The Geometry of Thought: How Scale Restructures Reasoning In Large Language Models
作者: Samuel Cyrenius Anderson
分类: cs.AI, cs.LG
发布日期: 2026-01-19
备注: 34 pages, 10 figures
💡 一句话要点
揭示大语言模型推理的几何结构:规模扩展重塑推理方式
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 推理机制 几何结构 思维链 神经缩放定律
📋 核心要点
- 现有方法未能充分理解大语言模型规模扩展对推理能力的具体影响,以及不同领域推理方式的差异。
- 论文核心思想是通过分析大语言模型在不同领域和规模下的思维链轨迹,揭示推理过程的几何结构。
- 实验结果表明,不同领域的推理方式存在显著差异,并提出神经推理算子,在法律推理任务上取得了较好的预测效果。
📝 摘要(中文)
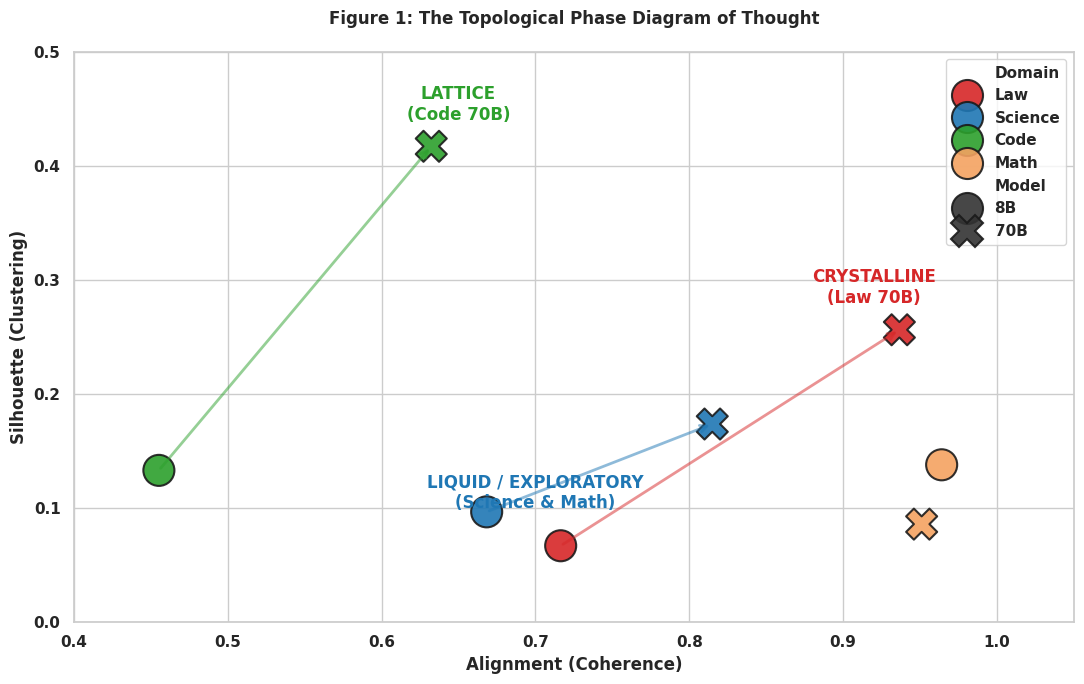
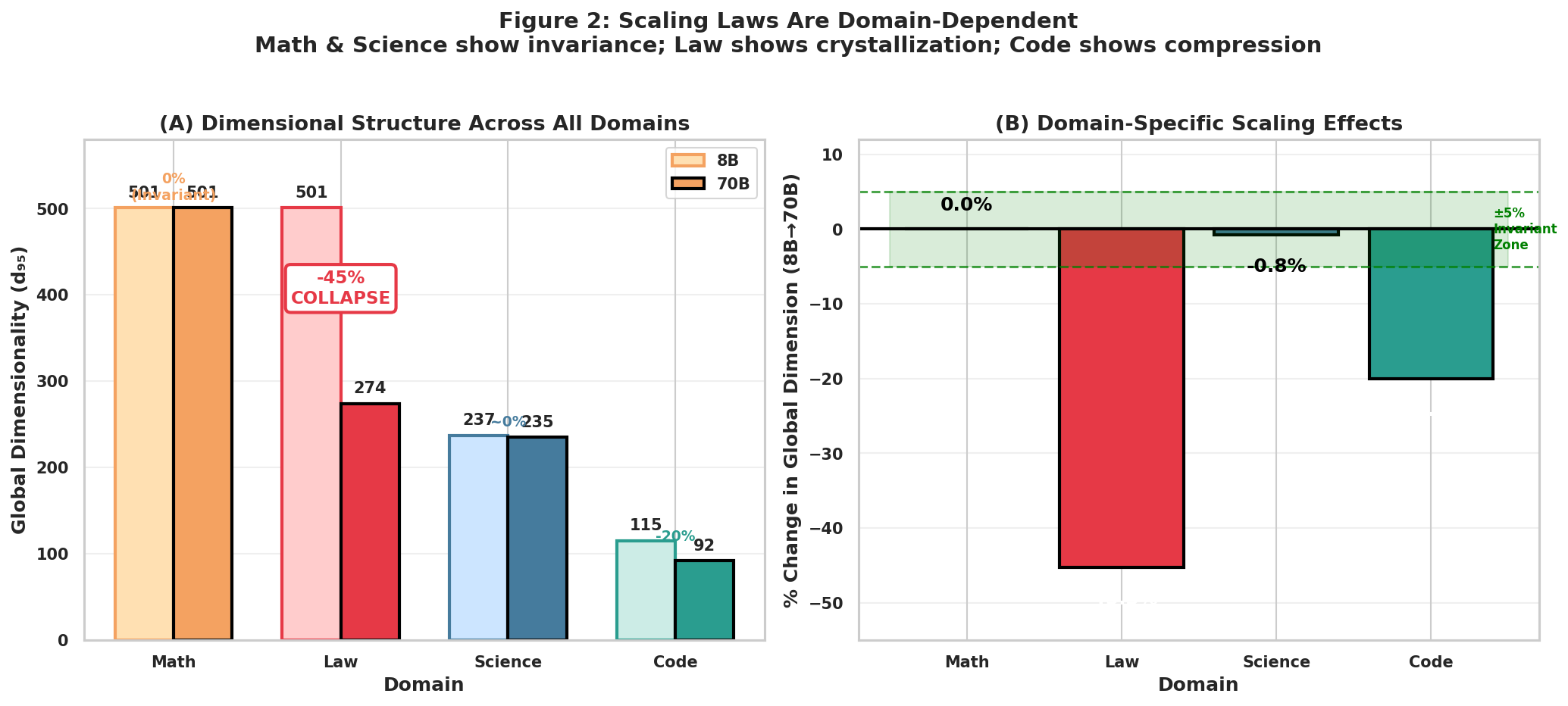
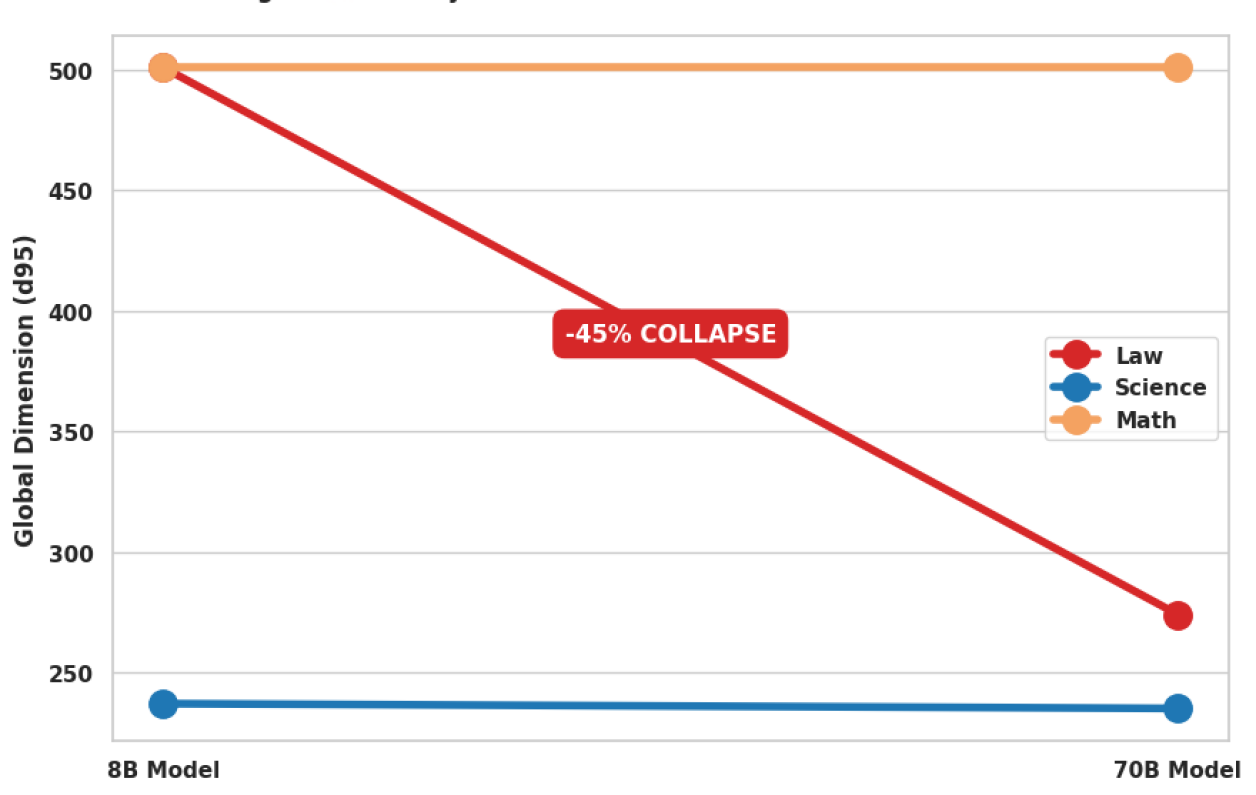
本文研究表明,模型规模的扩展并非均匀地提升推理能力,而是重塑了推理方式。通过分析四个领域(法律、科学、代码、数学)和两种规模(8B、70B参数)下超过25000条思维链轨迹,发现神经缩放定律触发了特定领域的相变,而非统一的能力提升。法律推理经历了“结晶化”,表征维度降低45%,轨迹对齐度增加31%,流形解缠增加10倍。科学和数学推理保持“液态”,几何结构在参数增加9倍的情况下保持不变。代码推理形成了一个离散的战略模式“晶格”。这种几何结构可以预测可学习性。本文引入了神经推理算子,即从初始隐藏状态到最终隐藏状态的学习映射。在结晶化的法律推理中,该算子通过探针解码在保留任务上实现了63.6%的准确率,无需遍历中间状态即可预测推理终点。此外,本文还发现了一种通用的振荡特征(相干性约为-0.4),在不同领域和规模下保持不变,表明注意力机制和前馈层通过相反的动态驱动推理。这些发现表明,推理的成本并非由任务难度决定,而是由流形几何结构决定,从而为拓扑结构允许的推理加速提供了一个蓝图。
🔬 方法详解
问题定义:现有的大语言模型研究主要关注模型规模与性能之间的关系,但缺乏对模型内部推理机制的深入理解。特别是,不同领域的推理方式可能存在差异,而现有方法未能有效捕捉和利用这些差异。此外,如何加速推理过程,降低计算成本也是一个重要的研究问题。
核心思路:本文的核心思路是通过几何学的视角来理解大语言模型的推理过程。作者认为,推理过程可以被视为在隐藏状态空间中的轨迹,而不同领域的推理方式对应于不同的几何结构。通过分析这些几何结构,可以更好地理解模型的推理机制,并设计更有效的推理方法。
技术框架:本文的技术框架主要包括以下几个步骤:1) 收集不同领域和规模下的大语言模型的思维链轨迹;2) 使用降维、对齐等方法分析轨迹的几何结构;3) 引入神经推理算子,学习从初始隐藏状态到最终隐藏状态的映射;4) 通过实验验证几何结构与可学习性之间的关系,并评估神经推理算子的性能。
关键创新:本文最重要的技术创新点在于将几何学引入到大语言模型的推理研究中。通过分析推理轨迹的几何结构,作者发现了不同领域的推理方式存在显著差异,并提出了神经推理算子,实现了在特定领域(如法律推理)的推理加速。此外,发现的通用振荡特征也为理解模型的内部动态提供了新的视角。
关键设计:在几何结构分析方面,作者使用了主成分分析(PCA)等降维方法来分析轨迹的维度,使用对齐度量来衡量轨迹之间的相似性。神经推理算子是一个简单的线性映射,通过最小化预测误差进行训练。通用振荡特征的发现依赖于对注意力机制和前馈层输出的频谱分析。
🖼️ 关键图片
📊 实验亮点
该研究的主要实验亮点包括:1) 发现法律推理的“结晶化”现象,表征维度降低45%;2) 提出神经推理算子,在法律推理任务上实现了63.6%的准确率,无需遍历中间状态;3) 发现了一种通用的振荡特征,在不同领域和规模下保持不变。这些结果表明,推理的几何结构对模型的性能和效率具有重要影响。
🎯 应用场景
该研究成果可应用于提升大语言模型在特定领域的推理效率,例如在法律领域,可以利用神经推理算子快速预测案件结果,辅助法律决策。此外,该研究为理解大语言模型的内部机制提供了新的视角,有助于开发更高效、更可控的人工智能系统。未来,可以进一步探索不同领域的推理几何结构,并设计更通用的推理加速方法。
📄 摘要(原文)
Scale does not uniformly improve reasoning - it restructures it. Analyzing 25,000+ chain-of-thought trajectories across four domains (Law, Science, Code, Math) and two scales (8B, 70B parameters), we discover that neural scaling laws trigger domain-specific phase transitions rather than uniform capability gains. Legal reasoning undergoes Crystallization: 45% collapse in representational dimensionality (d95: 501 -> 274), 31% increase in trajectory alignment, and 10x manifold untangling. Scientific and mathematical reasoning remain Liquid - geometrically invariant despite 9x parameter increase. Code reasoning forms a discrete Lattice of strategic modes (silhouette: 0.13 -> 0.42). This geometry predicts learnability. We introduce Neural Reasoning Operators - learned mappings from initial to terminal hidden states. In crystalline legal reasoning, our operator achieves 63.6% accuracy on held-out tasks via probe decoding, predicting reasoning endpoints without traversing intermediate states. We further identify a universal oscillatory signature (coherence ~ -0.4) invariant across domains and scales, suggesting attention and feedforward layers drive reasoning through opposing dynamics. These findings establish that the cost of thought is determined not by task difficulty but by manifold geometry - offering a blueprint for inference acceleration where topology permits.