KOCO-BENCH: Can Large Language Models Leverage Domain Knowledge in Software Development?
作者: Xue Jiang, Jiaru Qian, Xianjie Shi, Chenjie Li, Hao Zhu, Ziyu Wang, Jielun Zhang, Zheyu Zhao, Kechi Zhang, Jia Li, Wenpin Jiao, Zhi Jin, Ge Li, Yihong Dong
分类: cs.SE, cs.AI, cs.CL, cs.LG
发布日期: 2026-01-19
🔗 代码/项目: GITHUB
💡 一句话要点
KOCO-BENCH:评估大语言模型在领域知识驱动的软件开发中的能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 领域知识 软件开发 基准测试 代码生成 知识理解 领域专业化
📋 核心要点
- 现有领域特定代码基准侧重于评估LLMs已掌握的知识,忽略了LLMs如何获取和应用新知识,缺乏显式知识语料库。
- KOCO-BENCH通过提供包含知识语料库的多粒度评估任务,评估LLMs在真实软件开发中应用领域知识的能力。
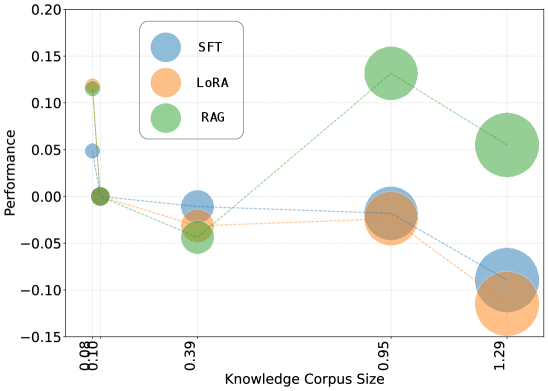
- 实验结果表明,即使应用领域专业化方法,现有LLMs在KOCO-BENCH上表现仍然不佳,突显了对更有效方法的迫切需求。
📝 摘要(中文)
大语言模型(LLMs)在通用编程方面表现出色,但在领域特定的软件开发中却面临挑战。这需要领域专业化方法,使LLMs能够学习和利用领域知识和数据。然而,现有的领域特定代码基准无法有效评估领域专业化方法,它们侧重于评估LLMs已掌握的知识,而不是如何获取和应用新知识,并且缺乏用于开发领域专业化方法的显式知识语料库。为此,我们提出了KOCO-BENCH,这是一个新颖的基准,旨在评估真实软件开发中的领域专业化方法。KOCO-BENCH包含6个新兴领域,涉及11个软件框架和25个项目,具有精心策划的知识语料库以及多粒度评估任务,包括领域代码生成(从函数级别到项目级别,带有严格的测试套件)和领域知识理解(通过多项选择问答)。与仅提供测试集进行直接评估的先前基准不同,KOCO-BENCH要求从知识语料库中获取和应用各种领域知识(API、规则、约束等)来解决评估任务。我们的评估表明,KOCO-BENCH对最先进的LLMs提出了重大挑战。即使应用了领域专业化方法(例如,SFT、RAG、kNN-LM),改进仍然很小。性能最佳的编码代理Claude Code仅达到34.2%,突显了对更有效的领域专业化方法的迫切需求。我们发布KOCO-BENCH、评估代码和基线,以促进进一步的研究,地址为https://github.com/jiangxxxue/KOCO-bench。
🔬 方法详解
问题定义:现有的大语言模型在通用编程任务上表现良好,但在特定领域的软件开发中面临挑战。现有的领域特定代码基准测试主要关注模型已有的知识,而忽略了模型如何学习和应用新的领域知识。此外,这些基准测试缺乏明确的知识语料库,这使得开发有效的领域知识学习方法变得困难。
核心思路:KOCO-BENCH的核心思路是提供一个更贴近实际软件开发场景的基准测试,它不仅评估模型已有的知识,更重要的是评估模型如何从提供的领域知识语料库中学习并应用这些知识来解决实际问题。这种设计鼓励研究人员开发更有效的领域知识学习和应用方法。
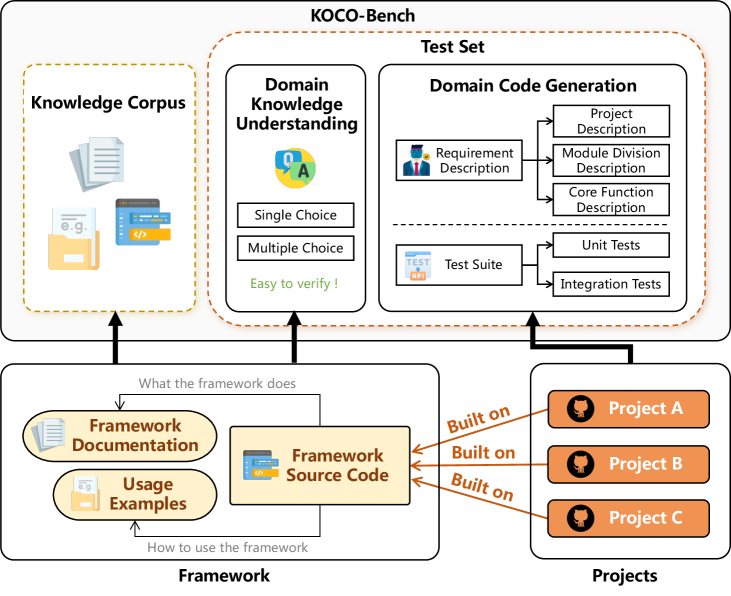
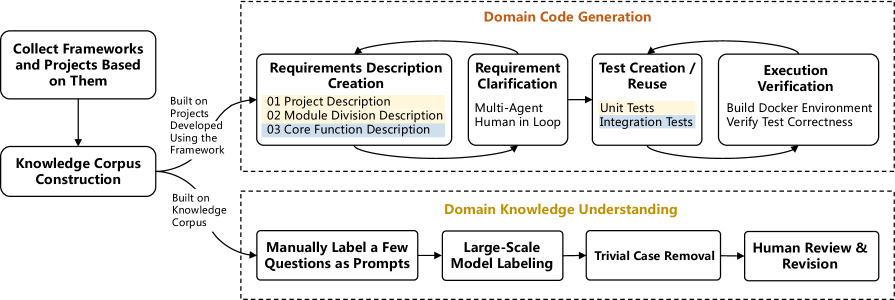
技术框架:KOCO-BENCH包含以下几个主要组成部分:1) 涵盖6个新兴领域的11个软件框架和25个项目;2) 精心策划的领域知识语料库,包含API、规则、约束等;3) 多粒度评估任务,包括函数级别和项目级别的代码生成,以及领域知识理解的多项选择题。代码生成任务附带严格的测试套件,以确保生成的代码质量。
关键创新:KOCO-BENCH的关键创新在于其评估范式的转变。它不再仅仅是评估模型已有的知识,而是要求模型从提供的知识语料库中学习并应用这些知识来解决问题。这种范式更贴近实际的软件开发场景,也更能反映模型的领域知识学习和应用能力。与现有基准测试相比,KOCO-BENCH提供了更丰富的领域知识语料库和更全面的评估任务。
关键设计:KOCO-BENCH的关键设计包括:1) 领域知识语料库的构建,需要领域专家参与,确保知识的准确性和完整性;2) 多粒度评估任务的设计,需要覆盖不同层次的软件开发任务,从简单的函数生成到复杂的项目开发;3) 严格的测试套件的设计,需要确保生成的代码质量,并能够准确评估模型的性能。
🖼️ 关键图片
📊 实验亮点
实验结果表明,即使应用了领域专业化方法(例如,SFT、RAG、kNN-LM),现有LLMs在KOCO-BENCH上的性能提升仍然有限。性能最佳的编码代理Claude Code仅达到34.2%的准确率,表明现有方法在领域知识学习和应用方面仍有很大的提升空间。
🎯 应用场景
KOCO-BENCH可用于评估和改进大语言模型在各个领域的软件开发能力,例如人工智能、生物信息学、金融科技等。通过该基准,可以推动领域知识驱动的软件开发技术的发展,提高软件开发的效率和质量,并加速各领域的创新。
📄 摘要(原文)
Large language models (LLMs) excel at general programming but struggle with domain-specific software development, necessitating domain specialization methods for LLMs to learn and utilize domain knowledge and data. However, existing domain-specific code benchmarks cannot evaluate the effectiveness of domain specialization methods, which focus on assessing what knowledge LLMs possess rather than how they acquire and apply new knowledge, lacking explicit knowledge corpora for developing domain specialization methods. To this end, we present KOCO-BENCH, a novel benchmark designed for evaluating domain specialization methods in real-world software development. KOCO-BENCH contains 6 emerging domains with 11 software frameworks and 25 projects, featuring curated knowledge corpora alongside multi-granularity evaluation tasks including domain code generation (from function-level to project-level with rigorous test suites) and domain knowledge understanding (via multiple-choice Q&A). Unlike previous benchmarks that only provide test sets for direct evaluation, KOCO-BENCH requires acquiring and applying diverse domain knowledge (APIs, rules, constraints, etc.) from knowledge corpora to solve evaluation tasks. Our evaluations reveal that KOCO-BENCH poses significant challenges to state-of-the-art LLMs. Even with domain specialization methods (e.g., SFT, RAG, kNN-LM) applied, improvements remain marginal. Best-performing coding agent, Claude Code, achieves only 34.2%, highlighting the urgent need for more effective domain specialization methods. We release KOCO-BENCH, evaluation code, and baselines to advance further research at https://github.com/jiangxxxue/KOCO-bench.