DSAEval: Evaluating Data Science Agents on a Wide Range of Real-World Data Science Problems
作者: Maojun Sun, Yifei Xie, Yue Wu, Ruijian Han, Binyan Jiang, Defeng Sun, Yancheng Yuan, Jian Huang
分类: cs.AI, cs.CL
发布日期: 2026-01-20
💡 一句话要点
DSAEval:提出一个真实世界数据科学问题评估基准,用于评估数据科学Agent的性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 数据科学Agent 评估基准 多模态学习 大型语言模型 真实世界数据 非结构化数据 迭代交互
📋 核心要点
- 现有数据科学Agent评估缺乏真实性,难以覆盖实际场景中多模态数据和迭代交互的复杂性。
- DSAEval基准通过引入多模态感知、多查询交互和多维度评估,更真实地模拟了现实世界的数据科学问题。
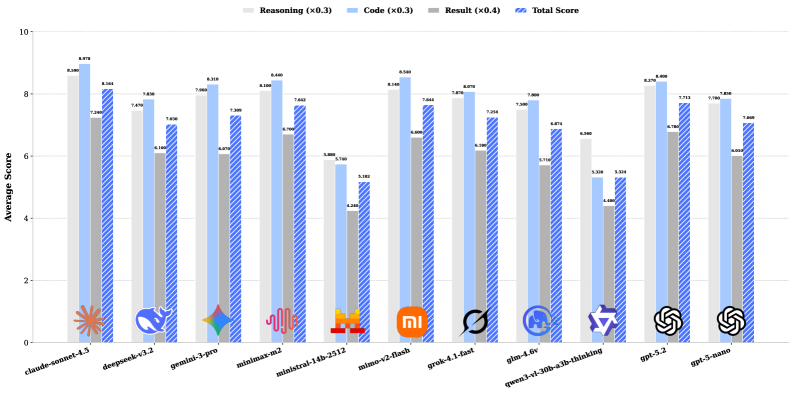
- 实验表明,现有Agent在非结构化数据处理方面仍有挑战,多模态感知能显著提升视觉任务性能。
📝 摘要(中文)
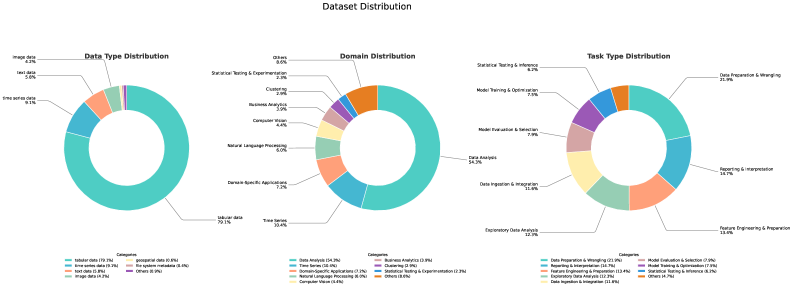
本文提出了DSAEval,一个用于评估基于大型语言模型(LLM)的数据科学Agent的基准。该基准包含641个源于285个不同数据集的真实世界数据科学问题,涵盖结构化和非结构化数据(如视觉和文本)。DSAEval具有三个显著特征:(1)多模态环境感知,使Agent能够解释来自文本和视觉等多种模态的观测;(2)多查询交互,反映了真实世界数据科学项目的迭代和累积性质;(3)多维度评估,提供对推理、代码和结果的全面评估。通过DSAEval对11个先进的Agent LLM进行了系统评估,结果表明Claude-Sonnet-4.5总体性能最强,GPT-5.2效率最高,MiMo-V2-Flash性价比最高。多模态感知持续提高了视觉相关任务的性能,增益范围为2.04%至11.30%。总体而言,当前的数据科学Agent在结构化数据和常规数据分析工作流程中表现良好,但在非结构化领域仍然存在重大挑战。最后,本文提供了关键见解,并概述了未来研究方向,以推进数据科学Agent的发展。
🔬 方法详解
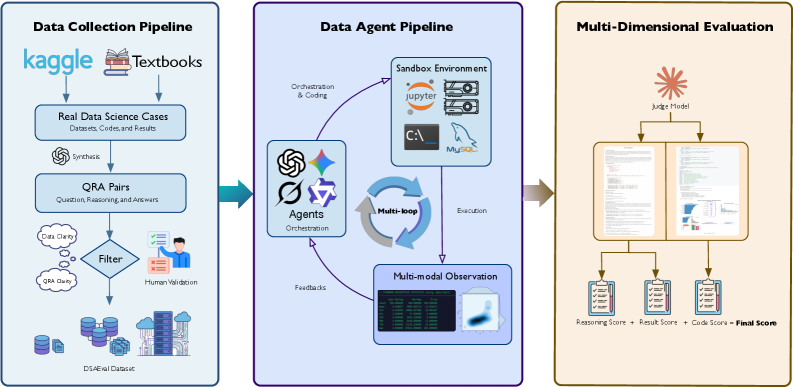
问题定义:现有数据科学Agent的评估方法难以捕捉真实世界数据科学问题的复杂性,例如多模态数据处理、迭代式交互以及缺乏标准答案等。现有的评估方法往往集中在结构化数据和预定义任务上,忽略了非结构化数据(如图像和文本)的处理能力,以及Agent在复杂、开放式问题中的推理和决策能力。因此,需要一个更全面、更真实的评估基准来推动数据科学Agent的发展。
核心思路:DSAEval的核心思路是构建一个更贴近真实世界数据科学场景的评估基准。通过引入多模态环境感知、多查询交互和多维度评估,DSAEval能够更全面地评估Agent在处理复杂数据、进行迭代式分析和生成高质量结果方面的能力。这种设计旨在弥合现有评估方法与实际应用之间的差距,从而推动数据科学Agent的进步。
技术框架:DSAEval基准包含以下几个主要组成部分: 1. 数据集:包含285个不同的真实世界数据集,涵盖结构化和非结构化数据(如视觉和文本)。 2. 任务:定义了641个数据科学问题,这些问题需要Agent进行数据分析、建模和推理。 3. 环境:提供多模态环境感知能力,允许Agent从文本和视觉等多种模态获取信息。 4. 交互:支持多查询交互,模拟真实世界数据科学项目的迭代和累积性质。 5. 评估:采用多维度评估方法,从推理、代码和结果三个方面对Agent进行全面评估。
关键创新:DSAEval的关键创新在于其对真实世界数据科学问题的模拟程度。与现有基准相比,DSAEval更注重多模态数据的处理、迭代式交互以及对结果的全面评估。这种设计使得DSAEval能够更准确地反映Agent在实际应用中的性能,从而为Agent的开发和改进提供更有价值的反馈。
关键设计:DSAEval的关键设计包括: 1. 多模态环境感知:Agent需要能够解析和理解来自不同模态(如文本和图像)的信息,这需要Agent具备强大的多模态理解能力。 2. 多查询交互:Agent需要能够根据之前的查询结果进行迭代式分析,这需要Agent具备记忆和推理能力。 3. 多维度评估:DSAEval从推理、代码和结果三个方面对Agent进行评估,这需要定义合适的评估指标和方法。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Claude-Sonnet-4.5在DSAEval上取得了最佳的总体性能,GPT-5.2在效率方面表现突出,而MiMo-V2-Flash则具有最高的性价比。此外,多模态感知显著提高了Agent在视觉相关任务上的性能,提升幅度在2.04%到11.30%之间。这些结果表明,当前的数据科学Agent在结构化数据处理方面表现良好,但在非结构化数据处理方面仍有很大的提升空间。
🎯 应用场景
DSAEval可用于评估和比较不同数据科学Agent的性能,指导Agent的开发和改进。该基准能够推动Agent在金融分析、医疗诊断、市场预测等领域的应用,提高数据驱动决策的效率和质量。未来,DSAEval可以扩展到更多领域和任务,成为数据科学Agent研究的重要工具。
📄 摘要(原文)
Recent LLM-based data agents aim to automate data science tasks ranging from data analysis to deep learning. However, the open-ended nature of real-world data science problems, which often span multiple taxonomies and lack standard answers, poses a significant challenge for evaluation. To address this, we introduce DSAEval, a benchmark comprising 641 real-world data science problems grounded in 285 diverse datasets, covering both structured and unstructured data (e.g., vision and text). DSAEval incorporates three distinctive features: (1) Multimodal Environment Perception, which enables agents to interpret observations from multiple modalities including text and vision; (2) Multi-Query Interactions, which mirror the iterative and cumulative nature of real-world data science projects; and (3) Multi-Dimensional Evaluation, which provides a holistic assessment across reasoning, code, and results. We systematically evaluate 11 advanced agentic LLMs using DSAEval. Our results show that Claude-Sonnet-4.5 achieves the strongest overall performance, GPT-5.2 is the most efficient, and MiMo-V2-Flash is the most cost-effective. We further demonstrate that multimodal perception consistently improves performance on vision-related tasks, with gains ranging from 2.04% to 11.30%. Overall, while current data science agents perform well on structured data and routine data anlysis workflows, substantial challenges remain in unstructured domains. Finally, we offer critical insights and outline future research directions to advance the development of data science agents.