Cross-Modal Attention Network with Dual Graph Learning in Multimodal Recommendation
作者: Ji Dai, Quan Fang, Jun Hu, Desheng Cai, Yang Yang, Can Zhao
分类: cs.IR, cs.AI
发布日期: 2026-01-16
备注: Accepted to ACM Transactions on Multimedia Computing, Communications, and Applications (TOMM)
💡 一句话要点
提出CRANE模型,通过递归跨模态注意力网络和双图学习增强多模态推荐效果。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态推荐 跨模态注意力 图神经网络 对比学习 用户画像 信息融合 递归神经网络
📋 核心要点
- 现有方法在多模态推荐中,模态融合方式较为简单,未能充分挖掘模态间深层关系。
- CRANE模型通过递归跨模态注意力机制,在联合潜在空间中迭代优化特征,有效捕捉高阶依赖。
- 实验结果表明,CRANE在多个数据集上显著优于现有方法,关键指标平均提升5%。
📝 摘要(中文)
多媒体推荐系统利用用户-物品交互和多模态信息来捕捉用户偏好,从而实现更准确和个性化的推荐。然而,现有方法存在两个关键限制:一是浅层的模态融合通常依赖于简单的拼接,未能充分利用丰富的模态内和模态间关系;二是用户仅由交互ID表征,而物品受益于丰富的多模态内容,导致不对称的特征处理,阻碍了共享语义空间的学习。为了解决这些问题,我们提出了一个具有双图嵌入的跨模态递归注意力网络(CRANE)。为了解决浅层融合问题,我们设计了一个核心的递归跨模态注意力(RCA)机制,该机制在联合潜在空间中基于互相关迭代地细化模态特征,有效地捕获高阶的模态内和模态间依赖关系。对于对称的多模态学习,我们通过聚合用户交互过的物品的特征来显式地构建用户的多模态画像。此外,CRANE集成了一个对称的双图框架——包括一个异构的用户-物品交互图和一个同构的物品-物品语义图——通过自监督对比学习目标统一起来,以融合行为和语义信号。尽管具有这些复杂的建模能力,CRANE仍保持了很高的计算效率。理论和实证分析证实了其可扩展性和高实用效率,在小型数据集上实现了更快的收敛,在大型数据集上实现了卓越的性能上限。在四个公共真实世界数据集上的综合实验验证了关键指标比最先进的基线平均提高了5%。
🔬 方法详解
问题定义:现有基于多模态信息的推荐系统,在融合用户行为和物品多模态特征时,通常采用简单的拼接或浅层融合方法,无法充分挖掘模态内部和模态之间的深层关系。此外,用户特征通常仅由交互ID表示,而物品则具有丰富的多模态信息,导致用户和物品特征的不对称,影响了共享语义空间的学习。
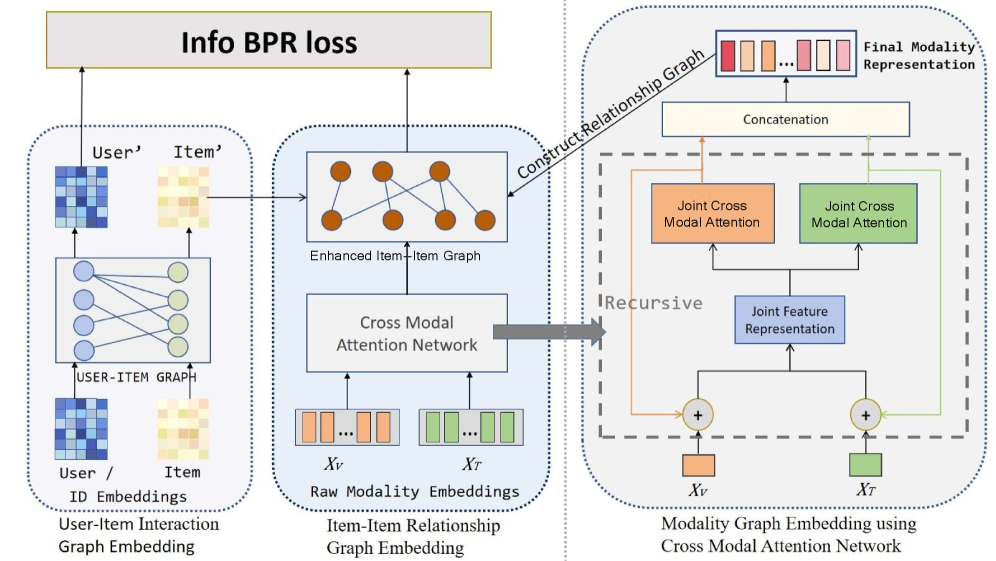
核心思路:CRANE的核心思路是通过递归跨模态注意力机制(RCA)来学习模态间的高阶依赖关系,并构建用户的多模态画像,从而实现用户和物品特征的对称表示。同时,利用双图结构(用户-物品交互图和物品-物品语义图)融合行为和语义信息,并通过对比学习进行优化。
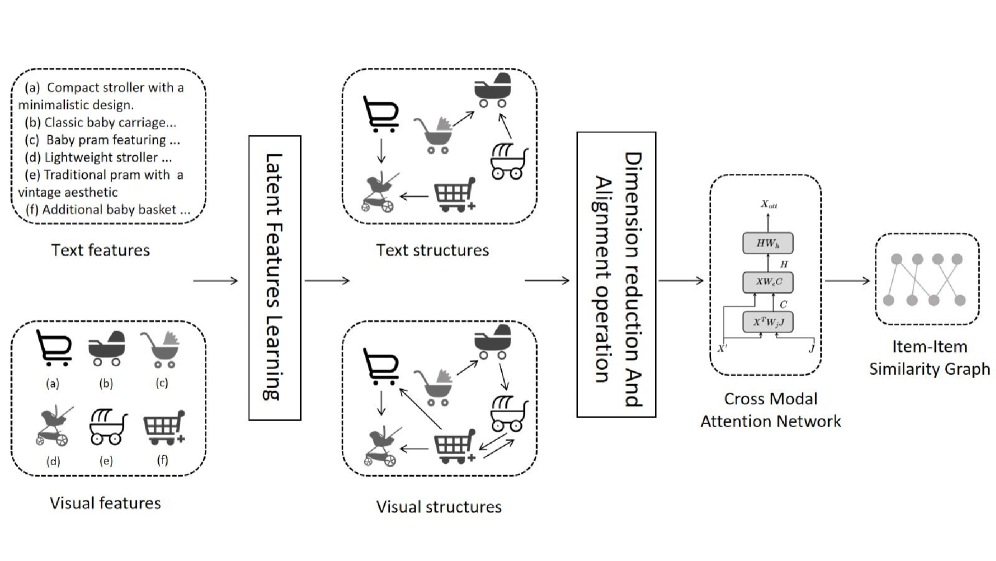
技术框架:CRANE的整体框架包括以下几个主要模块: 1. 多模态特征提取:提取物品的多模态特征(例如,图像、文本)。 2. 递归跨模态注意力(RCA):迭代地细化模态特征,捕捉模态内和模态间的依赖关系。 3. 用户多模态画像构建:通过聚合用户交互过的物品的特征来构建用户的多模态画像。 4. 双图构建:构建用户-物品交互图和物品-物品语义图。 5. 对比学习:利用对比学习目标来融合行为和语义信息,并优化模型参数。
关键创新:CRANE的关键创新点在于: 1. 递归跨模态注意力(RCA)机制:通过迭代地细化模态特征,有效地捕捉高阶的模态内和模态间依赖关系,克服了浅层融合的局限性。 2. 对称的多模态学习:通过构建用户的多模态画像,实现了用户和物品特征的对称表示,解决了特征不对称的问题。 3. 双图框架:通过融合用户-物品交互图和物品-物品语义图,有效地融合了行为和语义信息。
关键设计: 1. 递归跨模态注意力(RCA):RCA模块通过多层Transformer结构实现,每一层Transformer都用于学习不同模态之间的注意力权重,并利用这些权重来更新模态特征。 2. 对比学习目标:采用InfoNCE损失函数,最大化正样本对之间的相似度,最小化负样本对之间的相似度。 3. 图神经网络:使用Graph Convolutional Network (GCN) 在双图上进行信息传播和节点表示学习。
🖼️ 关键图片

📊 实验亮点
在四个真实世界数据集上的实验结果表明,CRANE模型在关键指标上平均提升了5%,显著优于现有的state-of-the-art基线模型。例如,在某个数据集上,CRANE的Recall@20指标提升了5.3%,NDCG@20指标提升了4.8%。此外,理论和实证分析表明CRANE具有良好的可扩展性和计算效率。
🎯 应用场景
CRANE模型可应用于各种多媒体推荐场景,例如电商平台的商品推荐、视频网站的视频推荐、音乐App的歌曲推荐等。通过更准确地捕捉用户偏好和物品特征,CRANE能够显著提升推荐系统的性能,提高用户满意度和平台收益。该研究对于提升多模态推荐系统的智能化水平具有重要意义。
📄 摘要(原文)
Multimedia recommendation systems leverage user-item interactions and multimodal information to capture user preferences, enabling more accurate and personalized recommendations. Despite notable advancements, existing approaches still face two critical limitations: first, shallow modality fusion often relies on simple concatenation, failing to exploit rich synergic intra- and inter-modal relationships; second, asymmetric feature treatment-where users are only characterized by interaction IDs while items benefit from rich multimodal content-hinders the learning of a shared semantic space. To address these issues, we propose a Cross-modal Recursive Attention Network with dual graph Embedding (CRANE). To tackle shallow fusion, we design a core Recursive Cross-Modal Attention (RCA) mechanism that iteratively refines modality features based on cross-correlations in a joint latent space, effectively capturing high-order intra- and inter-modal dependencies. For symmetric multimodal learning, we explicitly construct users' multimodal profiles by aggregating features of their interacted items. Furthermore, CRANE integrates a symmetric dual-graph framework-comprising a heterogeneous user-item interaction graph and a homogeneous item-item semantic graph-unified by a self-supervised contrastive learning objective to fuse behavioral and semantic signals. Despite these complex modeling capabilities, CRANE maintains high computational efficiency. Theoretical and empirical analyses confirm its scalability and high practical efficiency, achieving faster convergence on small datasets and superior performance ceilings on large-scale ones. Comprehensive experiments on four public real-world datasets validate an average 5% improvement in key metrics over state-of-the-art baselines.