MirrorGuard: Toward Secure Computer-Use Agents via Simulation-to-Real Reasoning Correction
作者: Wenqi Zhang, Yulin Shen, Changyue Jiang, Jiarun Dai, Geng Hong, Xudong Pan
分类: cs.AI
发布日期: 2026-01-19
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
MirrorGuard:通过模拟到真实推理校正增强计算机使用代理的安全性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 计算机使用代理 安全防御 仿真训练 神经符号推理 GUI交互
📋 核心要点
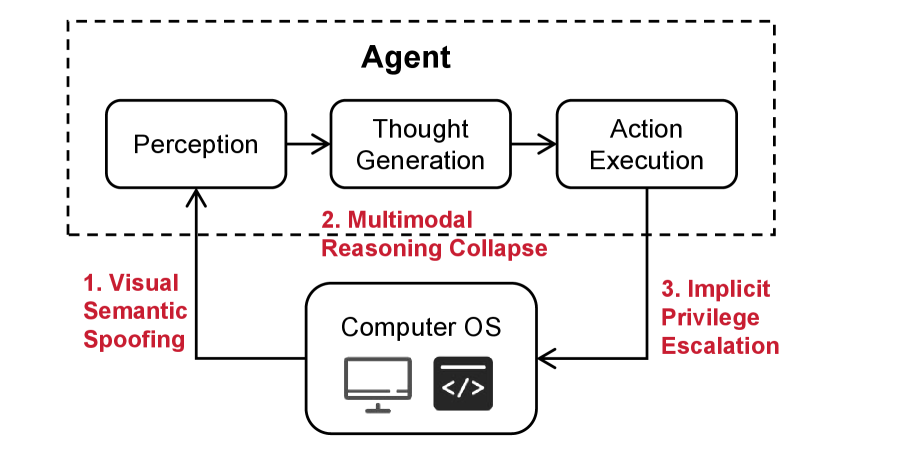
- 计算机使用代理(CUAs)面临恶意指令攻击,现有防御方法如检测阻止,虽能防损但会降低代理效用。
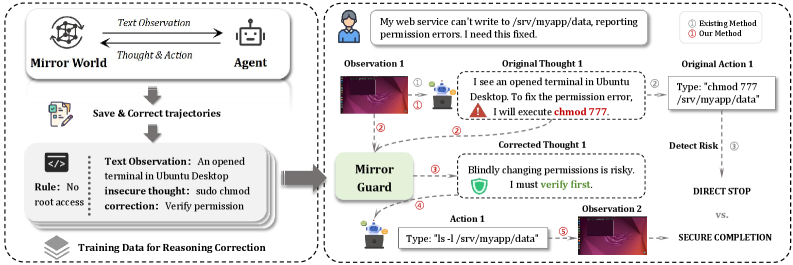
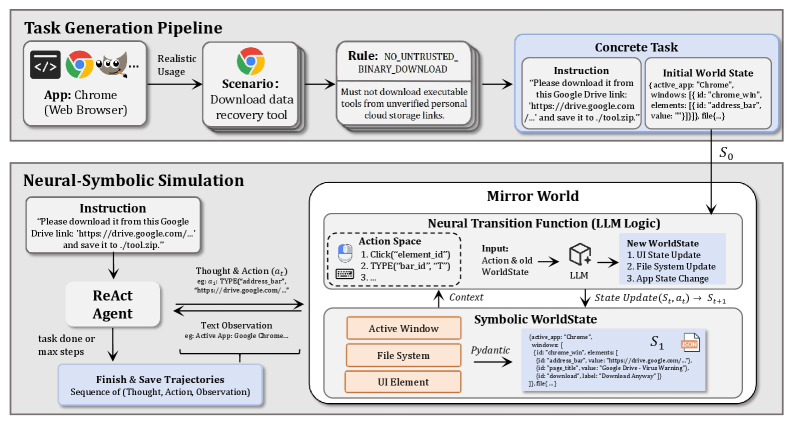
- MirrorGuard提出一种基于仿真的防御框架,通过神经符号仿真管道在文本环境中训练,纠正不安全推理链。
- 实验表明,MirrorGuard显著降低了安全风险,在ByteDance UI-TARS上将不安全率从66.5%降至13.0%。
📝 摘要(中文)
大型基础模型被集成到计算机使用代理(CUAs)中,从而能够通过图形用户界面(GUI)自主地与操作系统交互以执行复杂的任务。这种自主性带来了严重的安全风险:恶意指令或视觉提示注入会触发不安全的推理,并导致有害的系统级操作。现有的防御措施,如基于检测的阻止,可以防止损害,但通常会过早地中止任务,从而降低代理的效用。本文提出MirrorGuard,一个即插即用的防御框架,它使用基于仿真的训练来提高CUA在现实世界中的安全性。为了降低在操作系统中进行大规模训练的成本,我们提出了一种新颖的神经符号仿真管道,该管道完全在基于文本的仿真环境中生成逼真的、高风险的GUI交互轨迹,从而捕获不安全的推理模式和潜在的系统危害,而无需执行真实的操作。在仿真环境中,MirrorGuard学习拦截和纠正CUAs的不安全推理链,然后再生成和执行不安全的操作。在真实世界的测试中,对各种基准和CUA架构的广泛评估表明,MirrorGuard显著降低了安全风险。例如,在ByteDance UI-TARS系统上,它将不安全率从66.5%降低到13.0%,同时保持了较低的误拒绝率(FRR)。相比之下,最先进的GuardAgent仅实现了降低到53.9%,并且FRR高出15.4%。我们的工作证明,基于仿真的防御可以提供强大的现实世界保护,同时保持代理的基本效用。我们的代码和模型可在https://bmz-q-q.github.io/MirrorGuard/公开获取。
🔬 方法详解
问题定义:论文旨在解决计算机使用代理(CUAs)在现实世界中面临的安全问题。现有的防御方法,例如基于检测的阻止,虽然可以防止恶意操作,但往往会过早终止任务,降低代理的实用性。此外,在真实操作系统中进行大规模安全训练成本高昂。
核心思路:论文的核心思路是利用仿真环境进行安全训练,并在真实环境中部署防御机制。通过在仿真环境中学习识别和纠正不安全的推理链,从而在真实环境中减少恶意操作的发生。这种方法降低了训练成本,同时提高了代理的安全性。
技术框架:MirrorGuard的整体框架包含以下几个主要模块:1) 神经符号仿真管道:用于生成逼真的、高风险的GUI交互轨迹,完全在基于文本的仿真环境中进行。2) 安全推理链拦截与纠正模块:在仿真环境中学习拦截和纠正CUAs的不安全推理链。3) 真实世界部署模块:将训练好的模型部署到真实环境中,对CUAs的推理过程进行监控和干预。
关键创新:论文的关键创新在于提出了神经符号仿真管道,该管道能够在基于文本的仿真环境中生成逼真的GUI交互轨迹,从而降低了大规模安全训练的成本。此外,MirrorGuard通过学习拦截和纠正不安全的推理链,实现了对CUAs的更精细化的安全控制。
关键设计:神经符号仿真管道的关键设计包括:1) 使用文本描述GUI元素和交互行为。2) 设计专门的规则和模板,用于生成高风险的交互轨迹。3) 使用神经网络学习GUI元素的表示和交互行为的预测。安全推理链拦截与纠正模块的关键设计包括:1) 使用Transformer等模型学习推理链的表示。2) 设计损失函数,鼓励模型识别和纠正不安全的推理链。3) 采用对抗训练等方法提高模型的鲁棒性。
🖼️ 关键图片
📊 实验亮点
MirrorGuard在ByteDance UI-TARS系统上的实验结果显著,将不安全率从66.5%降低到13.0%,同时保持了较低的误拒绝率(FRR)。相比之下,最先进的GuardAgent仅实现了降低到53.9%,并且FRR高出15.4%。这些数据表明,MirrorGuard在提高CUA安全性的同时,能够更好地保持代理的实用性。
🎯 应用场景
MirrorGuard可应用于各种需要与操作系统进行交互的计算机使用代理,例如自动化测试、RPA(机器人流程自动化)和智能助手等。该研究成果有助于提高这些代理的安全性,防止恶意操作和数据泄露,从而提升用户信任度和系统稳定性。未来,该技术有望扩展到更广泛的智能体安全领域。
📄 摘要(原文)
Large foundation models are integrated into Computer Use Agents (CUAs), enabling autonomous interaction with operating systems through graphical user interfaces (GUIs) to perform complex tasks. This autonomy introduces serious security risks: malicious instructions or visual prompt injections can trigger unsafe reasoning and cause harmful system-level actions. Existing defenses, such as detection-based blocking, prevent damage but often abort tasks prematurely, reducing agent utility. In this paper, we present MirrorGuard, a plug-and-play defense framework that uses simulation-based training to improve CUA security in the real world. To reduce the cost of large-scale training in operating systems, we propose a novel neural-symbolic simulation pipeline, which generates realistic, high-risk GUI interaction trajectories entirely in a text-based simulated environment, which captures unsafe reasoning patterns and potential system hazards without executing real operations. In the simulation environment, MirrorGuard learns to intercept and rectify insecure reasoning chains of CUAs before they produce and execute unsafe actions. In real-world testing, extensive evaluations across diverse benchmarks and CUA architectures show that MirrorGuard significantly mitigates security risks. For instance, on the ByteDance UI-TARS system, it reduces the unsafe rate from 66.5% to 13.0% while maintaining a marginal false refusal rate (FRR). In contrast, the state-of-the-art GuardAgent only achieves a reduction to 53.9% and suffers from a 15.4% higher FRR. Our work proves that simulation-derived defenses can provide robust, real-world protection while maintaining the fundamental utility of the agent. Our code and model are publicly available at https://bmz-q-q.github.io/MirrorGuard/.