了使该任务实用化,我们提出了一种自适应分治算法,该算法识别事实的最小不一致子集(MUS),并可选择通过命中集计算最小修复。我们的方法具有低阶多项式查询复杂度。使用合成和真实LLM oracle的实验表明,我们的方法能够有效地检测和定位不一致性,为基于LLM评估器的语言一致性验证提供了一个可扩展的框架。
🔬 方法详解
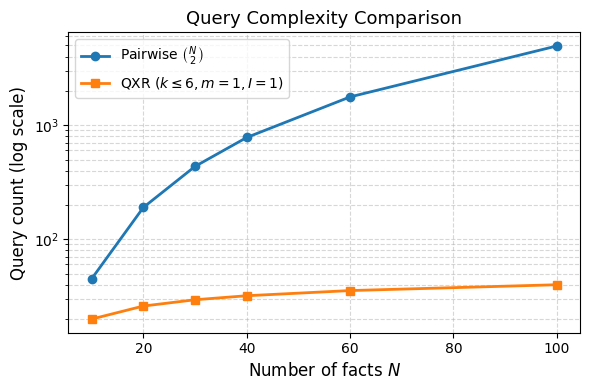
问题定义:论文旨在解决如何高效地验证大规模自然语言事实集合的全局一致性问题。现有方法,如成对一致性检查,无法保证全局一致性,并且当使用LLM作为一致性判断的oracle时,LLM的噪声会进一步加剧这个问题。直接验证全局一致性在最坏情况下需要指数级的查询复杂度,因此不具备实用性。
核心思路:论文的核心思路是采用自适应的分治策略。将大规模的事实集合分解为更小的子集,利用LLM oracle来检查这些子集的一致性。如果发现不一致的子集,则进一步分解,直到找到最小的不一致子集(MUS)。然后,可以通过计算命中集来找到修复这些不一致的最小修改。这种分治策略可以显著降低查询复杂度。
技术框架:整体框架包含以下几个主要阶段: 1. 初始化:将所有事实放入一个集合中。 2. 分治:将当前集合划分为更小的子集。 3. 一致性检查:使用LLM oracle检查子集的一致性。 4. MUS识别:如果子集不一致,则递归地分解该子集,直到找到最小的不一致子集(MUS)。 5. 修复(可选):计算MUS的命中集,以找到需要修改的最小事实集合,从而修复不一致性。
关键创新:该论文的关键创新在于提出了自适应分治算法,该算法能够有效地识别最小不一致子集(MUS),并可选地计算最小修复。与直接验证全局一致性或简单的成对检查相比,该方法具有更低的查询复杂度和更好的可扩展性。此外,该方法能够处理LLM oracle的噪声,并提供一种实用的全局一致性验证框架。
关键设计: 1. 自适应分治策略:根据LLM oracle的反馈动态地调整子集的大小,以平衡查询复杂度和检测精度。 2. 最小不一致子集(MUS)识别:使用递归分解的方法来找到最小的不一致子集,避免了不必要的查询。 3. 命中集计算:使用标准的命中集算法来找到需要修改的最小事实集合,从而修复不一致性。 4. LLM Oracle集成:该框架可以与各种LLM oracle集成,只需提供一个函数来判断给定事实子集的一致性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法能够有效地检测和定位不一致性,并且具有较低的查询复杂度。在合成数据集和真实数据集上,该方法都优于基线方法,能够以更少的查询次数找到更多的不一致性。具体的性能数据(例如,查询次数减少的百分比,检测到的不一致性数量的增加)未知,需要在论文中查找。
🎯 应用场景
该研究成果可应用于多个领域,包括:事实核查系统,用于验证新闻报道和在线信息的真实性;知识库构建,用于确保知识库中信息的全局一致性;自动摘要生成,用于生成一致且准确的摘要;以及对话系统,用于维护对话上下文的一致性。该方法能够提高信息的可信度和可靠性,并降低人工干预的需求。
📄 摘要(原文)
Ensuring that collections of natural-language facts are globally consistent is essential for tasks such as fact-checking, summarization, and knowledge base construction. While Large Language Models (LLMs) can assess the consistency of small subsets of facts, their judgments are noisy, and pairwise checks are insufficient to guarantee global coherence. We formalize this problem and show that verifying global consistency requires exponentially many oracle queries in the worst case. To make the task practical, we propose an adaptive divide-and-conquer algorithm that identifies minimal inconsistent subsets (MUSes) of facts and optionally computes minimal repairs through hitting-sets. Our approach has low-degree polynomial query complexity. Experiments with both synthetic and real LLM oracles show that our method efficiently detects and localizes inconsistencies, offering a scalable framework for linguistic consistency verification with LLM-based evaluators.