TANDEM: Temporal-Aware Neural Detection for Multimodal Hate Speech
作者: Girish A. Koushik, Helen Treharne, Diptesh Kanojia
分类: cs.AI, cs.CL, cs.MM, cs.SI
发布日期: 2026-01-16
备注: Under review at ICWSM 2026
💡 一句话要点
TANDEM:时序感知神经检测用于多模态仇恨言论识别,提升可解释性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 仇恨言论检测 强化学习 时序建模 可解释性AI
📋 核心要点
- 现有仇恨言论检测系统缺乏细粒度可解释性,难以提供时间戳和目标身份等关键信息。
- TANDEM采用串联强化学习,通过跨模态上下文约束,使视觉-语言和音频-语言模型相互优化。
- 实验表明,TANDEM在目标识别方面显著优于现有方法,在HateMM数据集上F1值提升30%。
📝 摘要(中文)
社交媒体平台上的长篇多模态内容日益增多,有害信息通过音频、视觉和文本线索的复杂交互构建。虽然自动化系统可以高精度地标记仇恨言论,但它们通常是“黑盒”,无法提供细粒度的、可解释的证据,例如精确的时间戳和目标身份,而这些对于有效的人工审核至关重要。本文提出了一个统一的框架TANDEM,将视听仇恨检测从二元分类任务转变为结构化推理问题。该方法采用了一种新颖的串联强化学习策略,其中视觉-语言和音频-语言模型通过自约束的跨模态上下文相互优化,从而在不需要密集帧级别监督的情况下稳定地进行扩展时序序列上的推理。在三个基准数据集上的实验表明,TANDEM显著优于零样本和上下文增强的基线方法,在HateMM数据集上的目标识别中实现了0.73的F1值(比现有技术水平提高了30%),同时保持了精确的时间定位。进一步观察到,虽然二元检测是稳健的,但在多类别设置中区分冒犯性和仇恨性内容仍然具有挑战性,这归因于固有的标签模糊性和数据集不平衡。更广泛地说,研究结果表明,即使在复杂的多模态环境中,也可以实现结构化的、可解释的对齐,为下一代透明且可操作的在线安全审核工具提供了一个蓝图。
🔬 方法详解
问题定义:论文旨在解决多模态仇恨言论检测中缺乏可解释性的问题。现有方法通常将检测视为二元分类任务,忽略了仇恨言论的时序性和多模态交互,导致无法提供精确的时间定位和目标身份信息,难以支持人工审核。
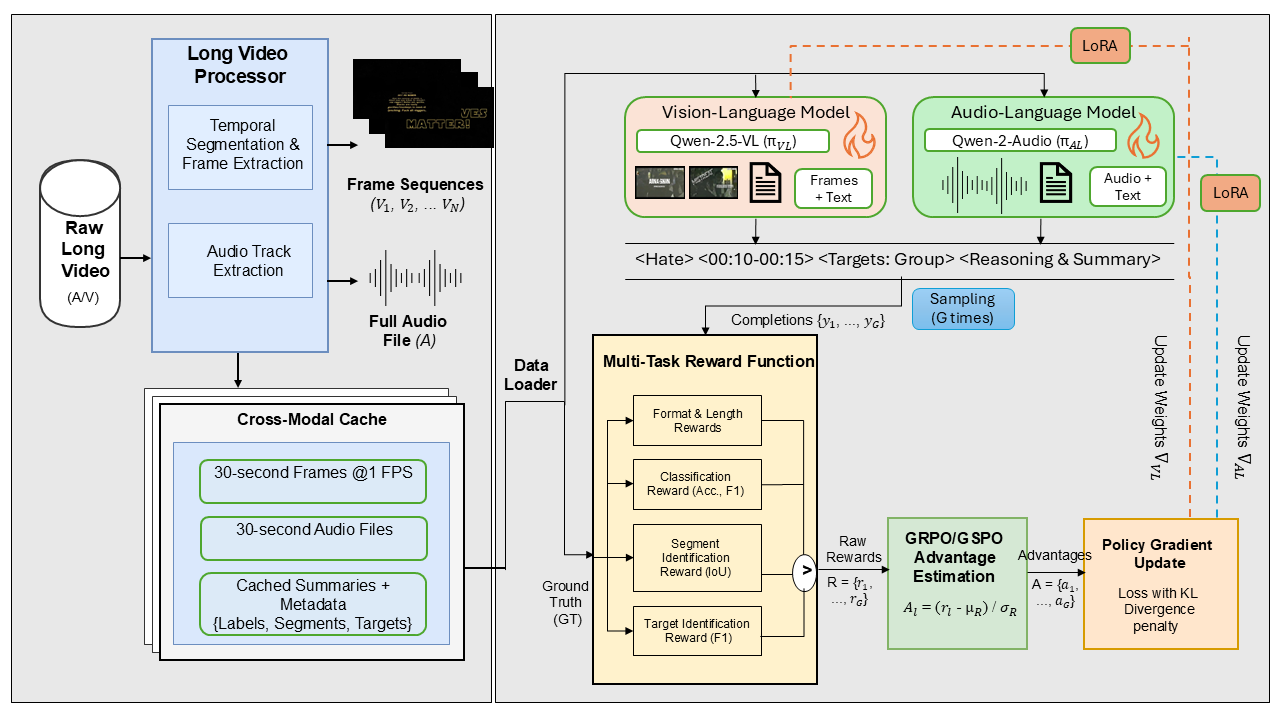
核心思路:论文的核心思路是将仇恨言论检测转化为一个结构化推理问题,通过建模音频、视觉和文本之间的时序关系,实现细粒度的检测和解释。TANDEM框架利用跨模态上下文信息,使不同模态的模型能够相互学习和优化,从而提高检测的准确性和可解释性。
技术框架:TANDEM框架包含视觉-语言和音频-语言两个主要模块,每个模块都包含一个检测器和一个解释器。检测器负责识别仇恨言论,解释器负责提供时间定位和目标身份信息。两个模块通过串联强化学习策略进行训练,其中一个模块的输出作为另一个模块的输入,从而实现跨模态上下文的共享和优化。整体流程如下:首先,视觉-语言模块检测视频中的仇恨言论并生成解释;然后,音频-语言模块利用视觉-语言模块的输出作为上下文信息,进一步检测音频中的仇恨言论并生成解释;最后,将两个模块的输出进行融合,得到最终的检测结果。
关键创新:TANDEM的关键创新在于提出了串联强化学习策略,通过自约束的跨模态上下文,使视觉-语言和音频-语言模型能够相互优化。这种策略无需密集的帧级别监督,即可在扩展时序序列上稳定地进行推理。与现有方法相比,TANDEM能够提供更精确的时间定位和目标身份信息,从而提高检测的可解释性。
关键设计:TANDEM使用Transformer网络作为检测器和解释器的基础架构。损失函数包括检测损失、解释损失和跨模态一致性损失。检测损失用于优化检测器的性能,解释损失用于优化解释器的性能,跨模态一致性损失用于鼓励不同模态的模型生成一致的解释。强化学习的奖励函数基于检测的准确性和解释的完整性。具体的参数设置和网络结构细节在论文中有详细描述。
🖼️ 关键图片

📊 实验亮点
TANDEM在三个基准数据集上进行了评估,结果表明其显著优于零样本和上下文增强的基线方法。在HateMM数据集上的目标识别中,TANDEM实现了0.73的F1值,比现有技术水平提高了30%。实验还表明,TANDEM能够提供精确的时间定位,有助于审核人员快速定位仇恨言论。
🎯 应用场景
TANDEM框架可应用于社交媒体平台的内容审核,帮助审核人员快速定位和理解仇恨言论,提高审核效率和准确性。该研究还可用于开发更透明和可信赖的AI系统,促进人机协作,提升在线社区的安全性。
📄 摘要(原文)
Social media platforms are increasingly dominated by long-form multimodal content, where harmful narratives are constructed through a complex interplay of audio, visual, and textual cues. While automated systems can flag hate speech with high accuracy, they often function as "black boxes" that fail to provide the granular, interpretable evidence, such as precise timestamps and target identities, required for effective human-in-the-loop moderation. In this work, we introduce TANDEM, a unified framework that transforms audio-visual hate detection from a binary classification task into a structured reasoning problem. Our approach employs a novel tandem reinforcement learning strategy where vision-language and audio-language models optimize each other through self-constrained cross-modal context, stabilizing reasoning over extended temporal sequences without requiring dense frame-level supervision. Experiments across three benchmark datasets demonstrate that TANDEM significantly outperforms zero-shot and context-augmented baselines, achieving 0.73 F1 in target identification on HateMM (a 30% improvement over state-of-the-art) while maintaining precise temporal grounding. We further observe that while binary detection is robust, differentiating between offensive and hateful content remains challenging in multi-class settings due to inherent label ambiguity and dataset imbalance. More broadly, our findings suggest that structured, interpretable alignment is achievable even in complex multimodal settings, offering a blueprint for the next generation of transparent and actionable online safety moderation tools.