Teaching LLMs to Learn Tool Trialing and Execution through Environment Interaction
作者: Xingjie Gao, Pengcheng Huang, Zhenghao Liu, Yukun Yan, Shuo Wang, Zulong Chen, Chen Qian, Ge Yu, Yu Gu
分类: cs.SE, cs.AI
发布日期: 2026-01-19
🔗 代码/项目: GITHUB
💡 一句话要点
ToolMaster:通过环境交互教LLM学习工具试错与执行
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 工具学习 环境交互 试错学习 强化学习 泛化能力 鲁棒性
📋 核心要点
- 现有方法依赖静态轨迹,限制了LLM对新工具的泛化能力,无法有效应对工具的演进。
- ToolMaster通过试错-执行范式,让LLM通过与环境交互主动学习工具使用,提升泛化性。
- 实验表明,ToolMaster在处理未见或不熟悉的工具时,显著优于现有基线方法。
📝 摘要(中文)
本文提出ToolMaster框架,旨在提升大型语言模型(LLM)在面对新工具或不断演进的工具时的鲁棒性。现有方法主要依赖于记忆静态的解决方案路径,限制了LLM将工具使用泛化到新工具的能力。ToolMaster将工具使用从模仿黄金工具调用轨迹转变为通过与环境交互来主动学习工具使用。为了优化LLM的工具规划和调用能力,ToolMaster采用了一种试错-执行范式,首先训练LLM模仿包含显式工具试错和自我纠正的教师生成轨迹,然后通过强化学习联合协调试错和执行阶段。该过程使智能体能够通过与环境的主动交互来自主探索正确的工具使用方法,并形成有利于工具执行的经验知识。实验结果表明,ToolMaster在未见或不熟悉的工具上的泛化性和鲁棒性方面显著优于现有基线。
🔬 方法详解
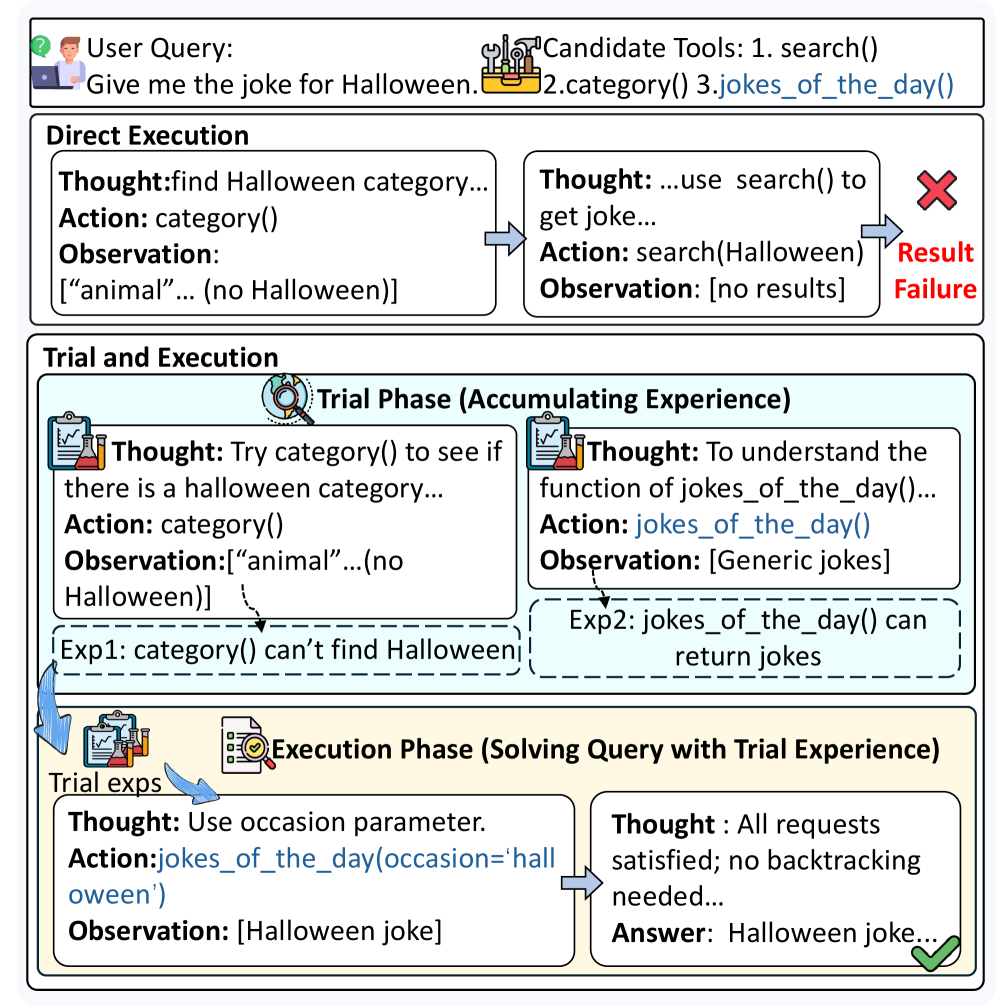
问题定义:现有方法在训练LLM使用工具时,主要依赖于模仿预先定义的“黄金轨迹”,即一系列正确的工具调用序列。这种方法的痛点在于,当遇到新的或不熟悉的工具时,LLM缺乏自主探索和学习的能力,难以泛化到新的场景。此外,工具本身也在不断演进,静态的轨迹无法适应工具的变化。
核心思路:ToolMaster的核心思路是将LLM的工具使用学习过程从被动模仿转变为主动探索。通过引入“试错-执行”的范式,让LLM在与环境的交互中,通过尝试不同的工具调用,观察结果,并进行自我纠正,从而学习到工具的正确使用方法。这种方法类似于人类学习新技能的过程,强调实践和反馈。
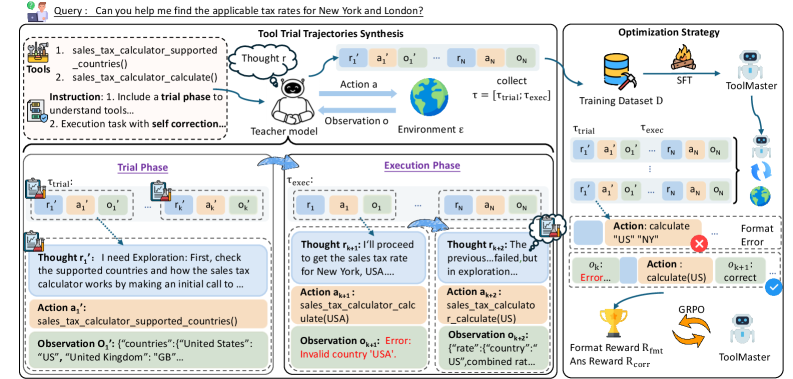
技术框架:ToolMaster框架包含两个主要阶段:模仿学习阶段和强化学习阶段。在模仿学习阶段,LLM首先模仿由教师生成的轨迹,这些轨迹不仅包含正确的工具调用,还包含一些错误的尝试和自我纠正的过程。这使得LLM能够学习到如何从错误中恢复。在强化学习阶段,LLM通过与环境的交互,根据获得的奖励信号来优化其工具规划和调用策略。这两个阶段共同作用,使得LLM能够自主探索正确的工具使用方法。
关键创新:ToolMaster最重要的技术创新点在于其“试错-执行”的范式。与以往依赖静态轨迹的方法不同,ToolMaster鼓励LLM主动探索,并通过与环境的交互来学习。这种方法更符合人类学习的模式,也更具有泛化能力。此外,ToolMaster还通过模仿学习和强化学习的结合,有效地利用了教师的知识和环境的反馈。
关键设计:在模仿学习阶段,ToolMaster使用交叉熵损失函数来训练LLM模仿教师生成的轨迹。在强化学习阶段,ToolMaster使用策略梯度算法来优化LLM的工具规划和调用策略。具体的奖励函数设计需要根据具体的任务来确定,通常包括成功完成任务的奖励、避免错误工具调用的惩罚等。此外,ToolMaster还可能使用一些探索策略,如ε-greedy策略,来鼓励LLM尝试不同的工具调用。
🖼️ 关键图片
📊 实验亮点
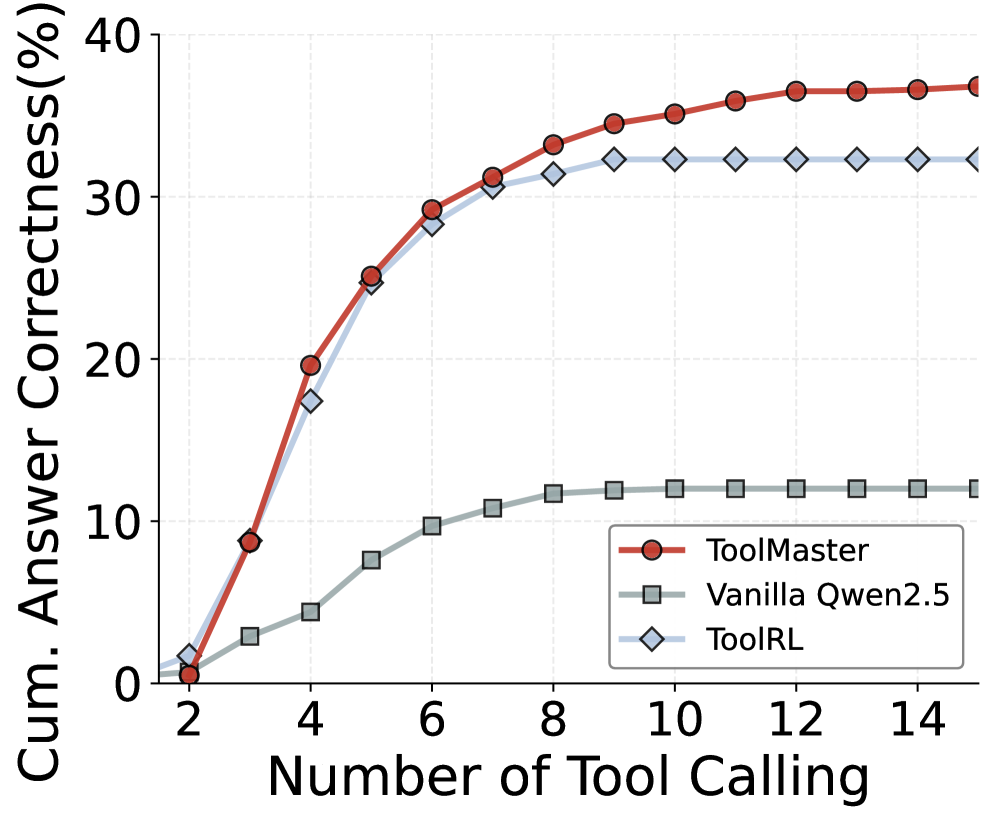
实验结果表明,ToolMaster在处理未见或不熟悉的工具时,显著优于现有基线方法。具体而言,ToolMaster在多个benchmark上取得了SOTA结果,并且在某些任务上的性能提升超过了10%。这表明ToolMaster的“试错-执行”范式能够有效地提高LLM的工具使用能力。
🎯 应用场景
ToolMaster具有广泛的应用前景,可用于开发更智能、更自主的智能助手。例如,可以将其应用于自动化运维、智能客服、科学研究等领域,帮助LLM更好地利用各种工具来解决复杂问题。该研究的实际价值在于提高了LLM在复杂环境下的适应性和鲁棒性,未来有望推动LLM在实际应用中的普及。
📄 摘要(原文)
Equipping Large Language Models (LLMs) with external tools enables them to solve complex real-world problems. However, the robustness of existing methods remains a critical challenge when confronting novel or evolving tools. Existing trajectory-centric paradigms primarily rely on memorizing static solution paths during training, which limits the ability of LLMs to generalize tool usage to newly introduced or previously unseen tools. In this paper, we propose ToolMaster, a framework that shifts tool use from imitating golden tool-calling trajectories to actively learning tool usage through interaction with the environment. To optimize LLMs for tool planning and invocation, ToolMaster adopts a trial-and-execution paradigm, which trains LLMs to first imitate teacher-generated trajectories containing explicit tool trials and self-correction, followed by reinforcement learning to coordinate the trial and execution phases jointly. This process enables agents to autonomously explore correct tool usage by actively interacting with environments and forming experiential knowledge that benefits tool execution. Experimental results demonstrate that ToolMaster significantly outperforms existing baselines in terms of generalization and robustness across unseen or unfamiliar tools. All code and data are available at https://github.com/NEUIR/ToolMaster.