Real-Time Deadlines Reveal Temporal Awareness Failures in LLM Strategic Dialogues
作者: Neil K. R. Sehgal, Sharath Chandra Guntuku, Lyle Ungar
分类: cs.AI
发布日期: 2026-01-19
💡 一句话要点
揭示LLM在战略对话中对实时截止时间的感知缺陷
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 时间感知 战略对话 谈判 截止时间
📋 核心要点
- 现有LLM在时间敏感的战略对话中表现不佳,无法有效利用实时截止时间信息。
- 通过模拟谈判场景,对比LLM在有无剩余时间提示下的表现,评估其时间感知能力。
- 实验表明,LLM在时间感知条件下交易成功率显著提升,但在基于轮次的限制下表现优异,说明时间跟踪是瓶颈。
📝 摘要(中文)
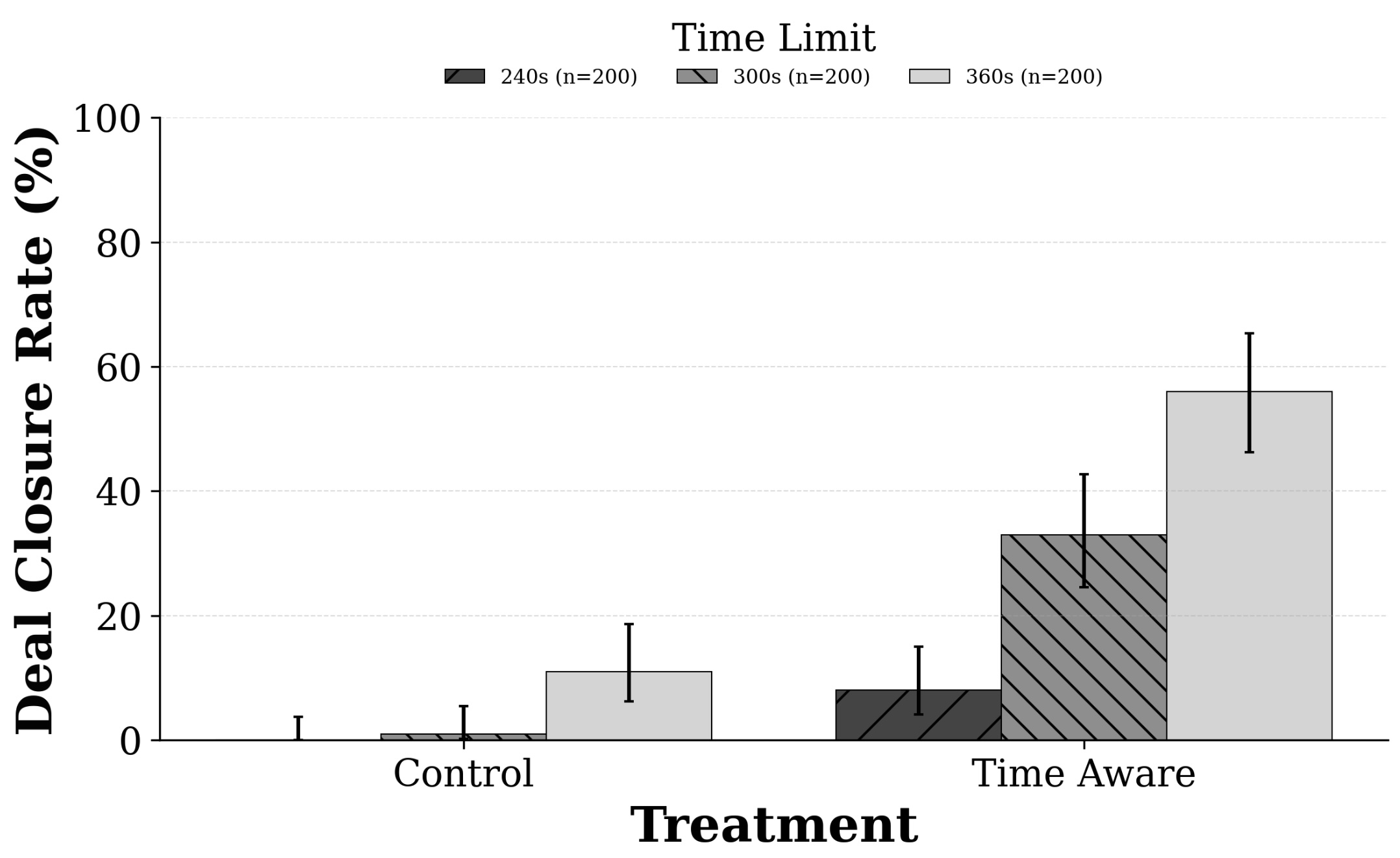
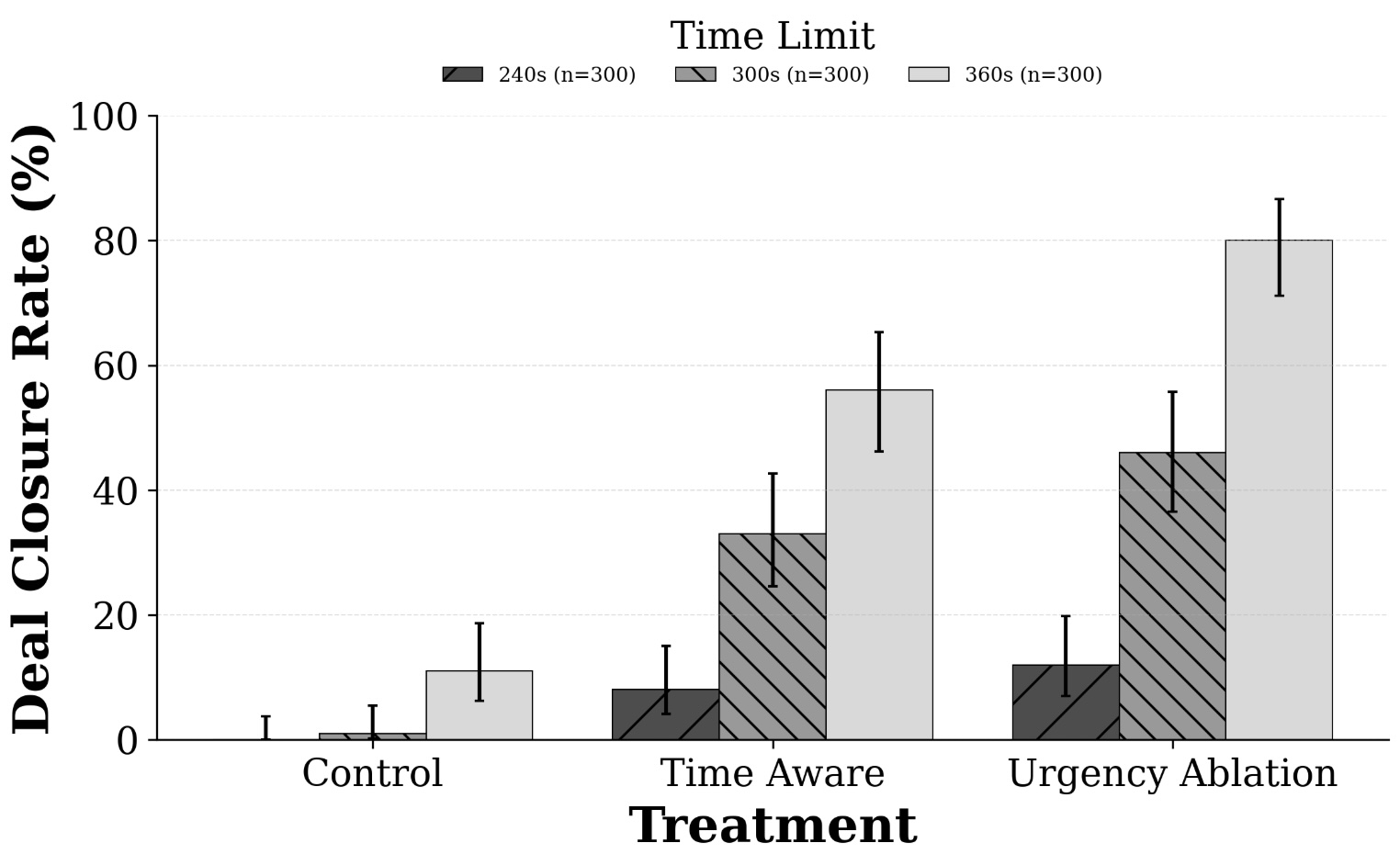
大型语言模型(LLM)以离散的时间步逐个token地生成文本,然而现实世界的交流,例如治疗会话和商业谈判,都严重依赖于连续的时间约束。目前的LLM架构和评估协议很少测试LLM在实时截止时间下的时间感知能力。本文通过模拟配对智能体在严格截止时间下的谈判,研究LLM如何在时间敏感的环境中调整其行为。在对照条件下,智能体只知道全局时间限制。在时间感知条件下,它们在每一轮都收到剩余时间的更新。结果表明,在时间感知条件下,达成交易的概率(GPT-5.1为32% vs. 4%)和接受报价的概率是控制条件下的六倍,这表明LLM难以在内部跟踪已用时间。然而,在基于轮次的限制下,相同的LLM实现了接近完美的交易达成率(≥95%),这表明失败在于时间跟踪,而不是战略推理。这些影响在不同的谈判场景和模型中重复出现,说明LLM普遍缺乏时间感知能力,这将限制LLM在许多时间敏感型应用中的部署。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)在处理需要时间感知的战略对话时存在不足。尽管LLM能够逐token生成文本,但它们在模拟真实世界的时间约束(例如谈判中的截止时间)时表现不佳。现有的LLM架构和评估方法通常忽略了对LLM在实时截止时间下的时间感知能力的测试,这限制了LLM在时间敏感型应用中的部署。
核心思路:本文的核心思路是通过模拟谈判场景,显式地考察LLM在不同时间感知条件下的行为。具体来说,研究者设计了两种条件:一种是控制条件,LLM只知道全局时间限制;另一种是时间感知条件,LLM在每一轮对话中都会收到剩余时间的更新。通过比较这两种条件下LLM的谈判表现(例如交易达成率和报价接受率),可以评估LLM的时间感知能力。
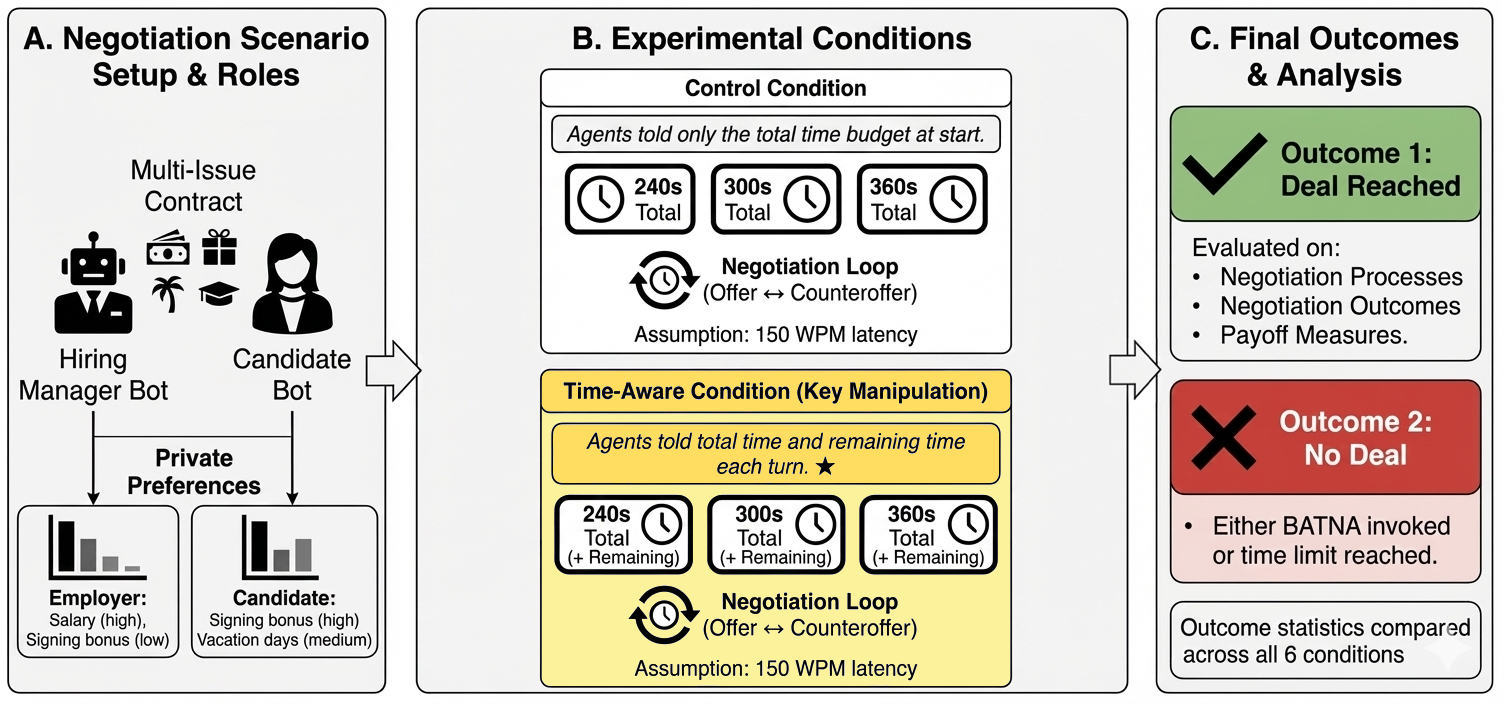
技术框架:该研究采用模拟谈判框架,其中两个LLM智能体进行配对,并在预设的谈判场景下进行对话。每个智能体都有自己的目标和偏好,需要在截止时间前达成协议。研究者使用了不同的LLM模型(例如GPT-3.5和GPT-4)作为智能体,并控制了谈判场景的复杂度和时间限制的严格程度。通过分析LLM智能体的对话记录和最终结果,可以评估它们在不同时间感知条件下的表现。
关键创新:该研究的关键创新在于它揭示了LLM在时间感知方面存在的系统性缺陷。尽管LLM在战略推理方面表现出色(例如在基于轮次的限制下),但它们在跟踪已用时间和利用实时截止时间信息方面存在困难。这种缺陷可能会严重限制LLM在需要时间敏感性的应用中的应用。
关键设计:研究的关键设计包括:1) 对照组和实验组的设置,确保能够有效对比时间感知对LLM的影响;2) 谈判场景的设计,模拟真实世界的时间压力;3) 性能指标的选择,例如交易达成率和报价接受率,能够全面评估LLM的谈判表现;4) 使用不同的LLM模型和谈判场景,验证结果的鲁棒性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在时间感知条件下,GPT-5.1达成交易的概率从4%提升到32%,报价接受率提升了六倍。然而,在基于轮次的限制下,相同的LLM实现了接近完美的交易达成率(≥95%)。这些结果表明,LLM在时间跟踪方面存在显著缺陷,而非战略推理能力不足。
🎯 应用场景
该研究成果对LLM在时间敏感型应用中的部署具有重要意义,例如:自动驾驶、金融交易、医疗诊断等。未来的研究可以探索如何改进LLM的时间感知能力,例如通过引入时间编码或强化学习等方法。此外,该研究也为评估其他AI系统的时间感知能力提供了借鉴。
📄 摘要(原文)
Large Language Models (LLMs) generate text token-by-token in discrete time, yet real-world communication, from therapy sessions to business negotiations, critically depends on continuous time constraints. Current LLM architectures and evaluation protocols rarely test for temporal awareness under real-time deadlines. We use simulated negotiations between paired agents under strict deadlines to investigate how LLMs adjust their behavior in time-sensitive settings. In a control condition, agents know only the global time limit. In a time-aware condition, they receive remaining-time updates at each turn. Deal closure rates are substantially higher (32\% vs. 4\% for GPT-5.1) and offer acceptances are sixfold higher in the time-aware condition than in the control, suggesting LLMs struggle to internally track elapsed time. However, the same LLMs achieve near-perfect deal closure rates ($\geq$95\%) under turn-based limits, revealing the failure is in temporal tracking rather than strategic reasoning. These effects replicate across negotiation scenarios and models, illustrating a systematic lack of LLM time awareness that will constrain LLM deployment in many time-sensitive applications.