On the Evidentiary Limits of Membership Inference for Copyright Auditing
作者: Murat Bilgehan Ertan, Emirhan Böge, Min Chen, Kaleel Mahmood, Marten van Dijk
分类: cs.CR, cs.AI
发布日期: 2026-01-19
💡 一句话要点
研究表明,针对LLM的成员推断攻击在版权审计中证据力不足
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 成员推断攻击 版权审计 大型语言模型 对抗性攻击 语义保留转换
📋 核心要点
- 现有成员推断攻击(MIA)被用于审计LLM训练数据是否侵犯版权,但其在实际场景下的可靠性存疑。
- 论文提出SAGE框架,通过稀疏自编码器引导的释义,在保留语义的同时改变训练数据的词汇结构。
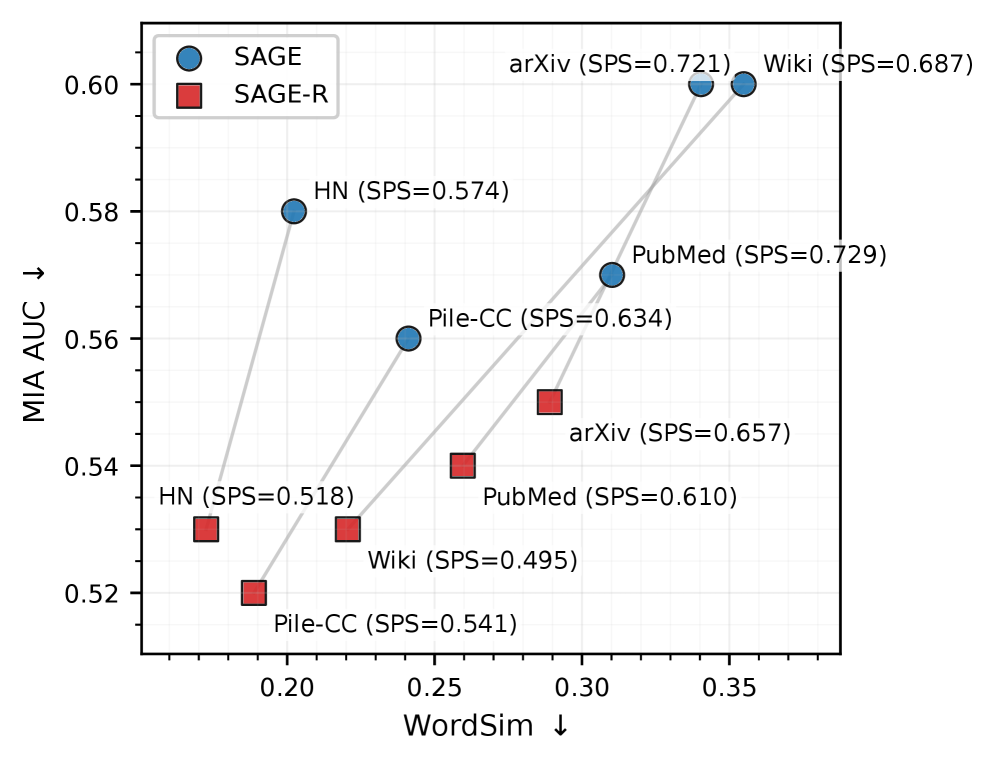
- 实验表明,在SAGE生成的释义数据上微调后,现有MIA的性能显著下降,表明其对语义保留转换不鲁棒。
📝 摘要(中文)
随着大型语言模型(LLM)在日益不透明的语料库上进行训练,成员推断攻击(MIA)已被提议用于审计受版权保护的文本是否在训练期间被使用。然而,人们越来越担心它们在实际条件下的可靠性。本文探讨了在对抗性版权纠纷中,MIA是否可以作为可采纳的证据,其中被告模型开发者可能会混淆训练数据,同时保留语义内容。为此,本文通过法官-检察官-被告的通信协议形式化了这一设置。为了测试在此协议下的鲁棒性,本文引入了SAGE(结构感知SAE引导提取),这是一个由稀疏自编码器(SAE)引导的释义框架,它重写训练数据以改变词汇结构,同时保留语义内容和下游效用。实验表明,当模型在SAGE生成的释义上进行微调时,最先进的MIA会退化,表明它们的信号对于语义保留转换并不鲁棒。虽然在某些微调方案中仍然存在一些泄漏,但这些结果表明,MIA在对抗性设置中是脆弱的,并且不足以作为LLM版权审计的独立机制。
🔬 方法详解
问题定义:论文旨在评估成员推断攻击(MIA)在版权审计中的证据效力,尤其是在模型开发者试图通过语义保留的转换来混淆训练数据的情况下。现有MIA方法的痛点在于,它们可能对训练数据的微小变化过于敏感,导致在对抗性场景下失效。
核心思路:论文的核心思路是,如果MIA对训练数据的语义保留转换不鲁棒,那么它就不能作为可靠的版权侵权证据。因此,论文设计了一种对抗性场景,其中被告可以通过释义来混淆训练数据,并评估MIA在此场景下的表现。
技术框架:论文提出了一个法官-检察官-被告的通信协议来形式化对抗性版权纠纷场景。同时,引入了SAGE(Structure-Aware SAE-Guided Extraction)框架,用于生成训练数据的释义版本。SAGE框架利用稀疏自编码器(SAE)来引导释义过程,确保在改变词汇结构的同时保留语义内容。实验中,首先在原始数据上训练目标模型,然后使用SAGE生成的释义数据进行微调,最后评估MIA在微调后的模型上的表现。
关键创新:SAGE框架是本文的关键创新点。它通过结合结构感知和SAE引导的提取,能够生成高质量的释义数据,有效地改变训练数据的词汇结构,同时保持语义内容和下游任务的性能。这使得研究人员能够更真实地模拟对抗性场景,并评估MIA的鲁棒性。
关键设计:SAGE框架的关键设计包括:1) 使用稀疏自编码器(SAE)学习输入文本的潜在表示,并利用这些表示来指导释义过程;2) 引入结构感知机制,以确保生成的释义在语法结构上与原始文本相似;3) 使用多种释义策略,例如同义词替换、句子重组等,以增加释义的多样性。实验中,使用了不同的微调策略和MIA方法,以评估SAGE框架的有效性和MIA的鲁棒性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,当模型在SAGE生成的释义数据上进行微调时,最先进的MIA的性能显著下降。这表明现有的MIA方法对语义保留转换并不鲁棒,因此在对抗性版权纠纷中作为独立证据的可靠性较低。具体而言,实验结果显示,在经过SAGE释义数据微调后,MIA的准确率显著降低,表明其信号容易被混淆。
🎯 应用场景
该研究成果可应用于评估和改进针对大型语言模型的版权审计方法。通过理解现有MIA的局限性,可以开发更鲁棒、更可靠的版权保护机制,从而促进人工智能技术的健康发展,并保护内容创作者的权益。未来的研究可以探索更高级的对抗性攻击方法,以及更有效的防御策略。
📄 摘要(原文)
As large language models (LLMs) are trained on increasingly opaque corpora, membership inference attacks (MIAs) have been proposed to audit whether copyrighted texts were used during training, despite growing concerns about their reliability under realistic conditions. We ask whether MIAs can serve as admissible evidence in adversarial copyright disputes where an accused model developer may obfuscate training data while preserving semantic content, and formalize this setting through a judge-prosecutor-accused communication protocol. To test robustness under this protocol, we introduce SAGE (Structure-Aware SAE-Guided Extraction), a paraphrasing framework guided by Sparse Autoencoders (SAEs) that rewrites training data to alter lexical structure while preserving semantic content and downstream utility. Our experiments show that state-of-the-art MIAs degrade when models are fine-tuned on SAGE-generated paraphrases, indicating that their signals are not robust to semantics-preserving transformations. While some leakage remains in certain fine-tuning regimes, these results suggest that MIAs are brittle in adversarial settings and insufficient, on their own, as a standalone mechanism for copyright auditing of LLMs.