Neurosymbolic LoRA: Why and When to Tune Weights vs. Rewrite Prompts
作者: Kevin Wang, Neel P. Bhatt, Cong Liu, Junbo Li, Runjin Chen, Yihan Xi, Timothy Barclay, Alvaro Velasquez, Ufuk Topcu, Zhangyang Wang
分类: cs.AI, cs.LG, cs.SC
发布日期: 2026-01-19
💡 一句话要点
提出神经符号LoRA框架,动态融合数值微调与符号编辑以提升LLM适应性
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 神经符号学习 LoRA TextGrad 大语言模型 微调 提示工程 动态调整 知识注入
📋 核心要点
- 现有LLM调整方法在数值微调和符号操作间权衡不足,前者擅长注入知识但缺乏灵活控制,后者反之。
- 提出神经符号LoRA框架,通过监控信号和奖励分类器动态选择数值微调(LoRA)或符号编辑(TextGrad)。
- 实验表明,该框架在多个LLM上优于纯数值或纯符号方法,尤其在数据稀缺的数学推理领域表现突出。
📝 摘要(中文)
大型语言模型(LLM)可以通过数值更新(改变模型参数)或符号操作(处理离散提示或逻辑约束)进行调整。数值微调擅长注入新的事实知识,而符号更新则提供对风格和对齐的灵活控制,无需重新训练。我们引入了一种神经符号LoRA框架,该框架动态地结合了这两种互补策略。具体来说,我们提出了一个统一的监控信号和一个基于奖励的分类器,以决定何时使用LoRA进行更深层次的事实重建,以及何时应用TextGrad进行token级别的编辑。我们的方法通过仅在需要时将符号转换卸载到外部LLM来保持内存效率。此外,符号编辑过程中产生的精炼提示可以作为高质量、可重用的训练数据,这在数学推理等数据稀缺领域非常重要。在多个LLM骨干网络上进行的大量实验表明,神经符号LoRA始终优于纯数值或纯符号基线,展示了卓越的适应性和改进的性能。我们的研究结果强调了交错使用数值和符号更新的价值,从而释放了语言模型微调的新水平的通用性。
🔬 方法详解
问题定义:现有的大型语言模型调整方法,要么侧重于数值微调(如LoRA),通过更新模型参数来注入知识,但缺乏对风格和对齐的灵活控制;要么侧重于符号操作(如提示工程),通过修改提示或逻辑约束来控制模型的行为,但难以注入新的事实知识。这两种方法各有优缺点,如何有效地结合它们是一个挑战。
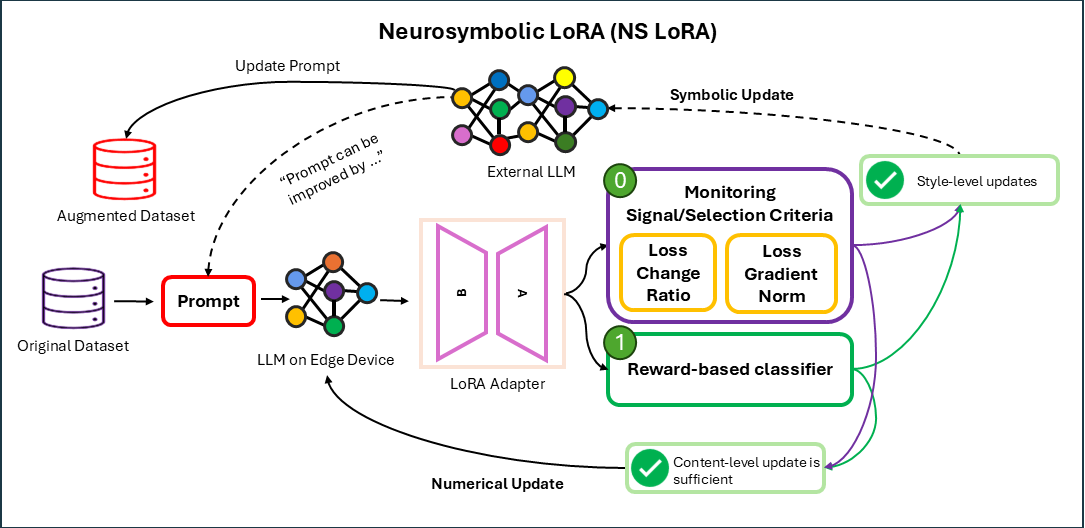
核心思路:论文的核心思路是设计一个神经符号框架,该框架能够动态地决定何时使用数值微调(LoRA)来学习新的事实知识,以及何时使用符号编辑(TextGrad)来调整模型的风格和对齐。通过一个统一的监控信号和一个基于奖励的分类器,框架可以根据当前任务的需求,自适应地选择最合适的调整策略。
技术框架:神经符号LoRA框架包含以下主要模块:1) 监控模块:使用统一的监控信号来评估模型在当前任务上的表现,例如预测的置信度或与ground truth的差距。2) 决策模块:基于监控信号,使用一个基于奖励的分类器来决定是使用LoRA进行数值微调,还是使用TextGrad进行符号编辑。3) 数值微调模块:使用LoRA对模型参数进行微调,以注入新的事实知识。4) 符号编辑模块:使用TextGrad对提示进行编辑,以调整模型的风格和对齐。5) 外部LLM:将符号转换卸载到外部LLM,以保持内存效率。
关键创新:该方法最重要的创新点在于动态地结合了数值微调和符号编辑,使得模型能够根据当前任务的需求,自适应地选择最合适的调整策略。与传统的静态方法相比,该方法能够更好地平衡知识注入和风格控制,从而提高模型的整体性能。此外,利用符号编辑产生的精炼提示作为高质量的训练数据,尤其在数据稀缺的场景下,是一个重要的贡献。
关键设计:1) 统一监控信号:设计一个能够同时反映模型知识掌握程度和风格对齐程度的监控信号。2) 基于奖励的分类器:使用强化学习训练一个分类器,该分类器能够根据监控信号,选择最优的调整策略。3) TextGrad:使用TextGrad进行token级别的提示编辑,以实现对模型风格和对齐的精细控制。4) 外部LLM:使用外部LLM进行符号转换,以降低计算成本。
🖼️ 关键图片
📊 实验亮点
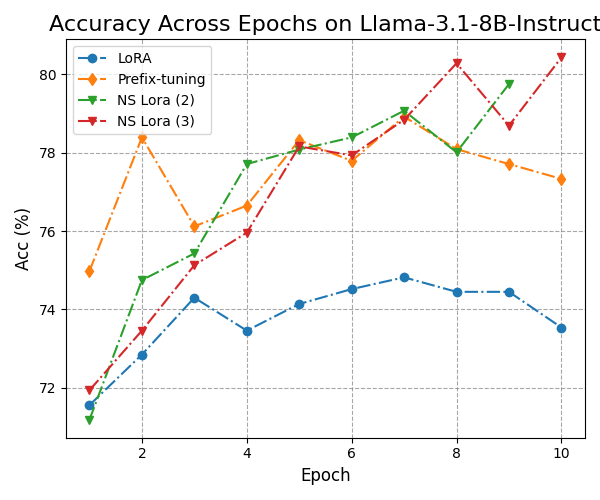
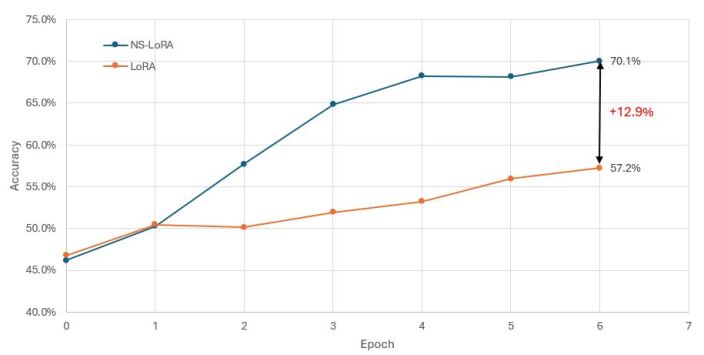
实验结果表明,神经符号LoRA框架在多个LLM骨干网络上均优于纯数值或纯符号基线。尤其在数学推理等数据稀缺领域,该方法能够显著提高模型的性能。例如,在某些任务上,该方法能够将模型的准确率提高10%以上。
🎯 应用场景
该研究成果可应用于各种需要灵活调整LLM的场景,例如:在特定领域注入专业知识、根据用户偏好调整模型风格、提高模型在数学推理等数据稀缺领域的性能。该方法能够提升LLM在实际应用中的适应性和可用性,具有广泛的应用前景。
📄 摘要(原文)
Large language models (LLMs) can be adapted either through numerical updates that alter model parameters or symbolic manipulations that work on discrete prompts or logical constraints. While numerical fine-tuning excels at injecting new factual knowledge, symbolic updates offer flexible control of style and alignment without retraining. We introduce a neurosymbolic LoRA framework that dynamically combines these two complementary strategies. Specifically, we present a unified monitoring signal and a reward-based classifier to decide when to employ LoRA for deeper factual reconstruction and when to apply TextGrad for token-level edits. Our approach remains memory-efficient by offloading the symbolic transformations to an external LLM only when needed. Additionally, the refined prompts produced during symbolic editing serve as high-quality, reusable training data, an important benefit in data-scarce domains like mathematical reasoning. Extensive experiments across multiple LLM backbones show that neurosymbolic LoRA consistently outperforms purely numerical or purely symbolic baselines, demonstrating superior adaptability and improved performance. Our findings highlight the value of interleaving numerical and symbolic updates to unlock a new level of versatility in language model fine-tuning.