Policy-Based Deep Reinforcement Learning Hyperheuristics for Job-Shop Scheduling Problems
作者: Sofiene Lassoued, Asrat Gobachew, Stefan Lier, Andreas Schwung
分类: cs.AI
发布日期: 2026-01-16
💡 一句话要点
提出基于策略的深度强化学习超启发式算法,解决Job-Shop调度问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: Job-Shop调度 深度强化学习 超启发式算法 动作预过滤 承诺机制 调度优化 生产制造
📋 核心要点
- Job-Shop调度问题复杂,传统启发式算法难以适应动态变化,神经网络方法缺乏有效探索机制。
- 论文提出基于策略的深度强化学习超启发式框架,学习动态切换调度规则,提升问题求解能力。
- 通过动作预过滤和承诺机制,框架实现了更有效的启发式评估和切换,实验证明优于传统和神经方法。
📝 摘要(中文)
本文提出了一种基于策略的深度强化学习超启发式框架,用于解决Job-Shop调度问题(JSSP)。该超启发式智能体学习根据系统状态动态切换调度规则。我们通过两个关键机制扩展了超启发式框架。首先,动作预过滤将决策限制在可行的低级动作上,使低级启发式算法能够独立于环境约束进行评估,并提供公正的评估。其次,承诺机制调节启发式切换的频率。我们研究了不同承诺策略(从逐步切换到完整episode承诺)对训练行为和完工时间的影响。此外,我们比较了策略层面的两种动作选择策略:确定性贪婪选择和随机抽样。在标准JSSP基准上的计算实验表明,所提出的方法优于传统的启发式算法、元启发式算法和最近的基于神经网络的调度方法。
🔬 方法详解
问题定义:论文旨在解决Job-Shop调度问题(JSSP)。现有方法,如传统启发式算法和元启发式算法,在面对复杂的JSSP实例时,难以找到最优解或次优解。最近的基于神经网络的调度方法虽然取得了一些进展,但仍然存在探索效率低下的问题,难以充分利用启发式规则的优势。
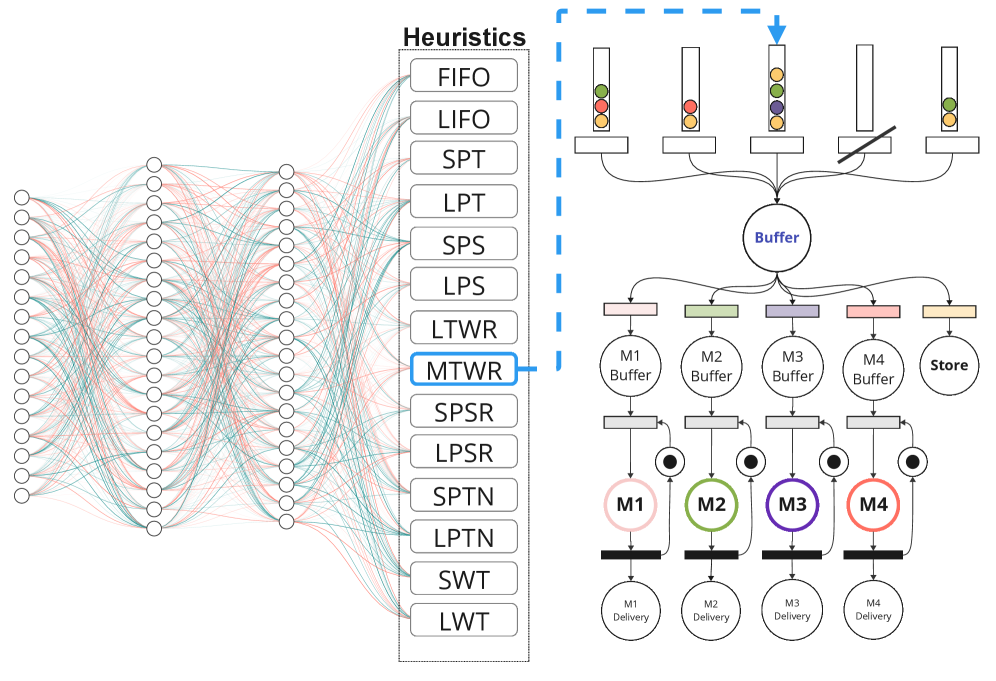
核心思路:论文的核心思路是利用深度强化学习(DRL)训练一个超启发式智能体,该智能体能够根据当前JSSP的状态,动态地选择合适的低级启发式规则进行调度。通过学习不同启发式规则在不同状态下的适用性,智能体能够更有效地探索解空间,从而找到更好的调度方案。
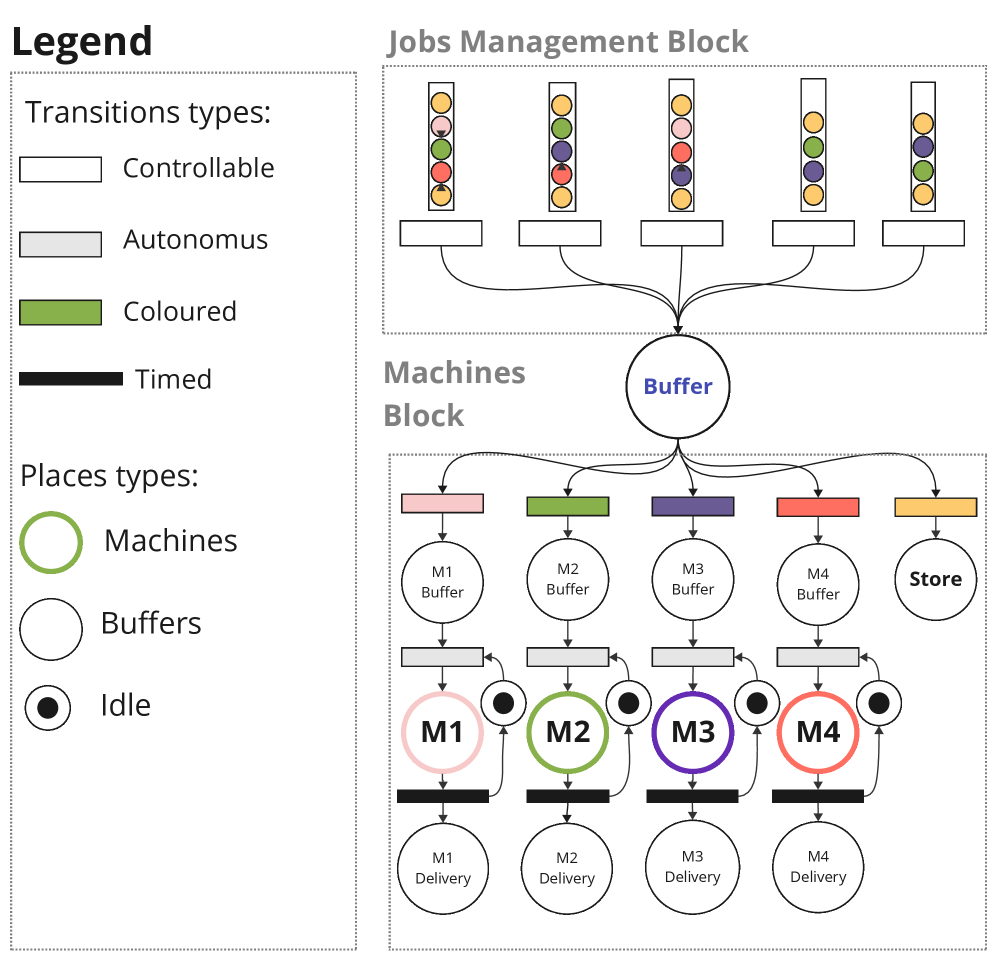
技术框架:整体框架包含以下几个主要模块:1) 环境:JSSP的模拟环境,提供状态信息和执行动作后的反馈。2) 超启发式智能体:基于深度神经网络的策略网络,根据环境状态输出动作(即选择哪个低级启发式规则)。3) 动作预过滤:根据当前环境状态,过滤掉不可行的低级启发式规则,只保留可行的动作。4) 承诺机制:控制启发式规则切换的频率,从每一步都切换到整个episode只切换一次。5) 奖励函数:根据调度结果(例如完工时间)计算奖励,用于训练智能体。
关键创新:论文的关键创新在于将超启发式算法与深度强化学习相结合,并引入了动作预过滤和承诺机制。动作预过滤确保了智能体只选择可行的动作,避免了无效的探索,提高了学习效率。承诺机制则允许研究不同启发式切换频率对性能的影响。
关键设计:论文中,策略网络采用深度神经网络结构,具体结构未知。奖励函数的设计目标是最小化完工时间。动作选择策略包括确定性贪婪选择和随机抽样。承诺机制则探索了从单步切换到完整episode承诺的不同策略。具体参数设置未知。
🖼️ 关键图片
📊 实验亮点
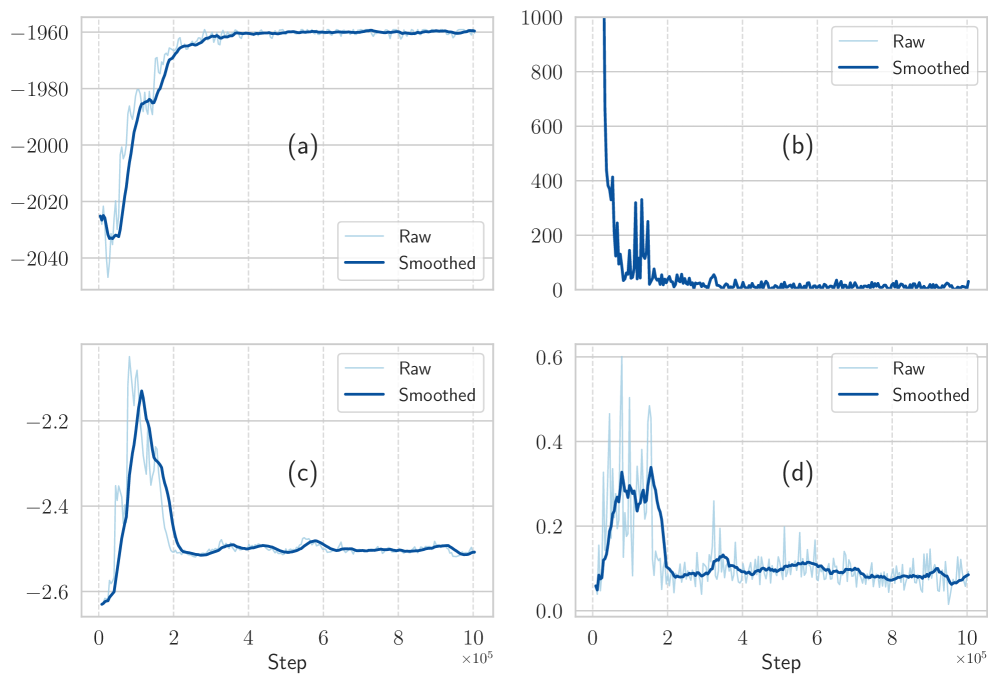
实验结果表明,所提出的方法在标准JSSP基准上优于传统的启发式算法、元启发式算法和最近的基于神经网络的调度方法。具体性能数据未知,但摘要明确指出优于现有方法,表明该方法具有显著的性能提升。
🎯 应用场景
该研究成果可应用于各种生产制造领域的Job-Shop调度问题,例如半导体制造、汽车制造、航空航天等。通过智能优化调度,可以显著提高生产效率,降低生产成本,缩短交货时间,提升企业竞争力。未来,该方法还可以扩展到其他复杂的组合优化问题。
📄 摘要(原文)
This paper proposes a policy-based deep reinforcement learning hyper-heuristic framework for solving the Job Shop Scheduling Problem. The hyper-heuristic agent learns to switch scheduling rules based on the system state dynamically. We extend the hyper-heuristic framework with two key mechanisms. First, action prefiltering restricts decision-making to feasible low-level actions, enabling low-level heuristics to be evaluated independently of environmental constraints and providing an unbiased assessment. Second, a commitment mechanism regulates the frequency of heuristic switching. We investigate the impact of different commitment strategies, from step-wise switching to full-episode commitment, on both training behavior and makespan. Additionally, we compare two action selection strategies at the policy level: deterministic greedy selection and stochastic sampling. Computational experiments on standard JSSP benchmarks demonstrate that the proposed approach outperforms traditional heuristics, metaheuristics, and recent neural network-based scheduling methods